unify learning paradigms
1.0.0
Ingin mendapatkan model yang lebih baik dengan anggaran terbatas? Anda berada di tempat yang tepat
pip install text-denoising
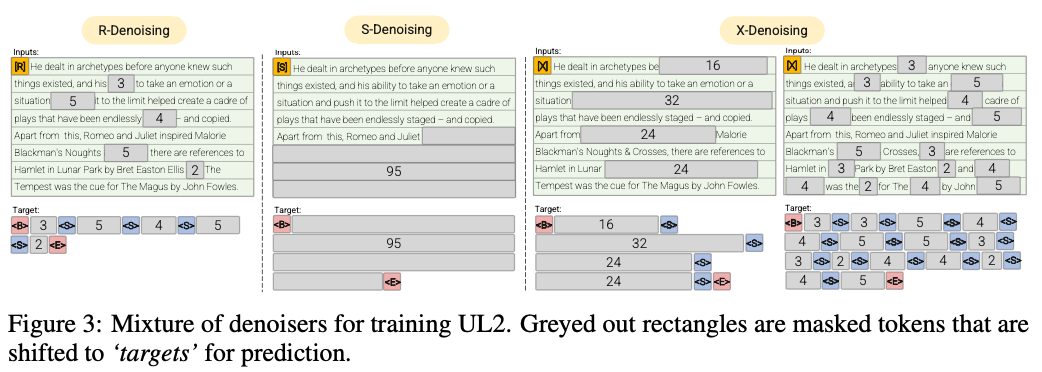
R-Denoiser (μ = 3, r = 0,15, n) ∪ (μ = 8, r = 0,15, n)
Denoising reguler adalah rentang standar korupsi yang diperkenalkan di Raffel et al. (2019) yang menggunakan kisaran 2 hingga 5 token sebagai panjang bentang, yang menutupi sekitar 15% dari token input
S-Denoiser (μ = l/4, r = 0,25,1)
Kasus spesifik denoising di mana kami mengamati urutan berurutan yang ketat saat membingkai tugas input-ke-target, yaitu, pemodelan bahasa awalan
X-Denoiser (μ = 3, r = 0,5, n) ∪ (μ = 8, r = 0,5, n) ∪ (μ = 64, r = 0,15, n) ∪ (μ = 64, r = 0,5, n)
Versi ekstrem dari denoising di mana model harus memulihkan sebagian besar input, diberi bagian kecil hingga sedang. Ini mensimulasikan situasi di mana model perlu menghasilkan target panjang dari memori dengan informasi yang relatif terbatas. Untuk melakukannya, kami memilih untuk memasukkan contoh dengan denoising agresif di mana sekitar 50% dari urutan input ditutupi
2022 Makalah: Melanggar hukum penskalaan dengan 0,1% komputasi tambahan
Kami menunjukkan tingkat tabungan komputasi sekitar 2x
Denoising reguler di mana kebisingan disampel sebagai rentang, diganti dengan token sentinel. Ini juga merupakan tugas korupsi rentang standar yang digunakan dalam Raffel et al. (2019). Rentang biasanya disampel secara seragam dengan rata -rata 3 dan tingkat korupsi 15%.
Denoising ekstrem di mana kebisingan meningkat menjadi jumlah yang relatif 'ekstrem' baik dalam persentase besar dari teks asli atau berada di alam yang sangat panjang. Rentang biasanya disampel secara seragam dengan panjang rata -rata 32 atau tingkat korupsi hingga 50%.
Denoising berurutan di mana noise selalu disampel dari awal teks ke titik sampel secara acak dalam teks. Ini juga dikenal sebagai tujuan awalan (jangan bingung dengan arsitektur).
Repo ini hanya akan bertujuan untuk menyertai tugas ini sebagai gantinya, UL2 terlalu rumit untuk kesukaan saya
50% awalan, 25% panjang (ekstrem) korupsi rentang, dan 25% korupsi rentang reguler menjadi cukup sederhana dan efisien
Jalankan pretraining encoder MT5 pada 3090 pada file pythia json.zst
pip install text-denoising
python examples/pretrain_example.py
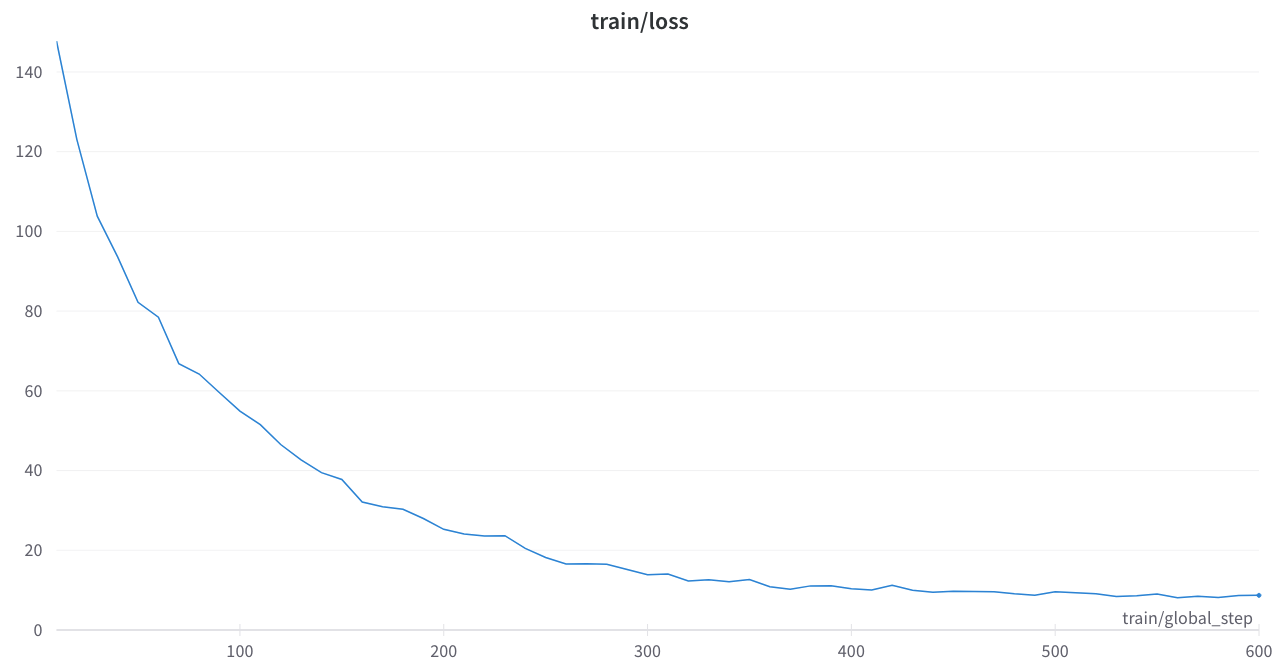
Kehilangan pelatihan stabil dan tidak ada paku yang aneh
Makalah inti
Melampaui undang -undang penskalaan dengan komputasi ekstra 0,1%
Paradigma Pembelajaran Bahasa
Implements T5 Noise Masking dalam Huggingface Transformers atau Python Code
Oslo: Sangat diremehkan, beberapa rapi dan dokumentasi, ini akan menjadi alat yang sangat berguna
t5_pretraining.py
Sangat terinspirasi dari bagian ini
Ilmu Amazon: Pretrain Aware Label di Python
Fairseq: span_mask_tokens_dataset.py


