unify learning paradigms
1.0.0
Vous voulez obtenir un meilleur modèle avec des budgets limités? Tu es au bon endroit
pip install text-denoising
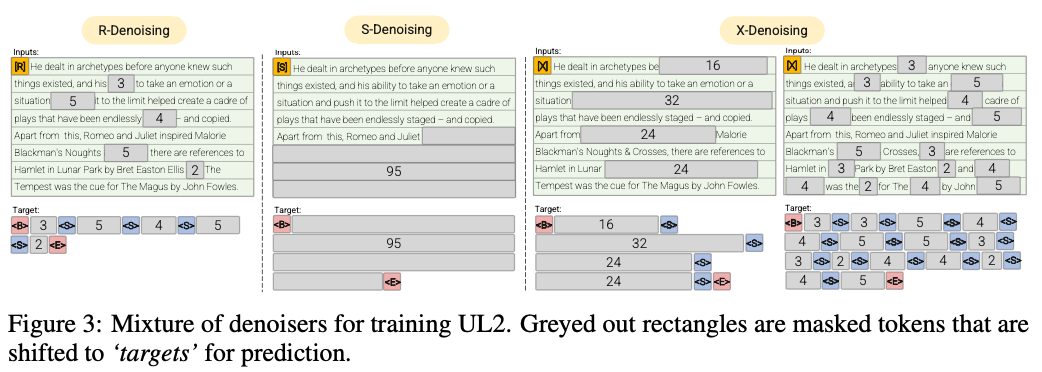
R-Denoir (μ = 3, r = 0,15, n) ∪ (μ = 8, r = 0,15, n)
Le débroussage régulier est la corruption de la portée standard introduite dans Raffel et al. (2019) qui utilise une plage de 2 à 5 jetons comme longueur de portée, qui masque environ 15% des jetons d'entrée
S-denoiseur (μ = l / 4, r = 0,25,1)
Un cas spécifique de débroussage où nous observons un ordre séquentiel strict lors de l'encadrement de la tâche des entrées à cible, c'est-à-dire, la modélisation du langage préfixe
X-Denoir (μ = 3, r = 0,5, n) ∪ (μ = 8, r = 0,5, n) ∪ (μ = 64, r = 0,15, n) ∪ (μ = 64, r = 0,5, n)
Une version extrême du débroussage où le modèle doit récupérer une grande partie de l'entrée, étant donné une partie petite à modérée de celle-ci. Cela simule une situation dans laquelle un modèle doit générer une longue cible à partir d'une mémoire avec des informations relativement limitées. Pour ce faire, nous choisissons d'inclure des exemples avec un déniisation agressive où environ 50% de la séquence d'entrée est masquée
2022 Documents: Transcender les lois de mise à l'échelle avec 0,1% de calcul supplémentaire
Nous montrons un taux d'épargne informatique d'environ 2x
Le débroussage régulier par lequel le bruit est échantillonné sous forme de portées, remplacés par des jetons sentinelles. Il s'agit également de la tâche de corruption standard utilisée dans Raffel et al. (2019). Les portées sont généralement uniformément échantillonnées avec une moyenne de 3 et un taux de corruption de 15%.
Le débraillage extrême par lequel le bruit est augmenté à des quantités relativement «extrêmes» dans un énorme pourcentage du texte d'origine ou à la nature très longue. Les portées sont généralement uniformément échantillonnées avec une longueur moyenne de 32 ou un taux de corruption allant jusqu'à 50%.
Le débraillage séquentiel par lequel le bruit est toujours échantillonné du début du texte à un point échantillonné au hasard dans le texte. Ceci est également connu comme l'objectif préfixlm (à ne pas confondre avec l'architecture).
Ce repo visera simplement l'accompolie à la place, UL2 est beaucoup trop compliqué à mon goût
50% préfixlm, 25% de long (extrême) corruption et 25% de corruption régulière pour être assez simple et efficace
Exécutez un encodeur MT5 pré-formation sur 3090 sur des fichiers pythia json.zst
pip install text-denoising
python examples/pretrain_example.py
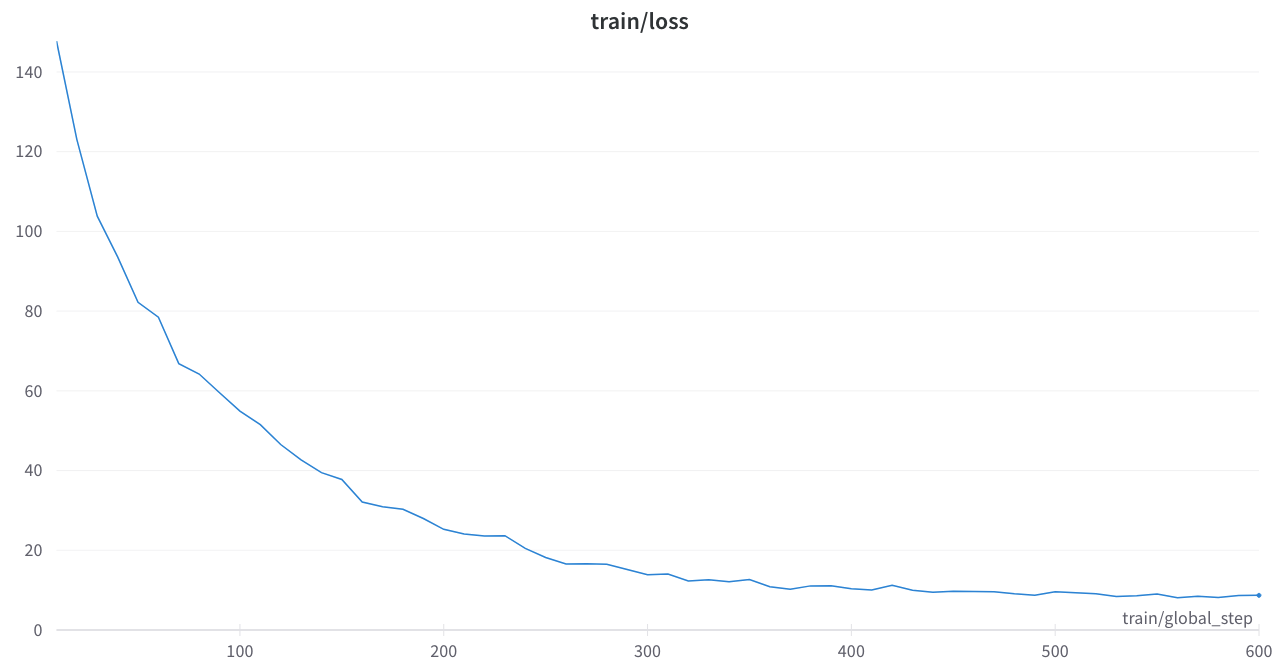
La perte de formation était stable et pas de pointes étranges
Articles de base
Transcendant les lois à l'échelle avec 0,1% de calcul supplémentaire
Paradigmes d'apprentissage des langues unificatrices
Implementations de masquage du bruit T5 dans les transformateurs de câlins ou le code Python
OSLO: Très sous-estimé, certains bien rangés et la documentation, ce sera un outil très utile
t5_pretraining.py
Fortement inspiré de cette section
Amazon Science: étiquette consciente de prétraitement dans Python
FAIRSEQ: SPAN_MASK_TOKENS_DATASET.PY


