OAG BERT
1.0.0

Bibliothèque | Papier | Mou
Nous avons publié deux versions du package OAG-BERT dans COGDL (en raison de l'expiration du téléchargement du disque Cloud Tsinghua précédent, veuillez maintenant télécharger les modèles manuellement à partir de modèles). OAG-BERT est un modèle de langue académique hétérogène qui comprend non seulement les textes académiques mais aussi les connaissances en entités hétérogènes en OAG. Rejoignez notre groupe Slack ou Google pour tout commentaire et demandes! Notre article est là.
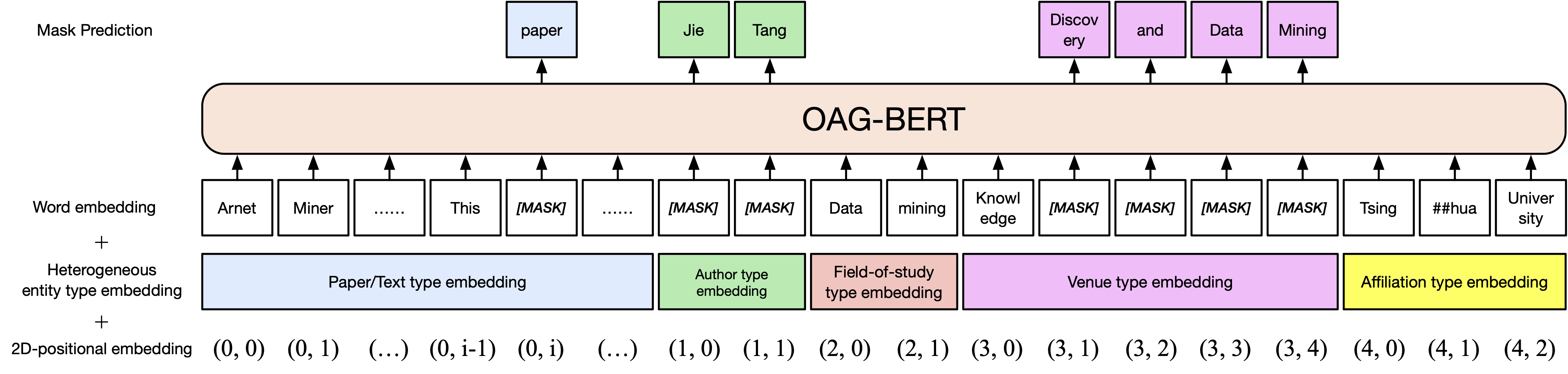
Une version de base Oag-Bert. Semblable à Scibert, nous pré-entraînons le modèle Bert sur le corpus de texte académique dans un graphique académique ouvert, y compris des titres de papier, des résumés et des corps.
L'utilisation de Oag-Bert est la même d'Ordinary Scibert ou Bert. Par exemple, vous pouvez utiliser le code suivant pour coder deux séquences de texte et récupérer leurs sorties
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )Une extension de la vanille Oag-Bert. Nous incorporons des informations sur les entités riches dans un graphique académique ouvert tel que les auteurs et le champ d'études . Ainsi, vous pouvez coder divers types d'entités dans OAG-BERT V2. Par exemple, pour coder le papier de Bert, vous pouvez utiliser le code suivant
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) Vous pouvez également utiliser certaines fonctions intégrées pour utiliser directement OAG-BERT V2, comme utiliser decode_beamsearch pour générer des entités en fonction du contexte existant. Par exemple, pour générer des concepts avec 2 jetons pour le papier Bert, exécutez le code suivant
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)OAG-BERT dépasse d'autres modèles de langue académique sur un large éventail de tâches sensibles aux entités tout en conserve ses performances sur les tâches PNL ordinaires.
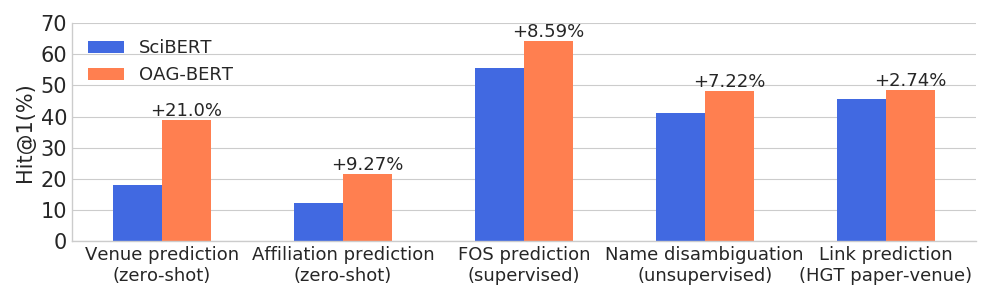
Nous publions également une autre version V2 pour les utilisateurs.
L'une est une version basée sur la génération qui peut être utilisée pour générer des textes basés sur d'autres informations. Par exemple, utilisez le code suivant pour générer automatiquement des titres de papier avec des résumés.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"En plus de cela, nous affinons le OAG-BERT pour avoir calculé la similitude du papier basé sur les tâches de désambiguïsation du nom, qui est nommée phrase-oagbert suivant la phrase-BERT. Les codes suivants démontrent un exemple d'utilisation de la phrase-oagbert pour calculer la similitude du papier.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )Cet réglage fin a été effectué sur des tâches de désambiguïsation qui nomment. Les articles écrits par les mêmes auteurs sont traités comme des paires positives et les autres comme des paires négatives. Nous échantillons des paires positives de 0,4 million et des paires négatives de 1,6 m et utilisons l'apprentissage contraint pour affiner l'OAG-BERT (version 2). Pour 50% des cas, nous n'utilisons le titre du papier que tandis que les 50% restants utilisent toutes les informations hétérogènes. Nous évaluons les performances en utilisant un rang réciproque moyen où des valeurs plus élevées indiquent de meilleurs résultats. Les performances sur les ensembles de tests sont indiquées comme ci-dessous.
| Oagbert-V2 | oagbert-v2-sim | |
|---|---|---|
| Titre | 0,349 | 0,725 |
| Titre + Résumé + Auteur + AFF + lieu | 0,355 | 0,789 |
Pour plus de détails, reportez-vous à des exemples / oagbert_metainfo.py dans Cogdl.
Nous avons également formé le Oagbert chinois pour une utilisation. Le modèle a été formé sur un corpus, y compris 44 millions de métadonnées de papier chinois, y compris le titre, le résumé, les auteurs, les affiliations, les lieux, les mots clés et les fonds . Le nouveau fonds d'entité est étendu au-delà des entités utilisées dans la version anglaise. En outre, le chinois Oagbert est formé avec le tokenizer de la phrase. Ce sont les deux principales différences entre l'Oagbert anglais et le chinois Oagbert.
Les exemples d'utilisation de l'Oagbert chinois d'origine et de la phrase-oagbert se trouvent dans des exemples / oagbert / oagbert_metainfo_zh.py et des exemples / oagbert / oagbert_metainfo_zh_sim.py. De façon similaire à la phrase anglaise-oagbert, la phrase chinoise-oagbert est affinée sur les tâches de désambiguïsation du nom pour calculer la similitude de l'intégration du papier. Les performances sont indiquées comme ci-dessous. Nous recommandons aux utilisateurs d'utiliser directement cette version si les tâches en aval n'ont pas suffisamment de données pour le réglage fin.
| oagbert-v2-zh | oagbert-v2-zh-sim | |
|---|---|---|
| Titre | 0,337 | 0,619 |
| Titre + Résumé | 0,314 | 0,682 |
Si vous le trouvez utile, veuillez nous citer dans votre travail:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


