TRIME
1.0.0
這是Zexuan Zhong,Tao Lei和Danqi Chen的EMNLP2022紙培訓語言模型的存儲庫。
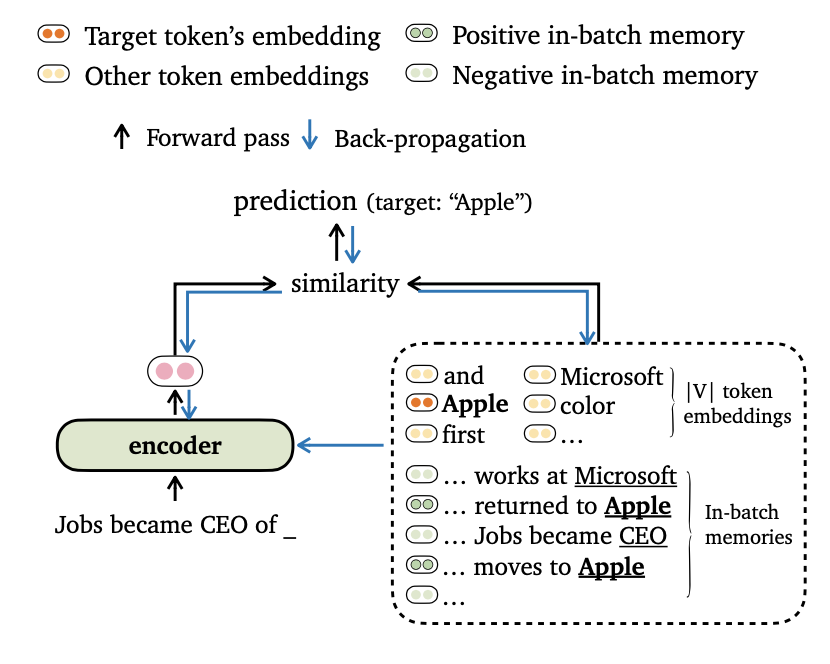
我們為語言建模提出了一個新的培訓目標,該目標是將模型輸出與令牌嵌入和內部內存的記憶保持一致。我們還為數據批處理和構建培訓記憶設計了新穎的方法,以便我們的模型可以有效地利用遠程環境和外部數據存儲。
請在我們的論文中找到更多有關此作品的詳細信息。
該代碼基於以下要求/依賴項(我們在括號中指定了我們在實驗中使用的版本):
您可以安裝此項目(基於Fairseq),如下:
pip install --editable .我們在Wikitext-103和ENWIK8數據集上進行實驗。請使用get_data.sh下載並預處理數據集。
bash get_data.sh {wikitext-103 | enwik8}處理後的數據集將存儲在data-bin/wikitext-103和data-bin/enwik8中。
我們顯示了在Wikitext-103上運行預訓練的模型的示例,模型尺寸= 247m,段長度= 3072。對於其他實驗(例如,具有不同的數據集或模型),我們參考所有實驗設置上的腳本run_pretrained_models.md。
Trimelm僅使用本地內存(在輸入中使用令牌構建)。它可以看作是輕量化的香草langauge型號。
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10參數:
--use-local使用本地內存指定。--softmax-temp指定計算損耗時使用的溫度項。Trimelm_long在推理過程中使用本地內存和長期內存。該模型能夠利用較長的上下文,儘管它經過較短的培訓。
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01參數:
--use-long使用長期記憶。--mem-size指定本地 +長期內存的大小。Trimelm_ext使用本地內存,長期內存和外部內存。在推斷期間,我們在訓練集上運行模型以構建外部內存,並使用FAISS庫來構建索引,以檢索最接近的近距離鄰居外部內存。我們還校準了在內存上的分離分佈,並與KNN-LM類似(請參閱本文中的詳細信息)。
我們首先下載預訓練的trimelm_ext:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..然後,我們使用訓練集生成外部內存(鍵和值),然後構建Faiss索引:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ip現在,我們準備評估該模型:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54參數:
--use-external使用外部內存指定。--dstore-filename和indexfile指定數據存儲和FAISS索引路徑。--use-interp指定使用兩個分佈之間的線性插值來校準最終概率。--lmbda和--interp-temp使用線性插值時指定溫度項和權重。我們列出了Wikitext-103和Enwik8上已發布的預訓練模型的性能,以及他們的下載鏈接。
| 數據集 | 模型 | 開發 | 測試 | 超參數 |
|---|---|---|---|---|
| Wikitext-103 | 三角形 (247m,L = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | trimelm_long (247m,L = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | trimelm_ext (247m,L = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | 三角形 (150m,L = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | trimelm_long (150m,L = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| Enwik8 | 三角形 (38m,L = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| Enwik8 | trimelm_long (38m,L = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
我們遵循Fairseq的培訓配方(例如,優化器,學習率,批次尺寸)進行訓練。以不同的方式,我們使用自己的損失功能(由--criterion指定)和數據批處理方法。
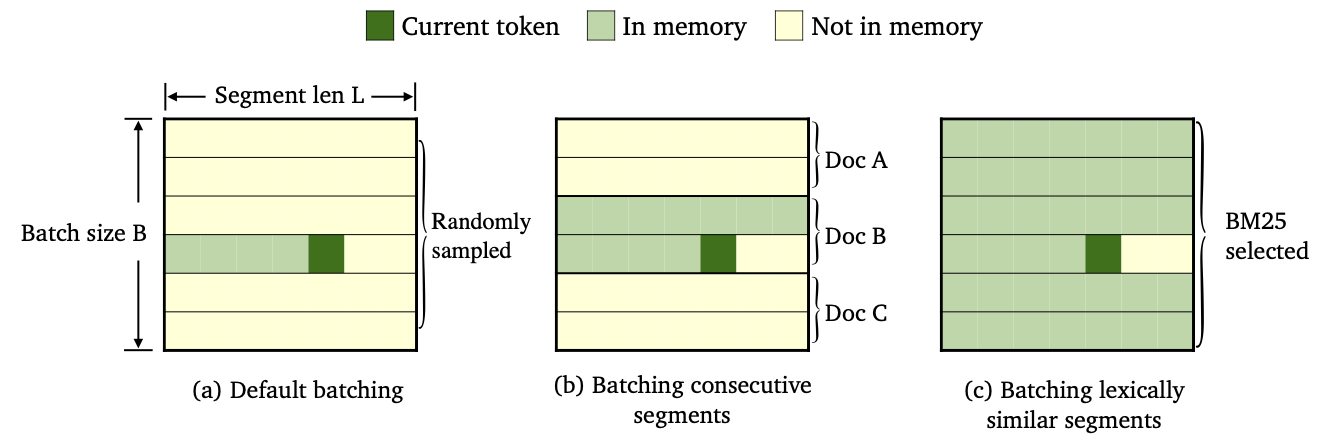
我們通過使用不同的數據批處理和內存構建方法訓練了三種trimelm。
--criterion trime_loss訓練--criterion trime_long_loss或--criterion trime_long_loss_same_device訓練--keep-order以批量連續段。trime_long_loss時,我們需要通過--train-mem-size指定內存大小(連續段的數字將為args.train_mem_size/args.tokens_per_sample )。trime_long_loss_same_device時,我們假設所有連續的段都加載在同一GPU設備中(等效於args.mem_size == args.max_tokens )。使用trime_long_loss_same_device比使用trime_long_loss更有效,因為它需要更少的跨GPU通信。--criterion trime_ext_loss訓練--predefined-batches指定。p ,我們禁用本地內存(即,僅使用其他段的令牌來構建內存)。概率p由--cross-sent-ratio指定這是訓練trimelm_ext模型的示例。您可以在Train_script中找到我們在實驗中使用的所有培訓腳本。
我們在4個NVIDIA RTX3090 GPU上訓練模型。
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.json重要論點:
--arch指定模型體系結構。在我們的實驗中,我們一直在使用以下架構。transformer_lm_wiki103 (Wikitext-103的247m型號)transformer_lm_wiki103_150M (Wikitext-103的150m型號)transformer_lm_enwik8 (ENWIK8的38m型號)--criterion指定了計算損失值的函數。請參閱上面有關我們支持哪些功能的描述。--tokens-per-sample指定段長度。--max-tokens指定每個GPU中要加載的令牌數量。--update-freq指定梯度蓄積步驟。--ce-warmup-epoch指定在訓練中使用的原始CE損失的數量。--cross-sent-ratio指定概率p以禁用本地內存。--predefined-batches指定了預定範圍批處理的文件路徑(我們使用BM25進行批處理段)。在使用--criterion trime_ext_loss訓練Trimelm_ext模型時,我們使用BM25分數來批處理培訓數據。
我們使用Pyserini庫來構建BM25索引。可以通過PIP安裝庫。
pip install pyserini我們首先將培訓集中的所有細分市場保存到.json文件中。
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengths然後,我們使用Pyserini構建BM25索引。
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRaw接下來,對於每個培訓部分,我們使用上面構建的BM25索引搜索類似的段。
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).最後,基於檢索結果,我們按組相似段創建批處理。
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json輸出文件wiki103-l3072-batches.json包含培訓段的索引列表,相鄰段可能相似。
批處理文件wiki103-l3072-batches.json可在trimelm_ext培訓期間使用參數--predefined-batches 。在培訓期間,我們只需從文件中以序列序列進行子列表來獲得培訓批次。
對於機器翻譯代碼和實驗,請查看子目錄。
如果您有與代碼或論文有關的任何疑問,或者在使用代碼時遇到任何問題,請隨時發送電子郵件至Zexuan Zhong ([email protected])或打開問題。請嘗試使用詳細信息指定問題,以便我們可以更好,更快地幫助您!
如果您在研究中使用我們的代碼,請引用我們的工作:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}我們的存儲庫基於Fairseq,KNNLM和自適應KNN-MT項目。我們感謝作者開源的出色代碼!


