TRIME
1.0.0
Este es el repositorio de nuestros modelos de lenguaje de capacitación en papel EMNLP2022 con aumento de la memoria, por Zexuan Zhong, Tao Lei y Danqi Chen.
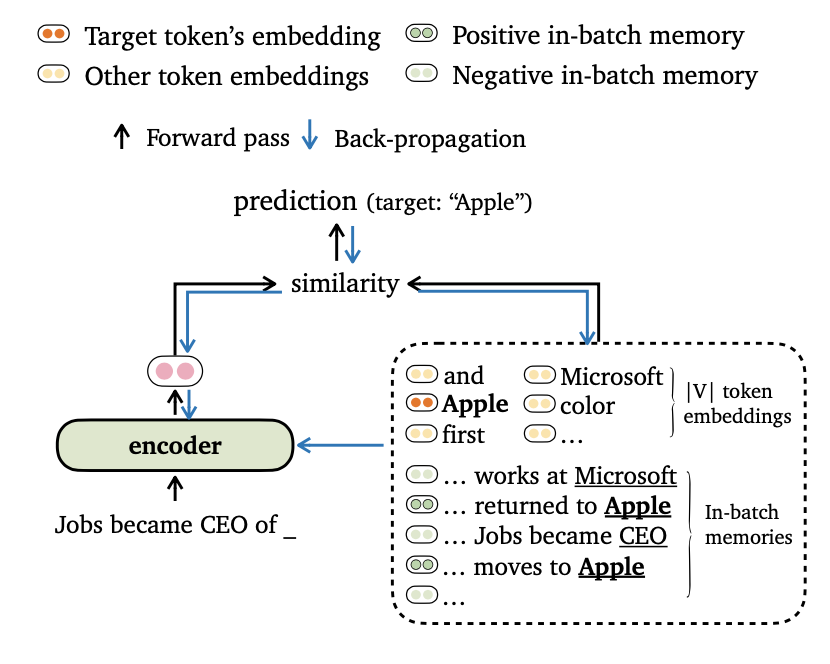
Proponemos un nuevo Time Objetivo de Entrenamiento para el modelado de idiomas, que alinea los resultados de los modelos con embedidas de token y recuerdos en el lote . También diseñamos formas novedosas para el lote de datos y la construcción de recuerdos de capacitación, para que nuestros modelos puedan aprovechar los contextos de largo alcance y el almacén de datos externo de manera efectiva.
Encuentre más detalles de este trabajo en nuestro artículo.
El código se basa en los siguientes requisitos/dependencias (especificamos la versión que utilizamos en nuestros experimentos entre paréntesis):
Puede instalar este proyecto (basado en Fairseq) de la siguiente manera:
pip install --editable . Realizamos experimentos en los conjuntos de datos Wikitext-103 y Enwik8 . Utilice get_data.sh para descargar y preprocesar los conjuntos de datos.
bash get_data.sh {wikitext-103 | enwik8} Los conjuntos de datos procesados se almacenarán en data-bin/wikitext-103 y data-bin/enwik8 .
Mostramos los ejemplos de la ejecución de modelos previamente capacitados en wikitext-103 con tamaño de modelo = 247m y longitud de segmento = 3072. Para otros experimentos (p. Ej.
Trimelm usa solo la memoria local (construida usando tokens en la entrada). Se puede ver como un reemplazo liviano para los modelos de vainilla Langauge.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10Argumentos:
--use-local especifica el uso de la memoria local.--softmax-temp especifica el término de temperatura utilizado al calcular la pérdida.Trimelm_long usa memoria local y memoria a largo plazo durante la inferencia. El modelo puede aprovechar los contextos largos, aunque está entrenado con otros más cortos.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01Argumentos:
--use-long especifica el uso de la memoria a largo plazo.--mem-size especifica el tamaño de la memoria local + a largo plazo.Trimelm_ext usa memoria local, memoria a largo plazo y memoria externa. Durante la inferencia, ejecutamos el modelo en el conjunto de capacitación para construir la memoria externa y usar la biblioteca FAISS para crear un índice para recuperar los vecinos más cercanos de Top-K la memoria externa. También calibramos una distribución separada sobre la memoria e interpolamos la distribución de salida y la distribución de memoria, de manera similar a KNN-LM (ver detalles en el documento).
Primero descargamos el trimelm_ext pre-entrenado:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..Luego, generamos la memoria externa (teclas y valores) utilizando el conjunto de entrenamiento y luego construimos el índice FAISS:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipAhora, estamos listos para evaluar el modelo:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54Argumentos:
--use-external especifica usando memoria externa.--dstore-filename y indexfile especifican el almacén de datos y las rutas de índice FAISS.--use-interp especifica el uso de una interpolación lineal entre dos distribuciones para calibrar la probabilidad final.--lmbda y --interp-temp especifican el término de temerpature y el peso al usar la interpolación lineal.Enumeramos el rendimiento de los modelos previamente entrenados en Wikitext-103 y Enwik8, así como sus enlaces de descarga.
| Conjunto de datos | Modelo | Enchufe | Prueba | Hiperparametros |
|---|---|---|---|---|
| Wikitext-103 | Trimelm (247m, L = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | Trimelm_long (247m, L = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | Trimelm_ext (247m, L = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | Trimelm (150m, L = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | Trimelm_long (150m, L = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | Trimelm (38m, l = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | Trimelm_long (38m, l = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
Seguimos la receta de entrenamiento de Fairseq (por ejemplo, optimizador, tasa de aprendizaje, tamaño por lotes) para entrenar trimelm. De manera diferente, utilizamos nuestras propias funciones de pérdida (especificadas por --criterion ) y métodos de lotes de datos.
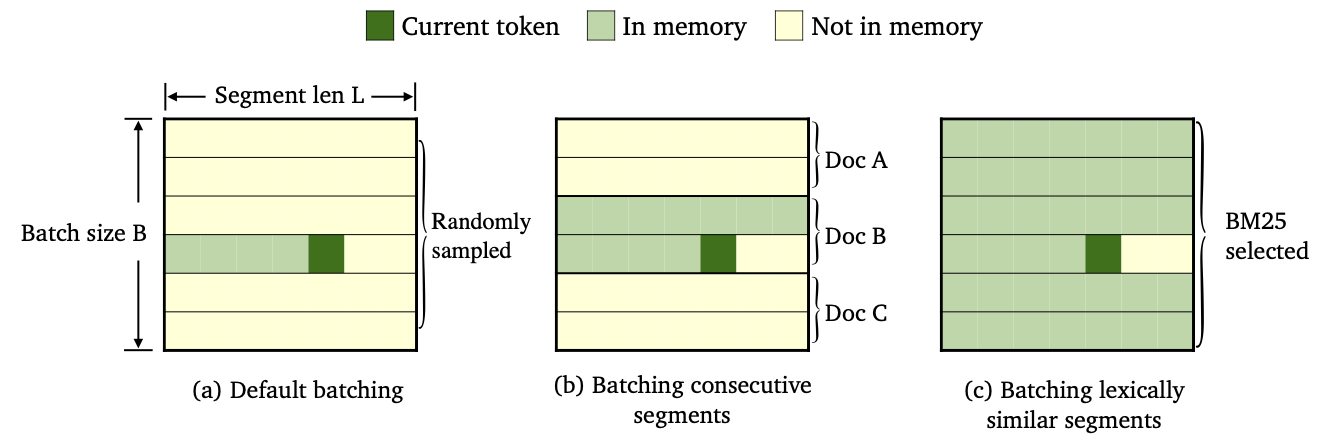
Entrenamos tres variedades de trimelm utilizando diferentes métodos de lotes de datos y construcción de memoria.
--criterion trime_loss--criterion trime_long_loss o --criterion trime_long_loss_same_device--keep-order es necesario para lanzar segmentos consecutivos.trime_long_loss , debemos especificar el tamaño de la memoria a través de --train-mem-size (NUM. De segmentos consecutivos serán args.train_mem_size/args.tokens_per_sample ).trime_long_loss_same_device , suponemos que todos los segmentos consecutivos se cargan en el mismo dispositivo GPU ( args.mem_size == args.max_tokens ). Usar trime_long_loss_same_device es más eficiente que usar trime_long_loss , ya que requiere menos comunicaciones de GPU.--criterion trime_ext_loss--predefined-batches .p , deshabilitamos la memoria local (es decir, solo usando tokens de otros segmentos para construir memoria). La probabilidad p se especifica mediante --cross-sent-ratioAquí hay un ejemplo de entrenamiento de un modelo Trimelm_ext. Puede encontrar todos los scripts de entrenamiento que utilizamos en nuestros experimentos en Train_Scripts.
Entrenamos nuestros modelos en 4 GPU NVIDIA RTX3090.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonArgumentos importantes:
--arch especifica la arquitectura del modelo. En nuestros experimentos, hemos estado utilizando las siguientes arquitecturas.transformer_lm_wiki103 (un modelo de 247m para wikitext-103)transformer_lm_wiki103_150M (un modelo de 150m para wikitext-103)transformer_lm_enwik8 (un modelo de 38m para enwik8)--criterion especifica la función para calcular los valores de pérdida. Vea la descripción anterior sobre qué funciones apoyamos.--tokens-per-sample especifica la longitud del segmento.--max-tokens especifica el número de tokens que se cargará en cada GPU.--update-freq especifica los pasos de acumulación de gradiente.--ce-warmup-epoch especifica cuántas épocas se usa la pérdida de CE original al principio para calentar el entrenamiento.--cross-sent-ratio especifica la probabilidad p de deshabilitar la memoria local.--predefined-batches especifican la ruta de archivo de los lotes predefinidos (usamos BM25 a segmentos de lotes). Al entrenar el modelo trimelm_ext con --criterion trime_ext_loss , usamos los puntajes BM25 para los datos de entrenamiento por lotes.
Usamos la biblioteca Pyserini para construir el índice BM25. La biblioteca se puede instalar a través de PIP.
pip install pyserini Primero guardamos todos los segmentos de la capacitación establecida en un archivo .json .
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsLuego, construimos el índice BM25 usando Pyserini.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawA continuación, para cada segmento de entrenamiento, buscamos en los segmentos similares utilizando el índice BM25 que construimos anteriormente.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).Finalmente, según los resultados de la recuperación, creamos lotes por grupos segmentos similares.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json El archivo de salida wiki103-l3072-batches.json contiene una lista de índices de segmentos de capacitación y segmentos adyacentes es probable que sean similares.
El archivo por lotes wiki103-l3072-batches.json se puede usar durante el entrenamiento de trimelm_ext, con los --predefined-batches . Durante el entrenamiento, simplemente obtenemos lotes de entrenamiento al tomar sub-listas secuencitalmente del archivo.
Para el código de traducción automática y los experimentos, consulte el subdirectorio.
Si tiene alguna pregunta relacionada con el código o el documento, o se encuentra con algún problema al usar el código, no dude en enviar un correo electrónico a Zexuan Zhong ([email protected]) o abrir un problema. ¡Intente especificar el problema con los detalles para que podamos ayudarlo mejor y más rápido!
Si usa nuestro código en su investigación, cite nuestro trabajo:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}Nuestro repositorio se basa en los proyectos Fairseq, KNNLM y Adaptive-Knn-MT. ¡Agradecemos a los autores por la obtención abierta del gran código!


