unify learning paradigms
1.0.0
Möchten Sie ein besseres Modell mit begrenzten Budgets erhalten? Sie sind am richtigen Ort
pip install text-denoising
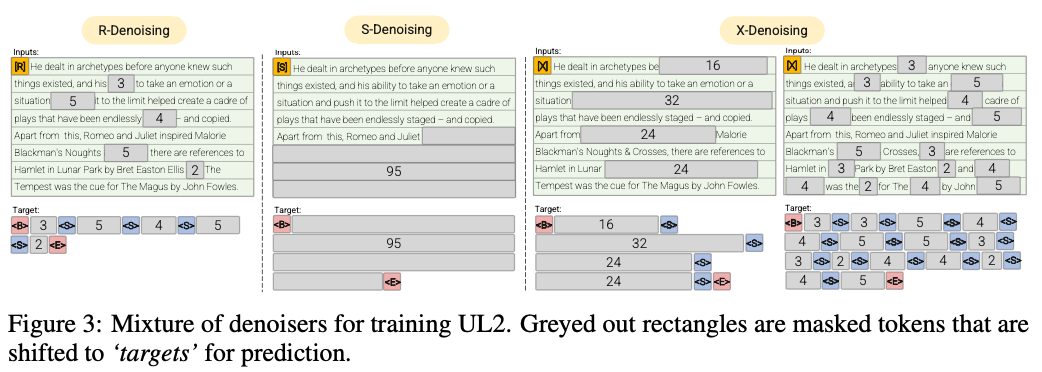
R-Denoiser (μ = 3, r = 0,15, n) ∪ (μ = 8, r = 0,15, n)
Die regelmäßige Beenoisierung ist die in Raffel et al. (2019), der einen Bereich von 2 bis 5 Token als Spannweite verwendet, die etwa 15% der Eingangs -Token maskiert
S-Denoiser (μ = L/4, r = 0,25,1)
Ein spezifischer Fall von Denoising, bei dem wir eine strenge sequentielle Reihenfolge beobachten
X-Denoiser (μ = 3, r = 0,5, n) ∪ (μ = 8, r = 0,5, n) ∪ (μ = 64, r = 0,15, n) ∪ (μ = 64, r = 0,5, n)
Eine extreme Version von Denoising, bei der das Modell einen großen Teil der Eingabe wiederherstellen muss, wenn ein kleiner bis moderates Teil davon ist. Dies simuliert eine Situation, in der ein Modell ein langes Ziel aus einem Speicher mit relativ begrenzten Informationen generieren muss. Dazu entscheiden wir uns dafür, Beispiele mit aggressivem Beenosing aufzunehmen, bei denen ungefähr 50% der Eingangssequenz maskiert sind
2022 Papiere: Überschreitung der Skalierungsgesetze mit 0,1% zusätzlicher Berechnung
Wir zeigen eine ca. 2x -Rechensparungsrate
Regelmäßige Denoising, wobei das Geräusch als Spannweiten abgetastet wird, ersetzt durch Sentinel -Token. Dies ist auch die in Raffel et al. (2019). Spannweiten werden typischerweise gleichmäßig mit einem Mittelwert von 3 und einer Korruptionsrate von 15%bezeichnet.
Extreme Denoisierung, wobei der Lärm entweder in einem riesigen Prozentsatz des ursprünglichen Textes auf relativ "extreme" Beträge erhöht wird oder sehr lang in der Natur ist. Die Spannweiten werden typischerweise gleichmäßig mit einer mittleren Länge von 32 oder einer Korruptionsrate von bis zu 50%abgetastet.
Sequentielle Denoisierung, wobei das Rauschen immer vom Beginn des Textes zu einem zufällig abgetasteten Punkt im Text abgetastet wird. Dies wird auch als Präfixlm -Ziel bezeichnet (nicht mit der Architektur verwechselt).
Dieses Repo wird nur darauf abzielen, diese Aufgabe zu begleiten, UL2 ist für meine Vorlieben viel zu kompliziert
50% Präfixlm, 25% lang (extrem) Korruption und 25% regelmäßige Korruption, um recht einfach und effizient zu sein
Führen Sie einen MT5 -Encoder -Vorbau auf 3090 auf Pythia json.zst -Dateien aus
pip install text-denoising
python examples/pretrain_example.py
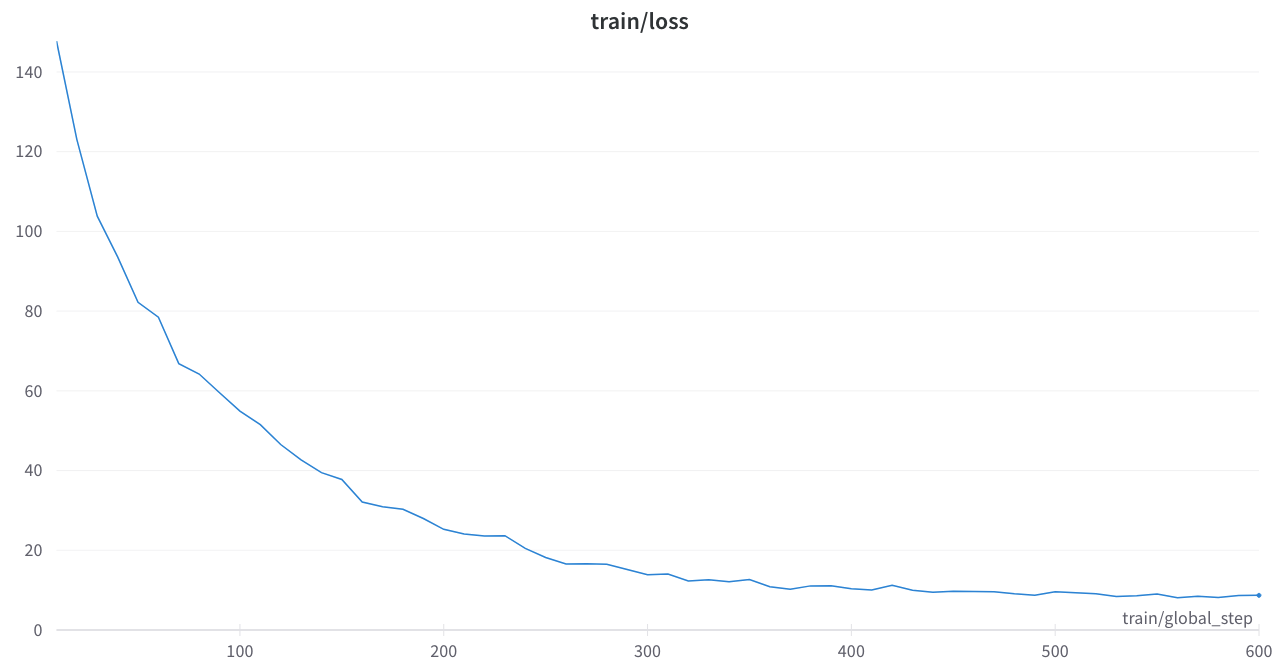
Der Trainingsverlust war stabil und keine seltsamen Spikes
Kernpapiere
Überschreitung der Skalierungsgesetze mit 0,1% zusätzlichen Berechnung
Paradigmen des Sprachlernens vereinen
Geräuschmaskieren von T5 -Geräusch -Maskierung in Umarmungsfaktor -Transformatoren oder Python -Code
Oslo: Sehr unterschätzt, einige ordentliche und Dokumentationen, dies wird ein sehr nützliches Werkzeug sein
t5_pretraining.py
Stark von diesem Abschnitt inspiriert
Amazon Science: Label Awes Pretrain in Python
Fairseq: span_mask_tokens_dataset.py


