OAG BERT
1.0.0

도서관 | 종이 | 느슨하게
CogDL 패키지에서 OAG-Bert의 두 가지 버전을 출시했습니다 (이전 Tsinghua Cloud Disk 다운로드가 만료되어 이제 ModelScope에서 모델을 수동으로 다운로드하십시오). OAG-Bert는 학업 텍스트뿐만 아니라 OAG의 이기종 기업 지식을 이해하는 이질적인 실체 향상 학업 언어 모델입니다. 의견과 요청에 따라 슬랙 또는 Google 그룹에 가입하십시오! 우리 논문이 여기 있습니다.
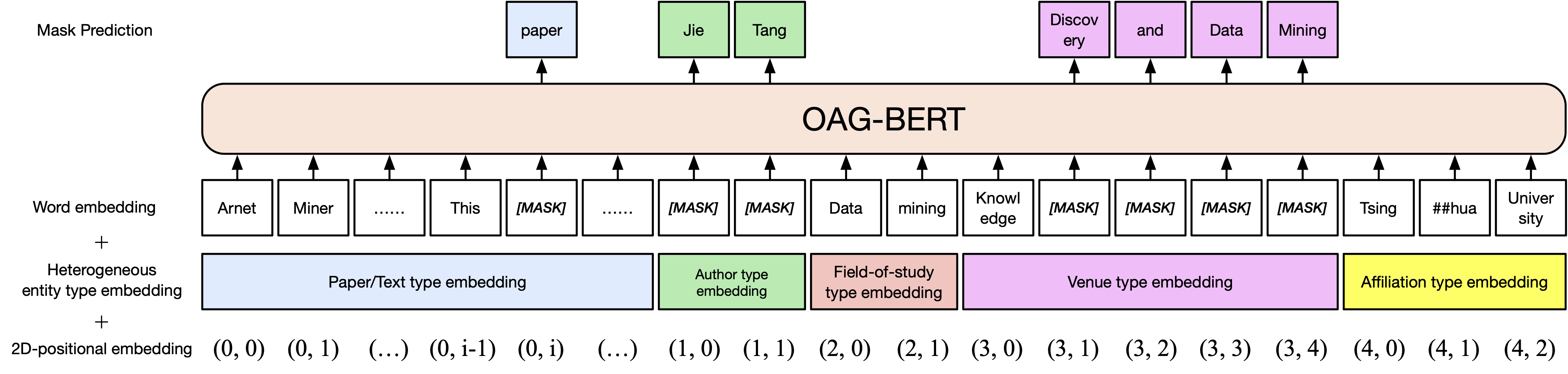
기본 버전 OAG-BERT. Scibert와 마찬가지로, 우리는 종이 제목, 초록 및 신체를 포함한 오픈 아카데믹 그래프에서 학술 텍스트 코퍼스의 Bert 모델을 사전 훈련합니다.
OAG-Bert의 사용은 일반 스키버 또는 버트와 동일합니다. 예를 들어 다음 코드를 사용하여 두 텍스트 시퀀스를 인코딩하고 출력을 검색 할 수 있습니다.
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )바닐라 OAG-Bert의 확장. 우리는 저자 및 연구 분야 와 같은 공개 학술 그래프에 풍부한 엔티티 정보를 통합합니다. 따라서 OAG-Bert V2에서 다양한 유형의 엔티티를 인코딩 할 수 있습니다. 예를 들어, Bert의 용지를 인코딩하려면 다음 코드를 사용할 수 있습니다.
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) decode_beamsearch 사용하여 기존 컨텍스트를 기반으로 엔티티를 생성하는 등 일부 통합 기능을 사용하여 OAG-Bert V2를 직접 사용할 수도 있습니다. 예를 들어, 버트 용지에 2 개의 토큰이있는 개념을 생성하려면 다음 코드를 실행하십시오.
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)OAG-Bert는 광범위한 실체 인식 작업에서 다른 학업 언어 모델을 능가하는 동시에 일반 NLP 작업에서 성과를 유지합니다.
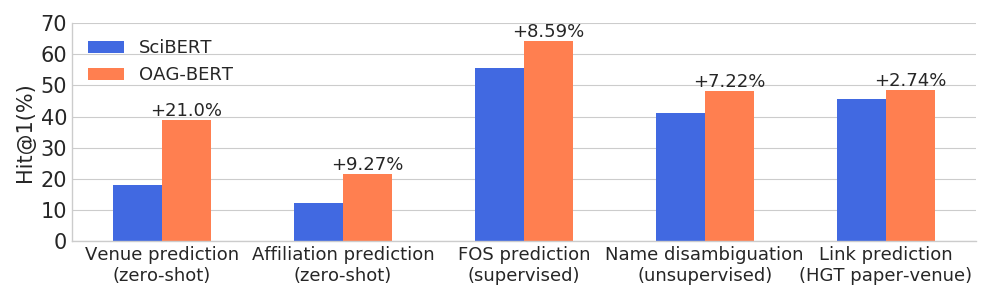
또한 사용자를 위해 또 다른 두 V2 버전을 출시합니다.
하나는 다른 정보를 기반으로 텍스트를 생성하는 데 사용할 수있는 세대 기반 버전입니다. 예를 들어, 다음 코드를 사용하여 초록이있는 종이 제목을 자동으로 생성하십시오.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"그 외에도, 우리는 이름 명단 작업을 기반으로 종이 유사성을 계산하기위한 OAG-Bert를 미세 조정하는데, 이는 문장에 따라 문장-오그 베르트로 명명됩니다. 다음 코드는 문자 유사성을 계산하기 위해 문장-호 버트를 사용하는 예를 보여줍니다.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )이 미세 조정은 Whoiswo Name Disambiguation 과제에 대해 수행되었습니다. 동일한 저자가 쓴 논문은 양의 쌍으로 취급되고 나머지는 음의 쌍으로 취급됩니다. 우리는 0.4m 양의 쌍과 1.6m 네거티브 쌍을 샘플링하고 구속 학습을 사용하여 OAG-Bert (버전 2)를 미세 조정합니다. 50% 인스턴스의 경우 종이 제목 만 사용하지만 다른 50%는 모든 이기종 정보를 사용합니다. 더 높은 값이 더 나은 결과를 나타내는 평균 상호 순위를 사용하여 성능을 평가합니다. 테스트 세트의 성능은 다음과 같습니다.
| Oagbert-V2 | Oagbert-V2-SIM | |
|---|---|---|
| 제목 | 0.349 | 0.725 |
| 제목+초록+저자+aff+장소 | 0.355 | 0.789 |
자세한 내용은 Cogdl의 예제/oagbert_metainfo.py를 참조하십시오.
우리는 또한 중국 Oagbert를 사용하기 위해 훈련했습니다. 이 모델은 제목, 초록, 저자, 제휴, 장소, 키워드 및 자금을 포함한 44m 중국 종이 메타 데이터를 포함한 코퍼스에서 미리 훈련되었습니다. 새로운 엔티티 펀드는 영어 버전에 사용되는 엔티티를 넘어 확장됩니다. 게다가, 중국 Oagbert는 문장 토큰 화기로 훈련을 받았습니다. 이것들은 영어 Oagbert와 Chinese Oagbert의 두 가지 주요 차이점입니다.
원래 중국어 Oagbert와 문장 -oagbert를 사용하는 예는 예/Oagbert/oagbert_metainfo_zh.py 및 examples/oagbert/oagbert_metainfo_zh_sim.py에서 찾을 수 있습니다. 영국 문장-오그 베르트와 마찬가지로, 중국 문장-오그 베르트는 유사성을 포함시키는 종이를 계산하기위한 이름의 명확한 비판 작업에 미세 조정됩니다. 성능은 다음과 같이 표시됩니다. 다운 스트림 작업에 미세 조정을위한 데이터가 충분하지 않은 경우 사용자는이 버전을 직접 사용하는 것이 좋습니다.
| Oagbert-V2-ZH | Oagbert-v2-zh-sim | |
|---|---|---|
| 제목 | 0.337 | 0.619 |
| 제목+초록 | 0.314 | 0.682 |
유용하다고 생각되면 작업에서 우리를 인용하십시오.
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


