unify learning paradigms
1.0.0
ต้องการรับแบบจำลองที่ดีกว่าด้วยงบประมาณที่ จำกัด หรือไม่? คุณอยู่ในสถานที่ที่เหมาะสม
pip install text-denoising
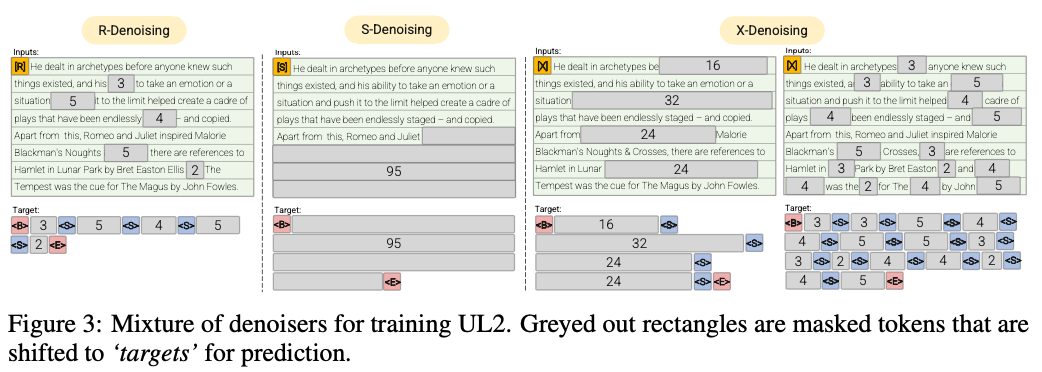
r-denoiser (μ = 3, r = 0.15, n) ∪ (μ = 8, r = 0.15, n)
denoising ปกติคือช่วงการทุจริตมาตรฐานที่แนะนำใน Raffel และคณะ (2019) ที่ใช้ช่วง 2 ถึง 5 โทเค็นเป็นความยาวช่วงซึ่งปิดบังโทเค็นอินพุตประมาณ 15%
S-Denoiser (μ = l/4, r = 0.25,1)
กรณีเฉพาะของ denoising ที่เราสังเกตลำดับที่เข้มงวดเมื่อกำหนดกรอบงานอินพุตตามเป้าหมายเช่นการสร้างแบบจำลองภาษาคำนำหน้า
X-Denoiser (μ = 3, r = 0.5, n) ∪ (μ = 8, r = 0.5, n) ∪ (μ = 64, r = 0.15, n) ∪ (μ = 64, r = 0.5, n)
Denoising รุ่นสุดขั้วที่รุ่นจะต้องกู้คืนส่วนใหญ่ของอินพุตได้รับส่วนเล็ก ๆ ถึงปานกลางของมัน สิ่งนี้จำลองสถานการณ์ที่โมเดลจำเป็นต้องสร้างเป้าหมายยาวจากหน่วยความจำที่มีข้อมูลค่อนข้าง จำกัด ในการทำเช่นนั้นเราเลือกที่จะรวมตัวอย่างที่มี denoising ก้าวร้าวซึ่งประมาณ 50% ของลำดับอินพุตถูกสวมหน้ากาก
2022 เอกสาร: การก้าวข้ามกฎหมายการปรับขนาดด้วยการคำนวณเพิ่มเติม 0.1%
เราแสดงอัตราการออมการคำนวณประมาณ 2 เท่า
denoising ปกติโดยที่เสียงจะถูกสุ่มตัวอย่างเป็นช่วงแทนที่ด้วยโทเค็นยามรักษาการณ์ นี่เป็นงานทุจริตมาตรฐานที่ใช้ใน Raffel และคณะ (2019) โดยทั่วไปจะมีการสุ่มตัวอย่างอย่างสม่ำเสมอด้วยค่าเฉลี่ย 3 และอัตราการทุจริต 15%
Extreme Denoising โดยที่เสียงจะเพิ่มขึ้นเป็นจำนวนมาก 'สุดขั้ว' ในจำนวนที่มากของข้อความต้นฉบับหรือยาวมากในธรรมชาติ โดยทั่วไปจะมีการสุ่มตัวอย่างอย่างสม่ำเสมอโดยมีความยาวเฉลี่ย 32 หรืออัตราการทุจริตสูงถึง 50%
Sequential denoising โดยที่เสียงจะถูกสุ่มตัวอย่างตั้งแต่เริ่มต้นของข้อความไปจนถึงจุดสุ่มตัวอย่างในข้อความ สิ่งนี้เป็นที่รู้จักกันในชื่อวัตถุประสงค์ของคำนำหน้า (เพื่อไม่ให้สับสนกับสถาปัตยกรรม)
repo นี้จะตั้งเป้าหมายสำหรับงานนี้แทน UL2 นั้นซับซ้อนเกินไปสำหรับความชอบของฉัน
prefixlm 50%, ยาว 25% (สุดขีด) ขยายการทุจริตและการทุจริตในช่วงปกติ 25% นั้นค่อนข้างง่ายและมีประสิทธิภาพ
เรียกใช้การเข้ารหัส mt5 pretraining บน 3090 บนไฟล์ pythia json.zst
pip install text-denoising
python examples/pretrain_example.py
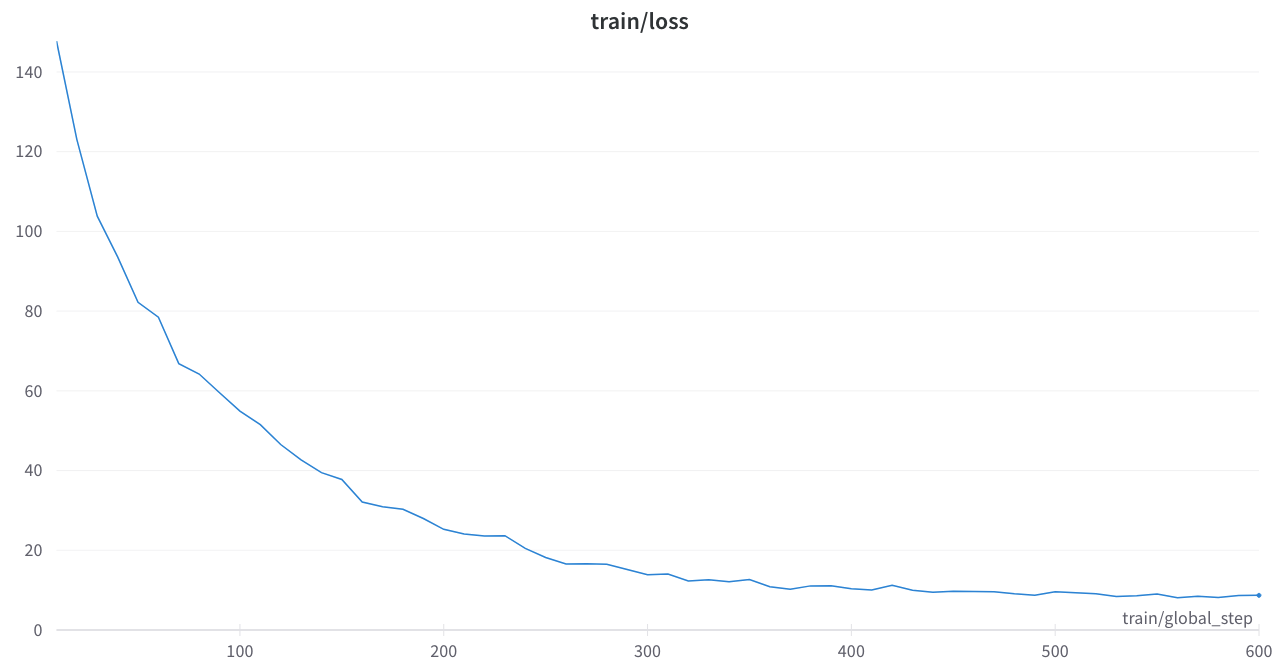
การสูญเสียการฝึกอบรมมีเสถียรภาพและไม่มีหนามแปลก ๆ
เอกสารหลัก
การปรับขนาดกฎหมายสเกลด้วยการคำนวณเพิ่มเติม 0.1%
การรวมกระบวนทัศน์การเรียนรู้ภาษา
การใช้การปิดบังเสียงรบกวน T5 ใน HuggingFace Transformers หรือ Python Code
ออสโล: มีความเป็นระเบียบและเป็นระเบียบเรียบร้อยมาก ๆ นี่จะเป็นเครื่องมือที่มีประโยชน์มาก
t5_pretraining.py
แรงบันดาลใจอย่างมากจากส่วนนี้
Amazon Science: Label Aware Pretrain ใน Python
fairseq: span_mask_tokens_dataset.py


