unify learning paradigms
1.0.0
Хотите получить лучшую модель с ограниченными бюджетами? Вы находитесь в нужном месте
pip install text-denoising
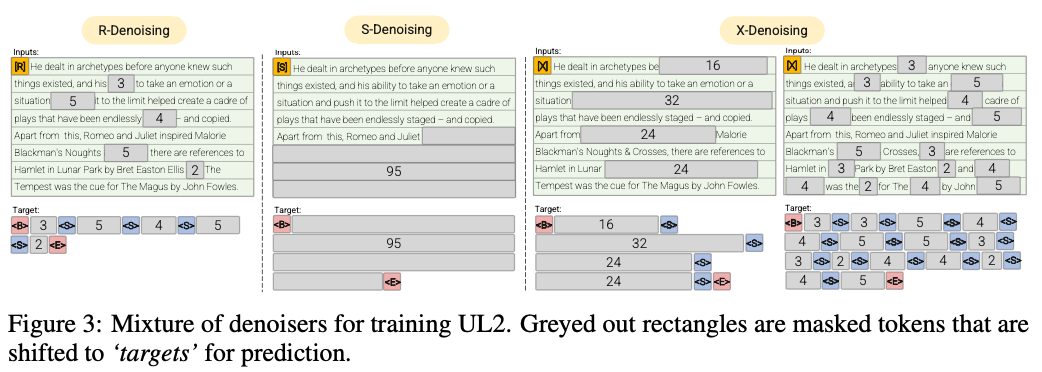
R-Denoiser (μ = 3, R = 0,15, N) ∪ (μ = 8, r = 0,15, n)
Регулярным денированием является стандартная коррупция пролета, введенную в Raffel et al. (2019), который использует диапазон от 2 до 5 токенов в качестве длины пролета, которая маскирует около 15% входных токенов
S-Denoiser (μ = L/4, R = 0,25,1)
Конкретный случай д оброэзации, когда мы соблюдаем строгий последовательный порядок при создании задачи входов к целевым, т.е.
X-Denoiser (μ = 3, R = 0,5, N) ∪ (μ = 8, R = 0,5, N) ∪ (μ = 64, r = 0,15, n) ∪ (μ = 64, r = 0,5, n)
Экстремальная версия денирования, где модель должна восстановить большую часть ввода, учитывая небольшую или умеренную ее часть. Это имитирует ситуацию, когда модель должна генерировать длинную цель из памяти с относительно ограниченной информацией. Для этого мы предпочитаем включать примеры с агрессивным денированием, где примерно 50% входной последовательности маскируется
2022 Документы: Защиты масштабирования преобразования с помощью 0,1% дополнительно вычисляют
Мы показываем приблизительно 2 -кратную вычислительную сберегательную скорость
Регулярное денирование, в результате чего шум отбирается в виде пролетов, заменяется токенами Sentinel. Это также стандартная задача коррупции пролета, используемая в Raffel et al. (2019). Пролеты, как правило, равномерно отображаются со средним значением 3 и скоростью коррупции 15%.
Экстремальное денирование, в результате чего шум увеличивается до относительно «крайних» сумм либо в огромном проценте от исходного текста, либо очень долгой по своей природе. Пролеты, как правило, равномерно отображаются со средней длиной 32 или скоростью коррупции до 50%.
Последовательное денирование, в результате которого шум всегда отображается из начала текста до случайно отобранной точки в тексте. Это также известно как объектив Prefixlm (не путать с архитектурой).
Это репо будет просто нацелено на сопровождение этой задачи, UL2 слишком сложна для моего вкуса
50% Prefixlm, 25% длиной (экстремальная) коррупция пролета и 25% обычная коррупция пролета, чтобы быть довольно простой и эффективной
Запустите предварительную подготовку энкодера MT5 на 3090 на файлах pythia json.zst
pip install text-denoising
python examples/pretrain_example.py
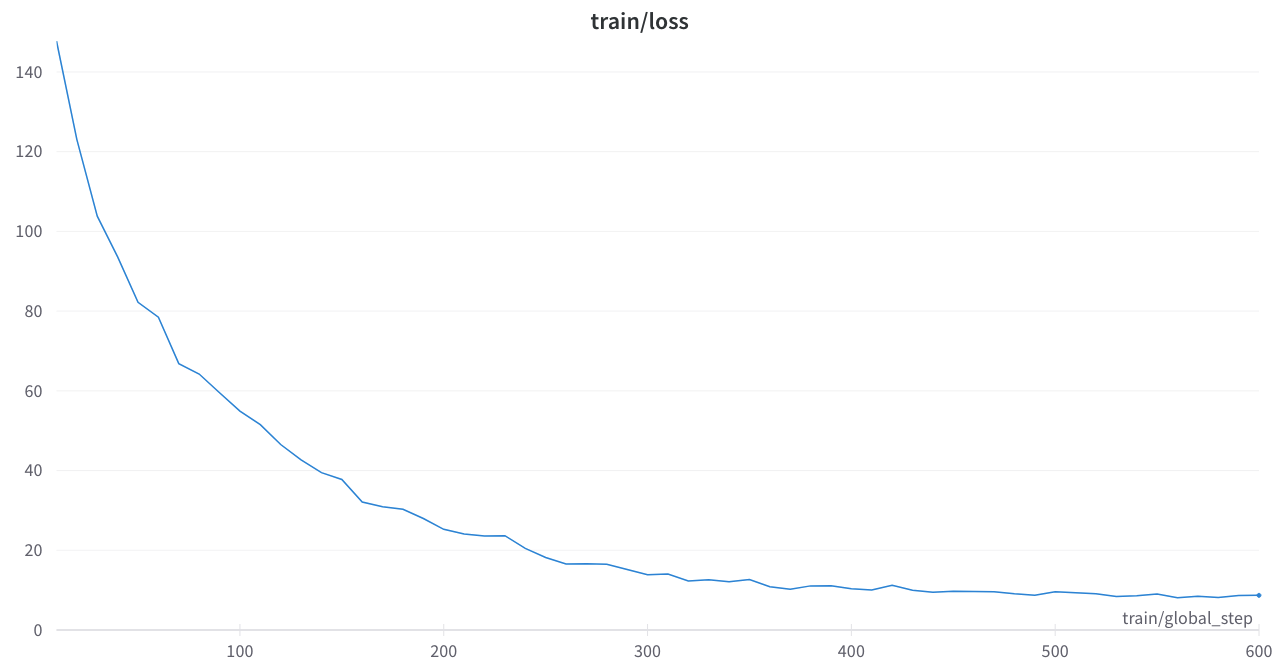
Потеря тренировки была стабильной, и никаких странных шипов
Основные документы
Преодоление законов масштабирования с дополнительным вычислением 0,1%
Объединение языковых парадигм обучения
Реализации маскировки шума T5 в трансформаторах HuggingChingface или коде Python
Осло: Очень недооцененный, некоторая аккуратная и документация, это будет очень полезный инструмент
t5_pretring.py
Сильно вдохновлен этим разделом
Amazon Science: лейбл осведомлен о предварительном доле в Python
Fairseq: span_mask_tokens_dataset.py


