unify learning paradigms
1.0.0
¿Quiere obtener un mejor modelo con presupuestos limitados? Estás en el lugar correcto
pip install text-denoising
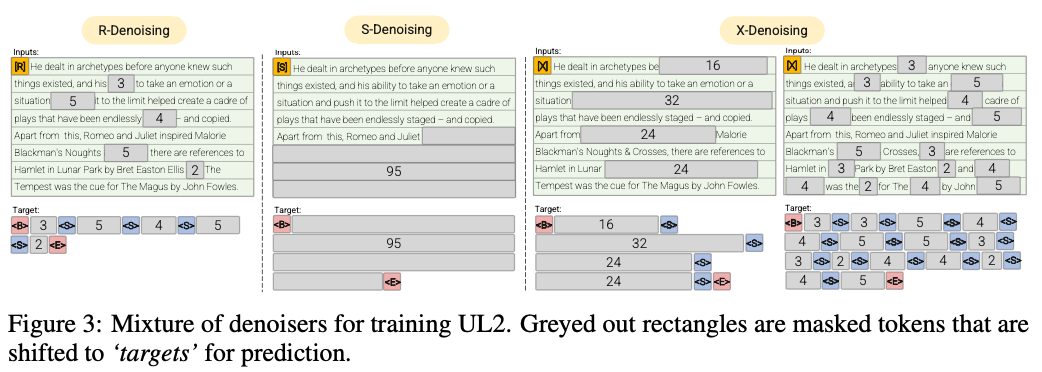
R-Denoiser (μ = 3, R = 0.15, N) ∪ (μ = 8, R = 0.15, N)
La renovación regular es la corrupción estándar del tramo introducido en Raffel et al. (2019) que utiliza un rango de 2 a 5 tokens como longitud del tramo, que enmascara aproximadamente el 15% de los tokens de entrada
S-denoiser (μ = l/4, r = 0.25,1)
Un caso específico de renovación donde observamos un orden secuencial estricto al enmarcar la tarea de entradas a objetivos, es decir, modelado de lenguaje de prefijo
X-Denoiser (μ = 3, R = 0.5, N) ∪ (μ = 8, R = 0.5, N) ∪ (μ = 64, R = 0.15, N) ∪ (μ = 64, R = 0.5, N)
Una versión extrema de Denoising donde el modelo debe recuperar una gran parte de la entrada, dada una parte pequeña a moderada de ella. Esto simula una situación en la que un modelo necesita generar un objetivo largo a partir de una memoria con información relativamente limitada. Para hacerlo, optamos por incluir ejemplos con renovación agresiva donde aproximadamente el 50% de la secuencia de entrada está enmascarada
2022 documentos: trascendiendo las leyes de escala con 0.1% de cómputo adicional
Mostramos una tasa de ahorro computacional de aproximadamente 2x
Denosing regular por la cual el ruido se muestrean como tramos, reemplazados por tokens centinela. Esta es también la tarea de corrupción del tramo estándar utilizada en Raffel et al. (2019). Los tramos generalmente se muestrean uniformemente con una media de 3 y una tasa de corrupción del 15%.
Denosificación extrema mediante la cual el ruido se incrementa a cantidades relativamente 'extremas' en un gran porcentaje del texto original o en la naturaleza muy larga. Los tramos generalmente se muestrean uniformemente con una longitud media de 32 o una tasa de corrupción de hasta el 50%.
Denosing secuencial por la cual el ruido siempre se muestrean desde el inicio del texto hasta un punto muestreado al azar en el texto. Esto también se conoce como el objetivo prefixlM (no debe confundirse con la arquitectura).
Este repositorio solo apuntará a acompañar esta tarea, UL2 es demasiado complicado para mis gustos
50% de prefixlm, 25% largo (extremo) La corrupción del tramo y el 25% de corrupción del tramo regular para ser bastante simple y eficiente
Ejecute un codificador MT5 previamente en 3090 en archivos Pythia JSON.ZST
pip install text-denoising
python examples/pretrain_example.py
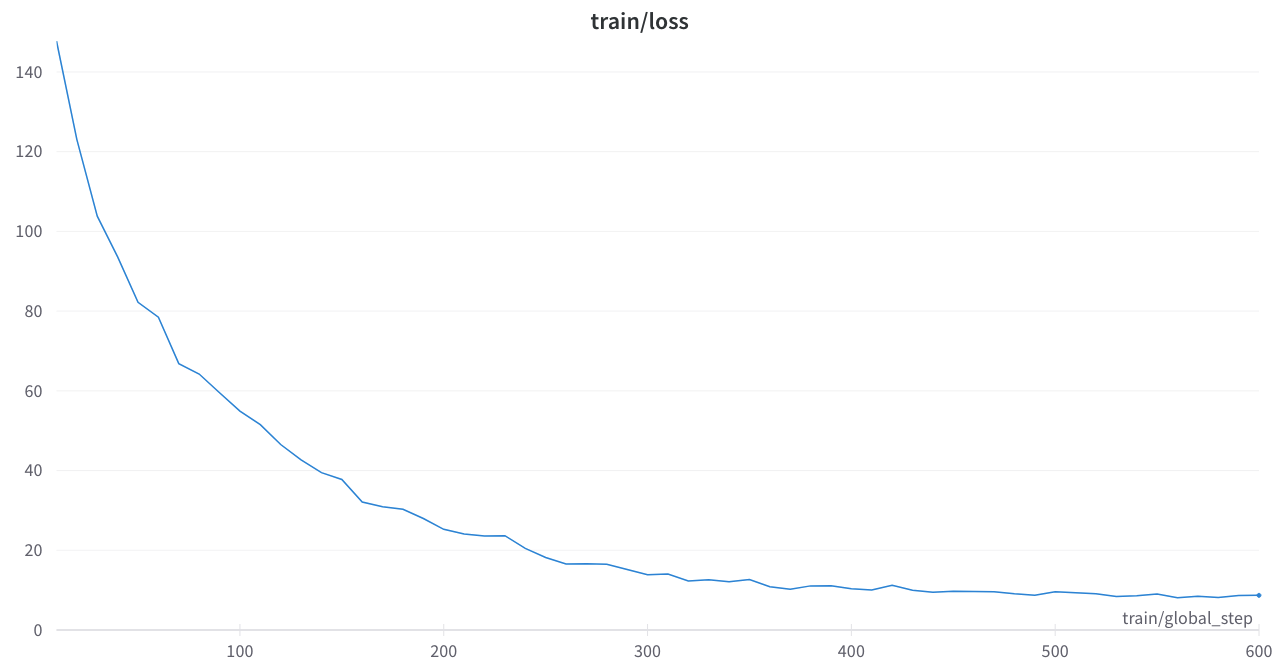
La pérdida de entrenamiento era estable y no hay picos extraños
Papeles centrales
Trascender las leyes de escala con 0.1% de cómputo adicional
Unificar paradigmas de aprendizaje de idiomas
Implementos del enmascaramiento de ruido T5 en los transformadores de Huggingface o el código de Python
OSLO: Muy subestimado, algo ordenado y documentación, esta será una herramienta muy útil
t5_preetraining.py
Muy inspirado en esta sección
Amazon Science: Etiqueta consciente del pretrén en Python
Fairseq: span_mask_tokens_dataset.py


