TRIME
1.0.0
Ini adalah repositori untuk model bahasa pelatihan kertas EMNLP2022 kami dengan augmentasi memori, oleh Zexuan Zhong, Tao Lei, dan Danqi Chen.
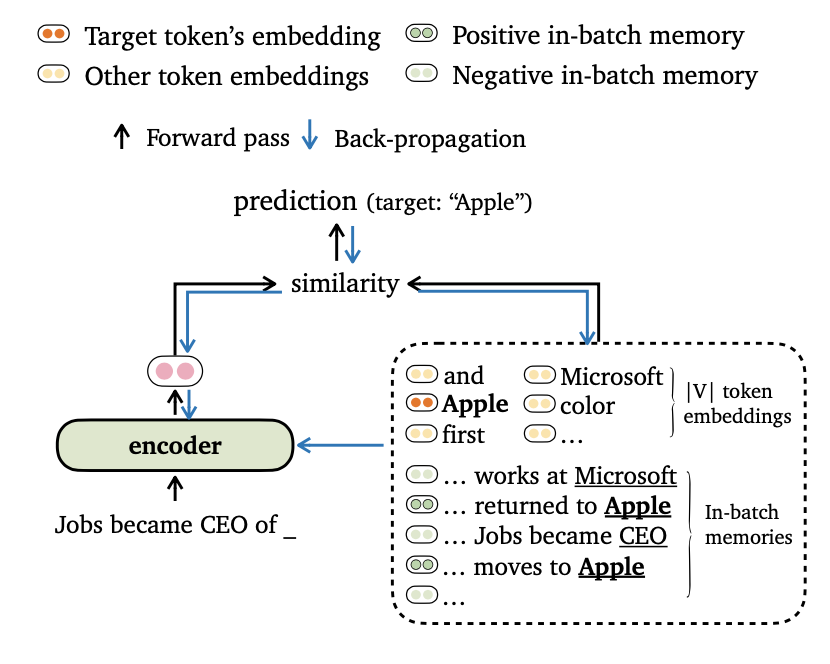
Kami mengusulkan trime tujuan pelatihan baru untuk pemodelan bahasa, yang menyelaraskan output model dengan embeddings token dan kenangan dalam-batch . Kami juga menyusun cara-cara baru untuk batching data dan membangun kenangan pelatihan, sehingga model kami dapat memanfaatkan konteks jangka panjang dan datastore eksternal secara efektif.
Silakan temukan lebih detail dari pekerjaan ini di makalah kami.
Kode ini didasarkan pada persyaratan/dependensi berikut (kami menentukan versi yang kami gunakan dalam percobaan kami dalam tanda kurung):
Anda dapat menginstal proyek ini (berdasarkan Fairseq) sebagai berikut:
pip install --editable . Kami melakukan eksperimen pada dataset Wikuxt-103 dan Enwik8 . Harap gunakan get_data.sh untuk mengunduh dan preprocess dataset.
bash get_data.sh {wikitext-103 | enwik8} Dataset yang diproses akan disimpan dalam data-bin/wikitext-103 dan data-bin/enwik8 .
Kami menunjukkan contoh menjalankan model pra-terlatih di wikuxt-103 dengan ukuran model = 247m dan panjang segmen = 3072. Untuk percobaan lain (misalnya, dengan dataset atau model yang berbeda), kami merujuk ke run_pretrain_models.md untuk skrip pada semua pengaturan eksperimental.
Trimelm hanya menggunakan memori lokal (dibangun menggunakan token dalam input). Ini dapat dilihat sebagai pengganti yang ringan untuk model vanilla langauge.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10Argumen:
--use-local Menentukan menggunakan memori lokal.--softmax-temp menentukan istilah suhu yang digunakan saat menghitung kerugian.Trimelm_long menggunakan memori lokal dan memori jangka panjang selama inferensi. Model ini mampu memanfaatkan konteks yang panjang, meskipun dilatih dengan yang lebih pendek.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01Argumen:
--use-long Menentukan menggunakan memori jangka panjang.--mem-size menentukan ukuran memori jangka panjang lokal +.TRIMELM_EXT menggunakan memori lokal, memori jangka panjang, dan memori eksternal. Selama inferensi, kami menjalankan model pada set pelatihan untuk membangun memori eksternal dan menggunakan pustaka FAISS untuk membangun indeks untuk mengambil tetangga terdekat dengan-k tetangga terdekat memori eksternal. Kami juga mengkalibrasi distribusi yang terpisah di atas memori dan menginterpolasi distribusi output dan distribusi memori, mirip dengan KNN-LM (lihat detail di koran).
Kami pertama kali mengunduh trimelm_ext pra-terlatih:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..Kemudian, kami menghasilkan memori eksternal (kunci dan nilai) menggunakan set pelatihan dan kemudian membangun indeks FAISS:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipSekarang, kami siap mengevaluasi model:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54Argumen:
--use-external Menentukan menggunakan memori eksternal.--dstore-filename dan indexfile Menentukan jalur Datastore dan FAISS Indeks.--use-interp Menentukan menggunakan interpolasi linier antara dua distribusi ke Calibrate Final Probablity.--lmbda dan --interp-temp Menentukan istilah temerpature dan berat saat menggunakan interpolasi linier.Kami mencantumkan kinerja model pra-terlatih yang dirilis di Wikitext-103 dan Enwik8, serta tautan unduhan mereka.
| Dataset | Model | Dev | Tes | Hyper-parameter |
|---|---|---|---|---|
| Wikuxt-103 | Trimelm (247m, l = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikuxt-103 | Trimelm_long (247m, l = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikuxt-103 | Trimelm_ext (247m, l = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikuxt-103 | Trimelm (150m, L = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikuxt-103 | Trimelm_long (150m, L = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | Trimelm (38m, L = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | Trimelm_long (38m, L = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
Kami mengikuti resep pelatihan Fairseq (misalnya, pengoptimal, tingkat pembelajaran, ukuran batch) untuk melatih trimelm. Secara berbeda, kami menggunakan fungsi kerugian kami sendiri (ditentukan oleh --criterion ) dan metode batching data.
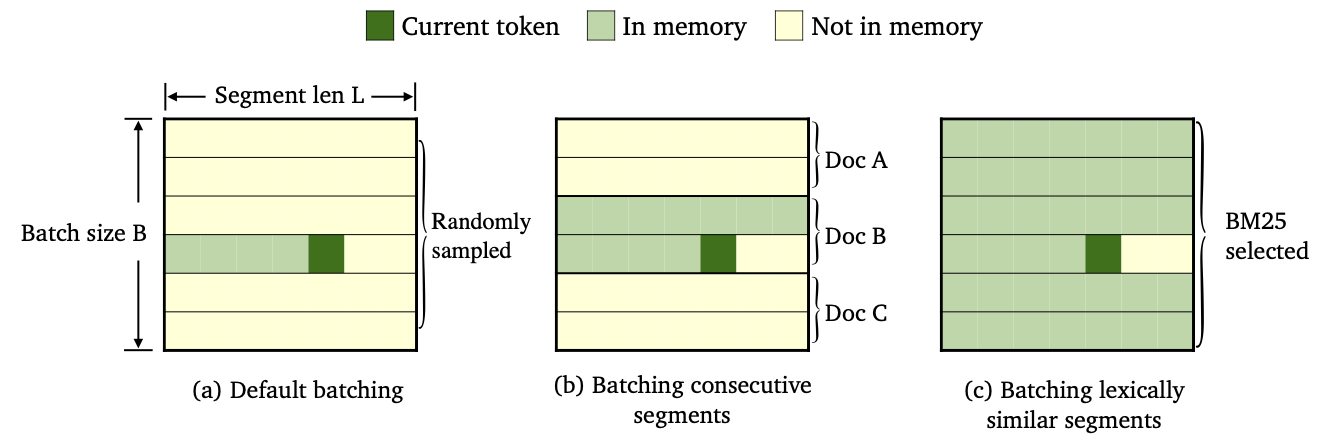
Kami melatih tiga varietas trimelm dengan menggunakan metode batching data dan konstruksi memori yang berbeda.
--criterion trime_loss--criterion trime_long_loss atau --criterion trime_long_loss_same_device--keep-order diperlukan untuk batch segmen berturut-turut.trime_long_loss , kita perlu menentukan ukuran memori melalui --train-mem-size (num. Segmen berturut-turut akan menjadi args.train_mem_size/args.tokens_per_sample ).trime_long_loss_same_device , kami mengasumsikan semua segmen berturut -turut dimuat di perangkat GPU yang sama (setara args.mem_size == args.max_tokens ). Menggunakan trime_long_loss_same_device lebih efisien daripada menggunakan trime_long_loss , karena membutuhkan lebih sedikit komunikasi cross-gpu.--criterion trime_ext_loss--predefined-batches .p , kami menonaktifkan memori lokal (yaitu, hanya menggunakan token dari segmen lain untuk membangun memori). Kemungkinan p ditentukan oleh --cross-sent-ratioBerikut adalah contoh pelatihan model trimelm_ext. Anda dapat menemukan semua skrip pelatihan yang kami gunakan dalam percobaan kami di Train_Scripts.
Kami melatih model kami pada 4 NVIDIA RTX3090 GPU.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonArgumen penting:
--arch Menentukan arsitektur model. Dalam percobaan kami, kami telah menggunakan arsitektur berikut.transformer_lm_wiki103 (model 247m untuk wikuxt-103)transformer_lm_wiki103_150M (model 150m untuk wikuxt-103)transformer_lm_enwik8 (model 38m untuk enwik8)--criterion Menentukan fungsi untuk menghitung nilai rugi. Lihat deskripsi di atas tentang fungsi mana yang kami dukung.--tokens-per-sample menentukan panjang segmen.--max-tokens Menentukan jumlah token yang akan dimuat di setiap GPU.--update-freq Menentukan langkah-langkah akumulasi gradien.--ce-warmup-epoch menentukan berapa banyak zaman kehilangan CE asli digunakan pada awalnya untuk memanaskan pelatihan.--cross-sent-ratio Menentukan probabilitas p untuk menonaktifkan memori lokal.--predefined-batches Menentukan jalur file batch yang telah ditentukan (kami menggunakan segmen BM25 ke batch). Saat melatih model trimelm_ext dengan --criterion trime_ext_loss , kami menggunakan skor BM25 untuk data pelatihan batch.
Kami menggunakan pustaka Pyserini untuk membangun indeks BM25. Perpustakaan dapat diinstal melalui PIP.
pip install pyserini Kami pertama -tama menyimpan semua segmen dari pelatihan yang diatur ke dalam file .json .
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsKemudian, kami membangun indeks BM25 menggunakan pyserini.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawSelanjutnya, untuk setiap segmen pelatihan, kami mencari segmen serupa menggunakan indeks BM25 yang kami buat di atas.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).Akhirnya, berdasarkan hasil pengambilan, kami membuat batch oleh grup segmen serupa.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json File output wiki103-l3072-batches.json berisi daftar indeks segmen pelatihan dan segmen yang berdekatan cenderung serupa.
File batch wiki103-l3072-batches.json dapat digunakan selama pelatihan trimelm_ext, dengan argumen --predefined-batches . Selama pelatihan, kami hanya mendapatkan batch pelatihan dengan mengambil sub-daftar secara berurutan dari file.
Untuk kode dan eksperimen terjemahan mesin, silakan periksa subdirektori.
Jika Anda memiliki pertanyaan yang terkait dengan kode atau kertas, atau Anda menghadapi masalah saat menggunakan kode, jangan ragu untuk mengirim email kepada Zexuan Zhong ([email protected]) atau membuka masalah. Silakan coba tentukan masalah dengan detail sehingga kami dapat membantu Anda lebih baik dan lebih cepat!
Jika Anda menggunakan kode kami dalam penelitian Anda, silakan kutip pekerjaan kami:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}Repo kami didasarkan pada proyek Fairseq, KNNLM, dan adaptif-KNN-MT. Kami berterima kasih kepada penulis untuk open-sourcing kode hebat!


