unify learning paradigms
1.0.0
想獲得預算有限的更好模型嗎?你在正確的地方
pip install text-denoising
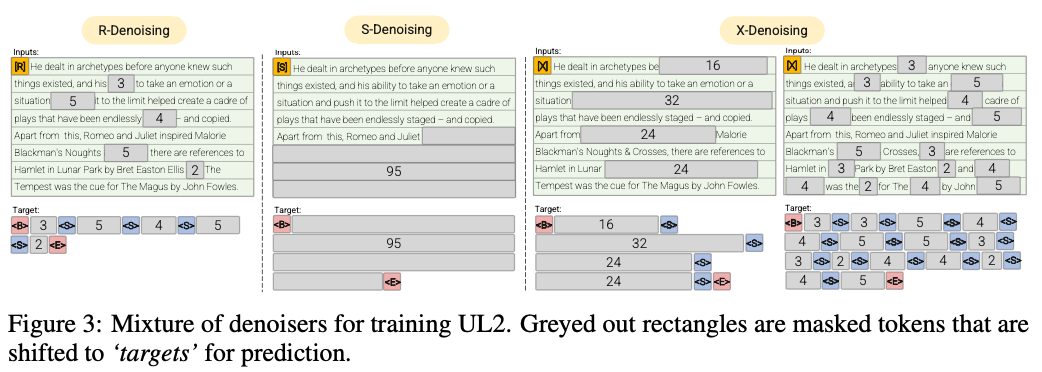
r-denoiser(μ= 3,r = 0.15,n)∪(μ= 8,r = 0.15,n)
常規的降級是Raffel等人引入的標準跨度腐敗。 (2019年),使用2到5個令牌作為跨度長度,掩蓋了約15%的輸入令牌
s-denoiser(μ= l/4,r = 0.25,1)
在構架輸入到目標任務時,我們會觀察到嚴格的順序順序的特定案例,即
X-denoiser(μ= 3,r = 0.5,n)∪(μ= 8,r = 0.5,n)∪(μ= 64,r = 0.15,n)∪(μ= 64,r = 0.5,n)
deNoising的極端版本必須在其中恢復輸入的大部分部分,鑑於其中一個小到中等的部分。這模擬了一個情況,即模型需要從內存中產生長期目標的情況,並具有相對有限的信息。為此,我們選擇包括具有侵略性denoising的示例,其中大約50%的輸入序列被掩蓋了
2022論文:超越規律,具有0.1%的額外計算
我們顯示大約2倍的計算儲蓄率
定期降級,從而將噪聲採樣為跨度,用哨兵代幣取代。這也是Raffel等人使用的標準跨度腐敗任務。 (2019)。跨度通常以平均3的平均值和15%的腐敗率進行均勻採樣。
極端的denoising在很大一部分原始文本或本質上很長的噪聲增加到相對“極端”的數量。跨度通常以平均長度為32或高達50%的腐敗率均勻地採樣。
順序的denoising,從文本的開頭到文本中隨機採樣點,噪聲總是被採樣。這也稱為前綴目標(不要與架構混淆)。
此存儲庫將僅僅是為了陪同這項任務,UL2對我的喜好來說太複雜了
50%的前綴,長達25%(極端)跨度腐敗,25%的常規跨度腐敗非常簡單有效
在pythia json.zst文件上運行3090的MT5編碼器
pip install text-denoising
python examples/pretrain_example.py
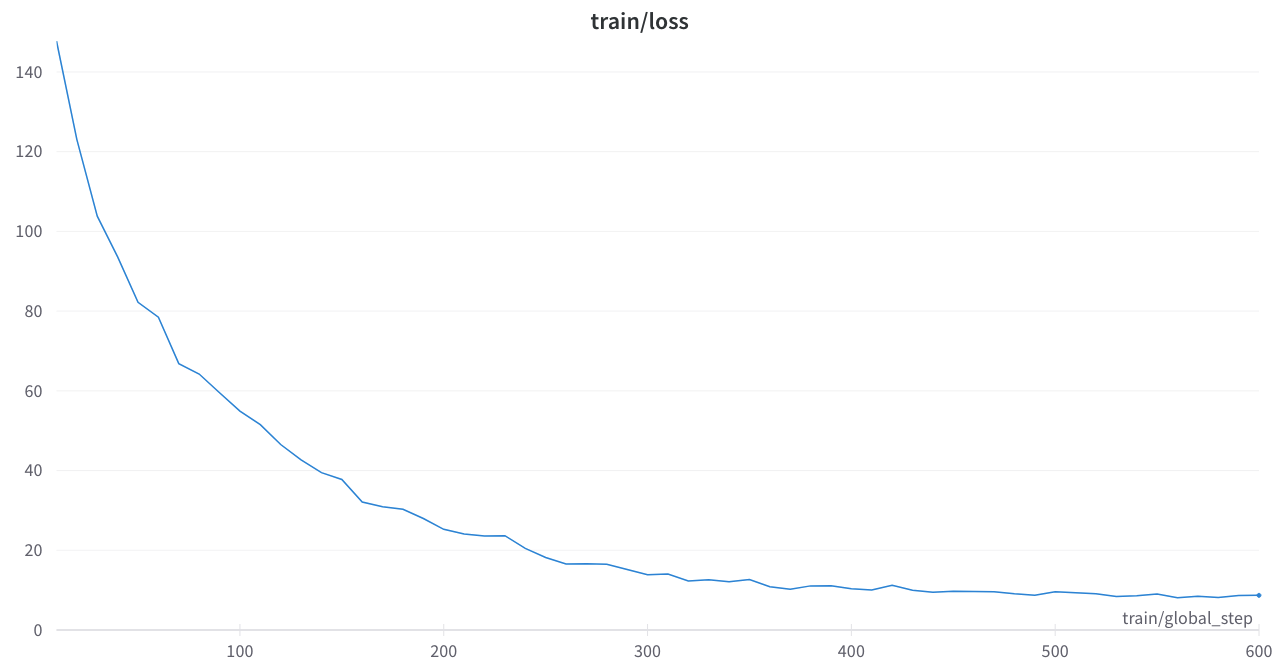
訓練損失是穩定的,沒有奇怪的尖峰
核心論文
超越縮放定律具有0.1%的額外計算
統一語言學習範式
在擁抱面變壓器或python代碼中的T5噪聲掩蔽的工具
奧斯陸:被低估的,一些整潔和文檔,這將是一個非常有用的工具
t5_pretraining.py
本節的啟發很大
亞馬遜科學:Python的標籤意識鑒定
FairSeq:Span_mask_tokens_dataset.py


