OAG BERT
1.0.0

ห้องสมุด กระดาษ | หย่อน
เราเปิดตัว OAG-Bert สองเวอร์ชันในแพ็คเกจ COGDL (เนื่องจากการดาวน์โหลดดิสก์คลาวด์ Tsinghua ก่อนหน้านี้ก่อนหน้านี้โปรดดาวน์โหลดรุ่นด้วยตนเองจาก ModelsCope) OAG-BERT เป็นรูปแบบภาษาวิชาการที่หลากหลายซึ่งไม่เพียง แต่เข้าใจตำราทางวิชาการเท่านั้น เข้าร่วม Slack หรือ Google Group ของเราสำหรับความคิดเห็นและคำขอใด ๆ ! กระดาษของเราอยู่ที่นี่
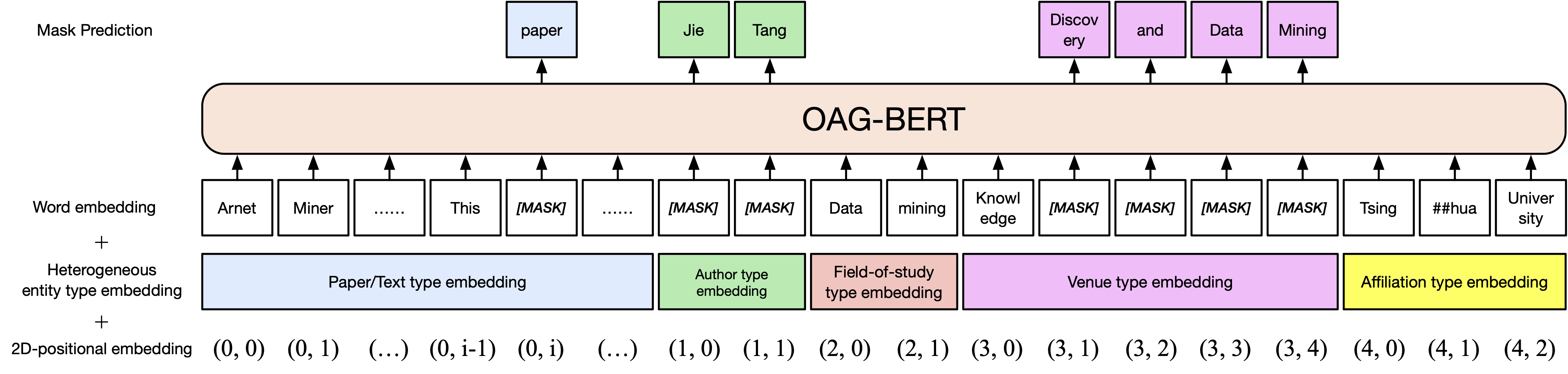
เวอร์ชันพื้นฐาน OAG-BERT เช่นเดียวกับ Scibert เราฝึกอบรมแบบจำลอง Bert บนคลังข้อความเชิงวิชาการในกราฟการศึกษาแบบเปิดรวมถึงชื่อกระดาษบทคัดย่อและร่างกาย
การใช้ OAG-BERT นั้นเหมือนกันกับ Scibert หรือ Bert ธรรมดา ตัวอย่างเช่นคุณสามารถใช้รหัสต่อไปนี้เพื่อเข้ารหัสสองลำดับข้อความและดึงเอาต์พุตของพวกเขา
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )ส่วนขยายไปยังวานิลลา OAG-BERT เรารวมข้อมูลเอนทิตีที่หลากหลายไว้ในกราฟการศึกษาแบบเปิดเช่น ผู้แต่ง และ การศึกษาด้านการศึกษา ดังนั้นคุณสามารถเข้ารหัสเอนทิตีประเภทต่าง ๆ ใน OAG-BERT V2 ตัวอย่างเช่นในการเข้ารหัสกระดาษของเบิร์ตคุณสามารถใช้รหัสต่อไปนี้
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) นอกจากนี้คุณยังสามารถใช้ฟังก์ชั่นรวมบางอย่างเพื่อใช้ OAG-BERT V2 โดยตรงเช่นการใช้ decode_beamsearch เพื่อสร้างเอนทิตีตามบริบทที่มีอยู่ ตัวอย่างเช่นในการสร้างแนวคิดด้วย 2 โทเค็นสำหรับกระดาษเบิร์ตให้เรียกใช้รหัสต่อไปนี้
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)OAG-BERT เหนือกว่ารูปแบบภาษาวิชาการอื่น ๆ ในงานที่หลากหลายที่ตระหนักถึงความหลากหลายในขณะที่ยังคงประสิทธิภาพการทำงานของงาน NLP ทั่วไป
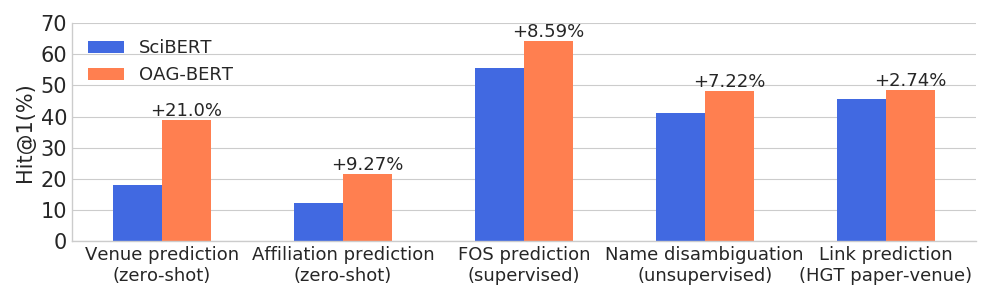
นอกจากนี้เรายังเปิดตัวเวอร์ชัน V2 อีกสองรุ่นสำหรับผู้ใช้
หนึ่งคือเวอร์ชันที่ใช้การสร้างซึ่งสามารถใช้สำหรับการสร้างข้อความตามข้อมูลอื่น ๆ ตัวอย่างเช่นใช้รหัสต่อไปนี้เพื่อสร้างชื่อกระดาษโดยอัตโนมัติด้วยบทคัดย่อ
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"นอกจากนั้นเรายังปรับแต่ง OAG-Bert สำหรับการคำนวณความคล้ายคลึงกันของกระดาษตามงานที่ไม่น่าเชื่อชื่อซึ่งได้รับการขนานนามว่าเป็นประโยค-Oagbert ต่อไปนี้ประโยค-เบิร์ต รหัสต่อไปนี้แสดงให้เห็นถึงตัวอย่างของการใช้ประโยค-Oagbert เพื่อคำนวณความคล้ายคลึงกันของกระดาษ
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )การปรับจูนนี้ดำเนินการในงาน WHOIS ซึ่งเป็นงาน disambiguation เอกสารที่เขียนโดยผู้เขียนคนเดียวกันได้รับการปฏิบัติเป็นคู่ที่เป็นบวกและส่วนที่วางเป็นคู่ลบ เราสุ่มตัวอย่างคู่บวก 0.4m และคู่ลบ 1.6 ม. และใช้การเรียนรู้ข้อ จำกัด เพื่อปรับแต่ง OAG-Bert (เวอร์ชัน 2) สำหรับอินสแตนซ์ 50% เราใช้ชื่อกระดาษเท่านั้นในขณะที่อีก 50% ใช้ข้อมูลที่ต่างกันทั้งหมด เราประเมินประสิทธิภาพโดยใช้ค่าเฉลี่ยซึ่งกันและกันซึ่งค่าที่สูงกว่าบ่งบอกผลลัพธ์ที่ดีกว่า ประสิทธิภาพในชุดทดสอบจะแสดงดังต่อไปนี้
| Oagbert-V2 | Oagbert-v2-sim | |
|---|---|---|
| ชื่อ | 0.349 | 0.725 |
| ชื่อเรื่อง+บทคัดย่อ+ผู้แต่ง+Aff+สถานที่จัดงาน | 0.355 | 0.789 |
สำหรับรายละเอียดเพิ่มเติมโปรดดูตัวอย่าง/oagbert_metainfo.py ใน cogdl
นอกจากนี้เรายังฝึกฝน Oagbert จีนเพื่อใช้ แบบจำลองนี้ได้รับการฝึกอบรมล่วงหน้าในคลังข้อมูลรวมถึงเมตาดาต้ากระดาษจีน 44M รวมถึงชื่อเรื่องนามธรรมผู้เขียนความร่วมมือสถานที่สถานที่คำหลักและ เงินทุน กองทุนเอน ทิ ตีใหม่ขยายออกไปนอกเหนือจากเอนทิตีที่ใช้ในเวอร์ชันภาษาอังกฤษ นอกจากนี้ Oagbert ชาวจีนยังได้รับการฝึกฝนด้วยโทเค็นประโยค นี่คือความแตกต่างที่สำคัญสองประการระหว่าง Oagbert ภาษาอังกฤษและ Oagbert จีน
ตัวอย่างของการใช้ Oagbert จีนดั้งเดิมและประโยค-oagbert สามารถพบได้ในตัวอย่าง/oagbert/oagbert_metainfo_zh.py และตัวอย่าง/oagbert/oagbert_metainfo_zh_sim.py ในทำนองเดียวกันกับประโยคภาษาอังกฤษ-Oagbert ประโยคภาษาจีน-Oagbert ได้รับการปรับแต่งในงาน disambiguation ชื่อสำหรับการคำนวณกระดาษที่มีความคล้ายคลึงกัน ประสิทธิภาพจะแสดงดังต่อไปนี้ เราขอแนะนำให้ผู้ใช้ใช้เวอร์ชันนี้โดยตรงหากงานดาวน์สตรีมไม่มีข้อมูลเพียงพอสำหรับการปรับแต่ง
| Oagbert-V2-ZH | oagbert-v2-zh-sim | |
|---|---|---|
| ชื่อ | 0.337 | 0.619 |
| ชื่อเรื่อง+บทคัดย่อ | 0.314 | 0.682 |
หากคุณพบว่ามีประโยชน์โปรดอ้างอิงเราในงานของคุณ:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


