unify learning paradigms
1.0.0
Deseja obter um modelo melhor com orçamentos limitados? Você está no lugar certo
pip install text-denoising
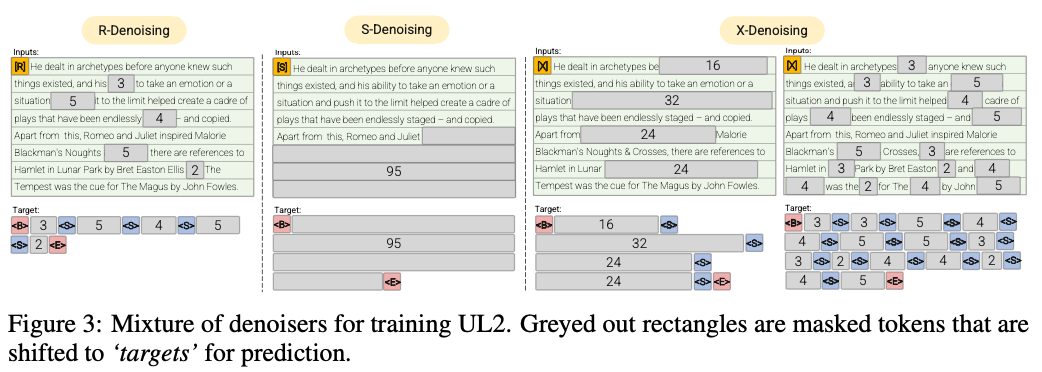
R-denoiser (μ = 3, r = 0,15, n) ∪ (μ = 8, r = 0,15, n)
O denoising regular é a corrupção padrão de extensão introduzida em Raffel et al. (2019) que usa um intervalo de 2 a 5 tokens como comprimento do span, que mascara cerca de 15% dos tokens de entrada
S-denoiser (μ = l/4, r = 0,25,1)
Um caso específico de denoising, onde observamos uma ordem seqüencial estrita ao enquadrar a tarefa de entrada para alvo, ou seja, modelagem de idiomas de prefixo
X-denoiser (μ = 3, r = 0,5, n) ∪ (μ = 8, r = 0,5, n) ∪ (μ = 64, r = 0,15, n) ∪ (μ = 64, r = 0,5, n)
Uma versão extrema do denoising, onde o modelo deve recuperar uma grande parte da entrada, dada uma parte pequena a moderada. Isso simula uma situação em que um modelo precisa gerar alvo longo a partir de uma memória com informações relativamente limitadas. Para fazer isso, optamos por incluir exemplos com denoising agressivo, onde aproximadamente 50% da sequência de entrada é mascarada
2022 Documentos: transcendendo leis de escala com computação extra 0,1%
Mostramos uma taxa de economia computacional de aproximadamente 2x
Denoising regular, pelo qual o ruído é amostrado como vãos, substituído por tokens Sentinel. Esta também é a tarefa de corrupção de extensão padrão usada em Raffel et al. (2019). Os vãos são tipicamente amostrados uniformemente com uma média de 3 e uma taxa de corrupção de 15%.
Denoramento extremo pelo qual o ruído é aumentado para quantidades relativamente "extremas" em uma porcentagem enorme do texto original ou por natureza muito longa. Os vãos são tipicamente amostrados uniformemente com um comprimento médio de 32 ou uma taxa de corrupção de até 50%.
Denoising seqüencial pelo qual o ruído é sempre amostrado desde o início do texto até um ponto amostrado aleatoriamente no texto. Isso também é conhecido como objetivo prefixlm (não deve ser confundido com a arquitetura).
Este repo terá como objetivo acompanhar essa tarefa, o UL2 é muito complicado para o meu gosto
Prefixlm de 50%, 25% de corrupção (extrema) de extensão e corrupção regular de 25% para ser bastante simples e eficiente
Execute um codificador MT5 pré -treinamento em 3090 em arquivos pythia json.zst
pip install text-denoising
python examples/pretrain_example.py
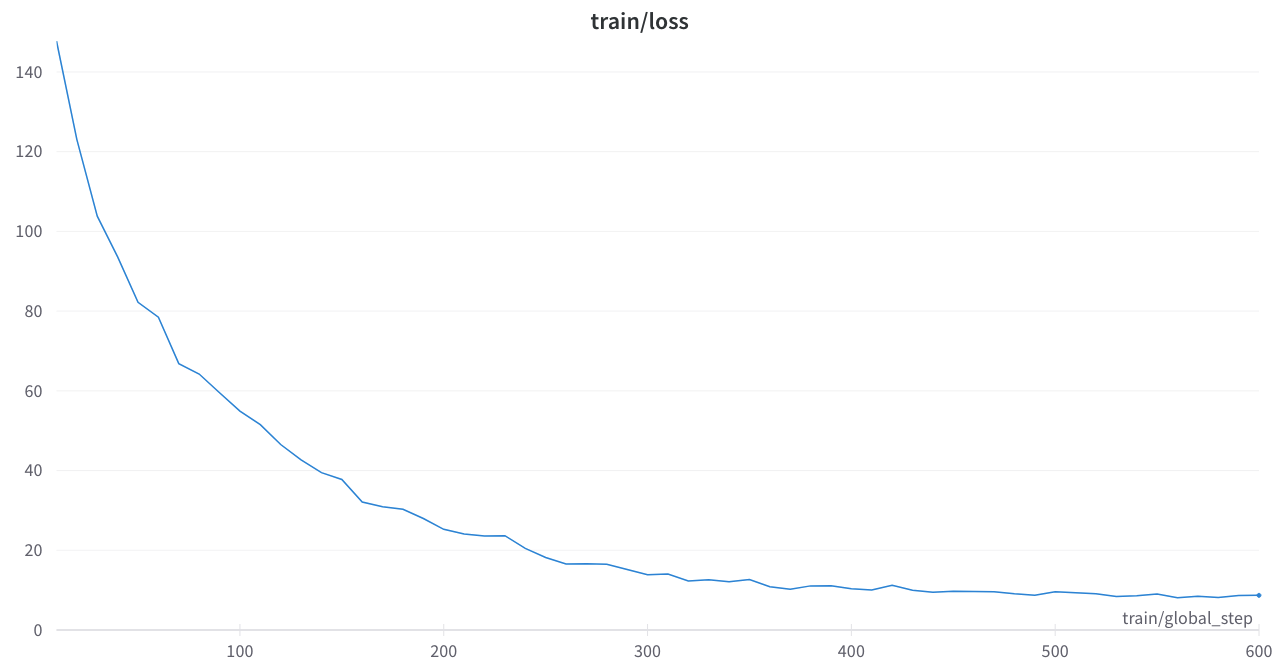
A perda de treinamento foi estável e sem picos estranhos
Papéis principais
Transcender leis de escala com computação extra 0,1%
Unificar paradigmas de aprendizado de idiomas
Implementos de máscara de ruído T5 em transformadores de huggingface ou código python
Oslo: muito subestimado, alguma arrumação e documentação, essa será uma ferramenta muito útil
T5_Pretraining.py
Fortemente inspirado nesta seção
Amazon Science: Rótulo Ciente do Pré -Trein em Python
Fairseq: SPAN_MASK_TOKENS_Dataset.py


