OAG BERT
1.0.0

Библиотека | Бумага | Пролечить
Мы выпустили две версии OAG-Bert в пакете Cogdl (из-за истечения срока предыдущей загрузки облачного диска Tsinghua, пожалуйста, теперь загрузите модели вручную с Modelscope). OAG-Bert-это гетерогенная академическая языковая модель, которая не только понимает академические тексты, но и гетерогенные знания сущности в ОАГ. Присоединяйтесь к нашей группе Slack или Google для любых комментариев и запросов! Наша статья здесь.
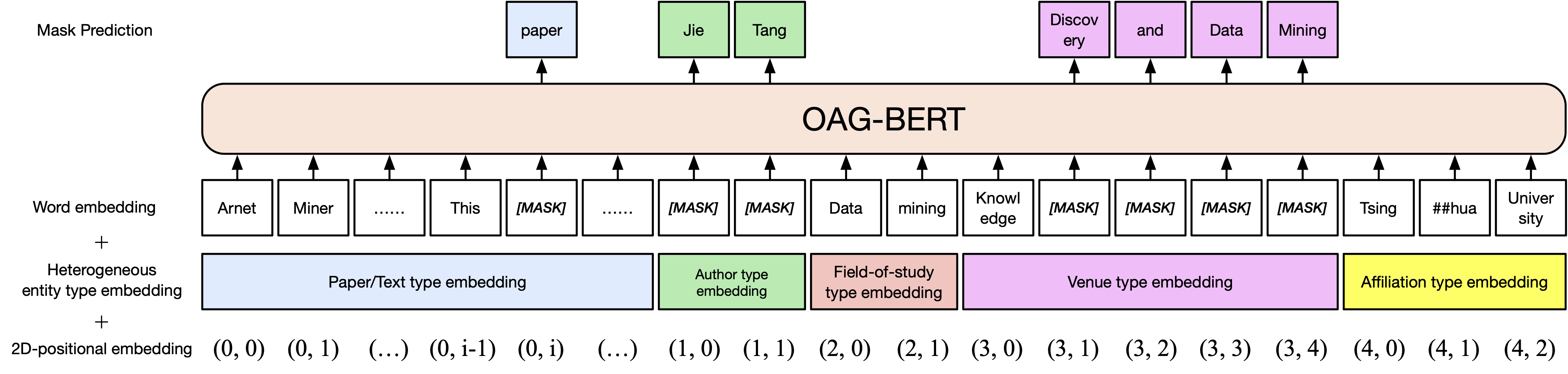
Основная версия OAG-BERT. Подобно Scibert, мы готовим модель BERT по академическому текстовому корпусу в открытом академическом графике, включая бумажные названия, рефераты и тела.
Использование OAG-BERT-это то же самое от обычного Scibert или Bert. Например, вы можете использовать следующий код для кодирования двух текстовых последовательностей и получить их выходы
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )Расширение на ванильный OAG-Bert. Мы включаем информацию о богатых организациях в открытый академический график, такой как авторы и полевые исследования . Таким образом, вы можете кодировать различные типы сущностей в OAG-BERT V2. Например, чтобы кодировать статью Берта, вы можете использовать следующий код
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) Вы также можете использовать некоторые интегрированные функции для непосредственного использования OAG-Bert V2, таких как использование decode_beamsearch для генерации объектов на основе существующего контекста. Например, чтобы генерировать концепции с 2 токенами для бумаги Bert, запустите следующий код
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)OAG-BERT превосходит другие академические языковые модели по широкому кругу задач с учетом организации, сохраняя свои результаты в обычных задачах НЛП.
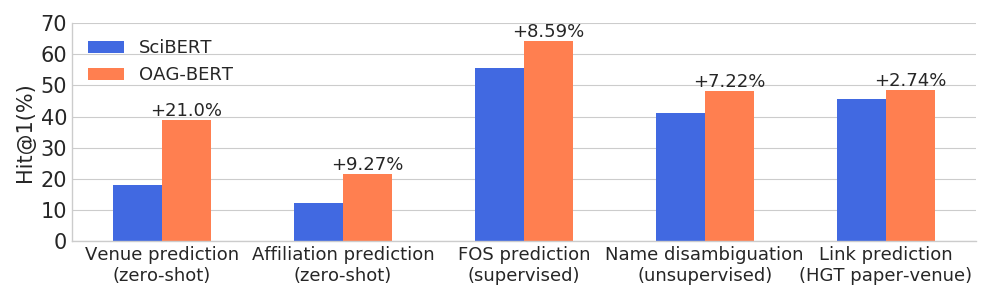
Мы также выпускаем еще две версии V2 для пользователей.
Одним из них является версия на основе поколения, которая может использоваться для генерации текстов на основе другой информации. Например, используйте следующий код для автоматического генерации бумажных названий с рефератами.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"В дополнение к этому, мы настраиваем OAG-Bert для расчета сходства бумаги на основе заданий неоднозначности имени, которое называется предложением-оагбертом после предложения-берта. Следующие коды демонстрируют пример использования предложения-оагберта для расчета сходства бумаги.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )Эта точная настройка была проведена на задачах выездки, чьи имя, название. Документы, написанные теми же авторами, рассматриваются как положительные пары, а остальные - как негативные пары. Мы выбираем 0,4 М положительные пары и 1,6-метровые отрицательные пары и используем напряженное обучение для тонкой настройки OAG-Bert (версия 2). Для 50% экземпляров мы используем только заголовок бумаги, в то время как остальные 50% используют всю гетерогенную информацию. Мы оцениваем производительность с использованием среднего взаимного ранга, где более высокие значения указывают на лучшие результаты. Производительность на тестовых наборах показана, как показано ниже.
| Оагберт-В2 | OAGBERT-V2-SIM | |
|---|---|---|
| Заголовок | 0,349 | 0,725 |
| Название+Аннотация+Автор+AFF+Место проведения | 0,355 | 0,789 |
Для получения более подробной информации см. Примеры/Oagbert_metainfo.py в Cogdl.
Мы также обучили китайского Оагберта для использования. Модель была предварительно обучена на корпусе, включая 44-метровые метаданные бумаги, включая название, абстрактные, авторы, принадлежность, места, ключевые слова и средства . Новый фонд организации выходит за рамки организаций, используемых в английской версии. Кроме того, китайский Оагберт обучается с токенизатором предложения. Это два основных различия между английским Оагбертом и китайским Оагбертом.
Примеры использования оригинального китайского оагберта и предложения-оагберта можно найти в примерах/oagbert/oagbert_metainfo_zh.py и примеров/oagbert/oagbert_metainfo_zh_sim.py. Подобно английскому приговору-оагберту, китайский предложение-оагберт точно настроен на задачи неоднозначности для расчета сходства в бумажном вкладывании. Производительность показана, как показано ниже. Мы рекомендуем пользователям непосредственно использовать эту версию, если задачи вниз по течению не имеют достаточного количества данных для точной настройки.
| Oagbert-V2-ZH | Oagbert-V2-ZH-Sim | |
|---|---|---|
| Заголовок | 0,337 | 0,619 |
| Название+Аннотация | 0,314 | 0,682 |
Если вы обнаружите, что это полезно, пожалуйста, укажите нас в своей работе:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


