TRIME
1.0.0
Это хранилище для наших языковых моделей EMNLP2022 Language Language с увеличением памяти, Зуксуаном Чжун, Тао Лей и Данки Чен.
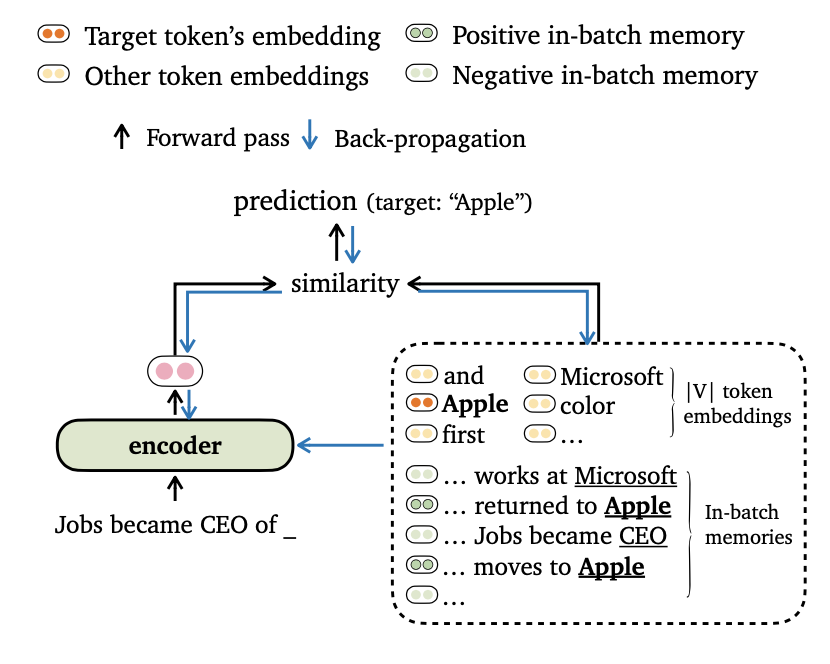
Мы предлагаем новое обучающее объективное Trime для языкового моделирования, которое выравнивает выходы моделей как с токеновыми вставками, так и с воспоминаниями . Мы также разработали новые способы для составления данных и построения обучающих воспоминаний, чтобы наши модели могли эффективно использовать дальние контексты и внешнее хранилище данных .
Пожалуйста, найдите более подробную информацию об этой работе в нашей статье.
Код основан на следующих требованиях/зависимостях (мы указываем версию, которую мы использовали в наших экспериментах в скобках):
Вы можете установить этот проект (на основе Fairseq) следующим образом:
pip install --editable . Мы проводим эксперименты на наборах данных Wikitext-103 и Enwik8 . Пожалуйста, используйте get_data.sh для загрузки и предварительной обработки наборов данных.
bash get_data.sh {wikitext-103 | enwik8} Обработанные наборы данных будут храниться в data-bin/wikitext-103 и data-bin/enwik8 .
Мы показываем примеры запуска предварительно обученных моделей на Wikitext-103 с размером модели = 247 м и длиной сегмента = 3072. Для других экспериментов (например, с различными наборами данных или моделями) мы ссылаемся на RUN_PRETRIND_MODELS.MD для сценариев во всех экспериментальных условиях.
Tremelm использует только локальную память (построенную с использованием токенов на входе). Его можно рассматривать как легкую замену для моделей Vanilla Langauge.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10Аргументы:
--use-local определяет с использованием локальной памяти.--softmax-temp указывает температурный термин, используемый при вычислении потерь.Tremelm_long использует локальную память и долговременную память во время вывода. Модель способна использовать длинные контексты, хотя она обучена более коротким.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01Аргументы:
--use-long указывает с использованием долговременной памяти.--mem-size определяет размер локальной + долгосрочной памяти.TRIMELM_EXT использует локальную память, долговременную память и внешнюю память. Во время вывода мы запускаем модель на обучающем наборе для создания внешней памяти и используем библиотеку FAISS для создания индекса для извлечения ближайших соседей Top-K в внешнюю память. Мы также откалибруем отдельное распределение по памяти и интерполируем выходное распределение и распределение памяти, аналогично KNN-LM (см. Подробности в статье).
Сначала скачиваем предварительно обученный tremelm_ext:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..Затем мы генерируем внешнюю память (клавиши и значения), используя учебный набор, а затем строим индекс FAISS:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipТеперь мы готовы оценить модель:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54Аргументы:
--use-external определяет с использованием внешней памяти.--dstore-filename и indexfile Указывают данные о данных и индексе FAISS.--use-interp определяет с использованием линейной интерполяции между двумя распределениями для калибровки конечной вероятности.--lmbda и --interp-temp Указывают термин TemerPature и вес при использовании линейной интерполяции.Мы перечислим производительность выпущенных предварительно обученных моделей на Wikitext-103 и Enwik8, а также их ссылки на загрузку.
| Набор данных | Модель | Девчонка | Тест | Гиперпараметры |
|---|---|---|---|---|
| Wikitext-103 | Тримельм (247 м, L = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | Tremelm_long (247 м, L = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | Tremelm_ext (247 м, L = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | Тримельм (150 м, L = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | Tremelm_long (150 м, L = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| Enwik8 | Тримельм (38 м, L = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| Enwik8 | Tremelm_long (38 м, L = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
Мы следим за учебным рецептом Fairseq (например, оптимизатор, скорость обучения, размеры партии), чтобы тренировать тримельм. По -другому мы используем наши собственные функции потерь (указанные в --criterion ) и методы партии данных.
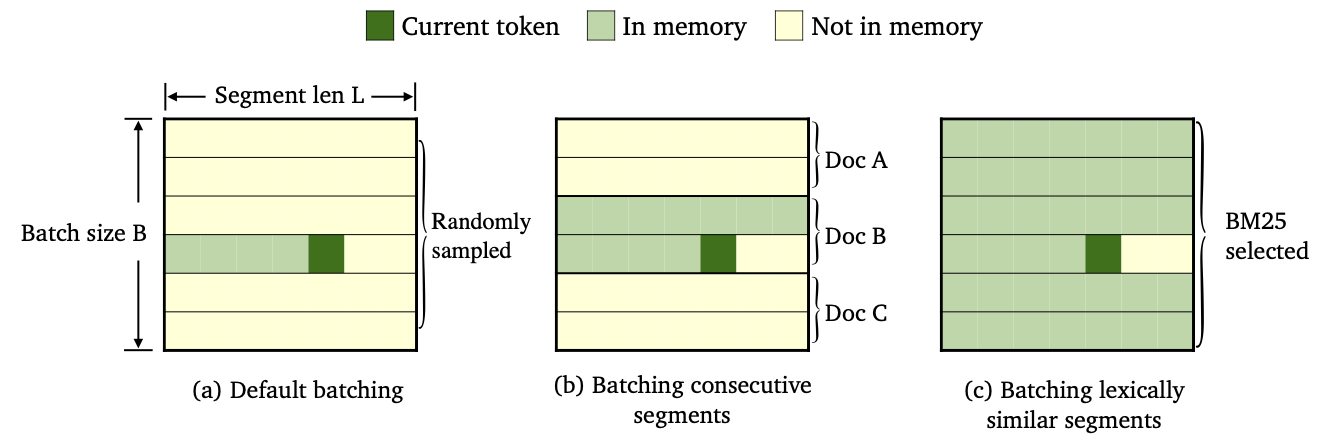
Мы обучили три разновидности тримельма, используя различные методы пакетирования данных и построения памяти.
--criterion trime_loss--criterion trime_long_loss или --criterion trime_long_loss_same_device--keep-order необходимо для составления последовательных сегментов.trime_long_loss нам необходимо указать размер памяти через --train-mem-size (NUM. Из последовательных сегментов будет args.train_mem_size/args.tokens_per_sample ).trime_long_loss_same_device мы предполагаем, что все последовательные сегменты загружаются в одно и то же устройство GPU (эквивалентно args.mem_size == args.max_tokens ). Использование trime_long_loss_same_device является более эффективным, чем использование trime_long_loss , поскольку это требует меньших взаимосвязи между GPU.--criterion trime_ext_loss--predefined-batches .p мы отключим локальную память (т. Е. Использование только токенов из других сегментов для построения памяти). Вероятность p определяется- --cross-sent-ratioВот пример обучения модели tremelm_ext. Вы можете найти все учебные сценарии, которые мы использовали в наших экспериментах в Train_scripts.
Мы тренируем наши модели на 4 NVIDIA RTX3090 GPU.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonВажные аргументы:
--arch определяет модель архитектуру. В наших экспериментах мы использовали следующие архитектуры.transformer_lm_wiki103 (модель 247 м для Wikitext-103)transformer_lm_wiki103_150M (модель 150 м для Wikitext-103)transformer_lm_enwik8 (модель 38M для Enwik8)--criterion указывает функцию для вычисления значений потерь. См. Описание выше о том, какие функции мы поддерживаем.--tokens-per-sample Определяет длину сегмента.--max-tokens указывает количество токенов, которые будут загружены в каждом графическом процессоре.--update-freq Определяет шаги градиента-аккумуляции.--ce-warmup-epoch указывает, сколько эпох в начале используется первоначальная потеря CE, чтобы согреть тренировки.--cross-sent-ratio Указывает вероятность p , чтобы отключить локальную память.--predefined-batches определяют путь файла предопределенных партий (мы используем BM25 для сегментов партии). При обучении модели TRIMELM_EXT с помощью --criterion trime_ext_loss , мы используем баллы BM25 для пакетных данных обучения.
Мы используем библиотеку Pyserini для создания индекса BM25. Библиотека может быть установлена через PIP.
pip install pyserini Сначала мы сохраняем все сегменты от обучения в файле .json .
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsЗатем мы строим индекс BM25, используя Pyserini.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawЗатем для каждого сегмента обучения мы ищем аналогичные сегменты, используя индекс BM25, который мы построили выше.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).Наконец, основываясь на результатах поиска, мы создаем партии по группе аналогичных сегментов.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json Выходной файл wiki103-l3072-batches.json содержит список индексов обучающих сегментов и смежных сегментов, вероятно, будет аналогичным.
Пакетный файл wiki103-l3072-batches.json может использоваться во время обучения trimelm_ext с аргументами --predefined-batches . Во время обучения мы просто получаем учебные партии, получая подразделения по спискам из файла.
Для кода машинного перевода и экспериментов, пожалуйста, ознакомьтесь с подкаталорией.
Если у вас есть какие -либо вопросы, связанные с кодом или статьей, или вы сталкиваетесь с какими -либо проблемами при использовании кода, не стесняйтесь по электронной почте Zexuan Zhong ([email protected]) или открыть проблему. Пожалуйста, попробуйте указать проблему с деталями, чтобы мы могли помочь вам лучше и быстрее!
Если вы используете наш код в своем исследовании, пожалуйста, укажите нашу работу:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}Наш репо основан на проектах Fairseq, KNNLM и адаптивного KNN-MT. Мы благодарим авторов за открытый источник отличного кода!


