TRIME
1.0.0
이것은 Zexuan Zhong, Tao Lei 및 Danqi Chen의 메모리 증강이있는 EMNLP2022 종이 훈련 언어 모델의 저장소입니다.
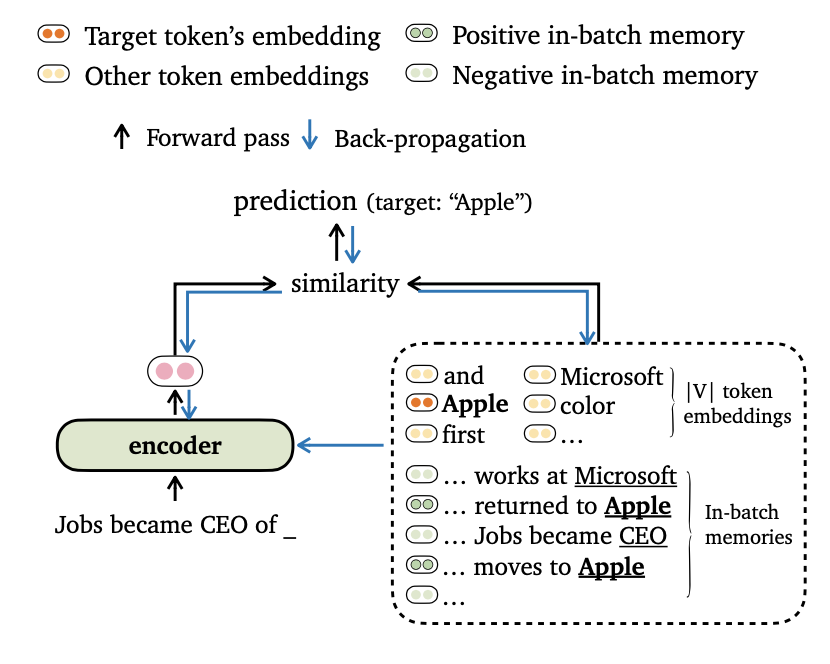
우리는 언어 모델링에 대한 새로운 교육 목표 트리임을 제안하며, 이는 모델 출력을 토큰 임베드 및 배치 내 메모리 와 일치시킵니다. 또한 데이터 배치 및 교육 메모리 구성을위한 새로운 방법을 고안하여 모델이 장거리 컨텍스트 와 외부 데이터 스토어를 효과적으로 활용할 수 있습니다.
이 작업에 대한 자세한 내용은 본 논문에서 찾으십시오.
이 코드는 다음 요구 사항/종속성을 기반으로합니다 (실험에서 사용한 버전을 괄호로 지정합니다).
이 프로젝트 (FairSeQ 기반)를 다음과 같이 설치할 수 있습니다.
pip install --editable . Wikitext-103 및 Enwik8 데이터 세트에 대한 실험을 수행합니다. get_data.sh 사용하여 데이터 세트를 다운로드하고 전처리하십시오.
bash get_data.sh {wikitext-103 | enwik8} 처리 된 데이터 세트는 data-bin/wikitext-103 및 data-bin/enwik8 에 저장됩니다.
Wikitext-103에서 모델 크기 = 247m 및 세그먼트 길이 = 3072로 미리 훈련 된 모델을 실행하는 예를 보여줍니다. 다른 실험 (예 : 다른 데이터 세트 또는 모델 포함)의 경우 모든 실험 설정의 스크립트에 대해 run_pretraind_models.md를 참조합니다.
Trimelm은 로컬 메모리 (입력에서 토큰을 사용하여 구성) 만 사용합니다. 바닐라 랑 게이지 모델의 가벼운 대체물로 볼 수 있습니다.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10논쟁 :
--use-local 로컬 메모리를 사용하여 지정합니다.--softmax-temp 손실을 계산할 때 사용되는 온도 항을 지정합니다.Trimelm_long은 추론 중에 로컬 메모리와 장기 메모리를 사용합니다. 이 모델은 짧은 컨텍스트를 더 짧은 컨텍스트로 활용할 수 있습니다.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01논쟁 :
--use-long 장기 메모리를 사용하여 지정합니다.--mem-size 로컬 + 장기 메모리의 크기를 지정합니다.Trimelm_ext는 로컬 메모리, 장기 메모리 및 외부 메모리를 사용합니다. 추론하는 동안, 우리는 외부 메모리를 구축하고 FAISS 라이브러리를 사용하여 Top-K 가장 가까운 이웃을 외부 메모리를 검색하기위한 색인을 구축하기 위해 교육 세트의 모델을 실행합니다. 또한 메모리에 대한 분리 된 분포를 보정하고 KNN-LM과 유사하게 출력 분포 및 메모리 분포를 보간합니다 (용지의 세부 사항 참조).
먼저 미리 훈련 된 trimelm_ext를 다운로드합니다.
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..그런 다음 교육 세트를 사용하여 외부 메모리 (키 및 값)를 생성 한 다음 Faiss 색인을 작성합니다.
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ip이제 모델을 평가할 준비가되었습니다.
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54논쟁 :
--use-external 외부 메모리를 사용하여 지정합니다.--dstore-filename 및 indexfile 데이터 저장소 및 FAISS 인덱스 경로를 지정합니다.--use-interp 두 분포 사이의 선형 보간을 사용하여 최종 프로 블리를 교정합니다.--lmbda 및 --interp-temp 선형 보간을 사용할 때 온도 용어와 무게를 지정합니다.Wikitext-103 및 Enwik8에서 발표 된 미리 훈련 된 모델의 성능과 다운로드 링크를 나열합니다.
| 데이터 세트 | 모델 | 데브 | 시험 | 하이퍼 파라미터 |
|---|---|---|---|---|
| Wikitext-103 | TRIMELM (247m, l = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | trimelm_long (247m, l = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | trimelm_ext (247m, l = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | TRIMELM (150m, l = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | trimelm_long (150m, l = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | TRIMELM (38m, l = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | trimelm_long (38m, l = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
우리는 FairSeQ의 교육 레시피 (예 : Optimizer, Learning Rate, Batch Size)를 따라 Trimelm을 훈련시킵니다. 다르게, 우리는 자체 손실 함수 ( --criterion 에 의해 지정 됨) 및 데이터 배치 방법을 사용합니다.
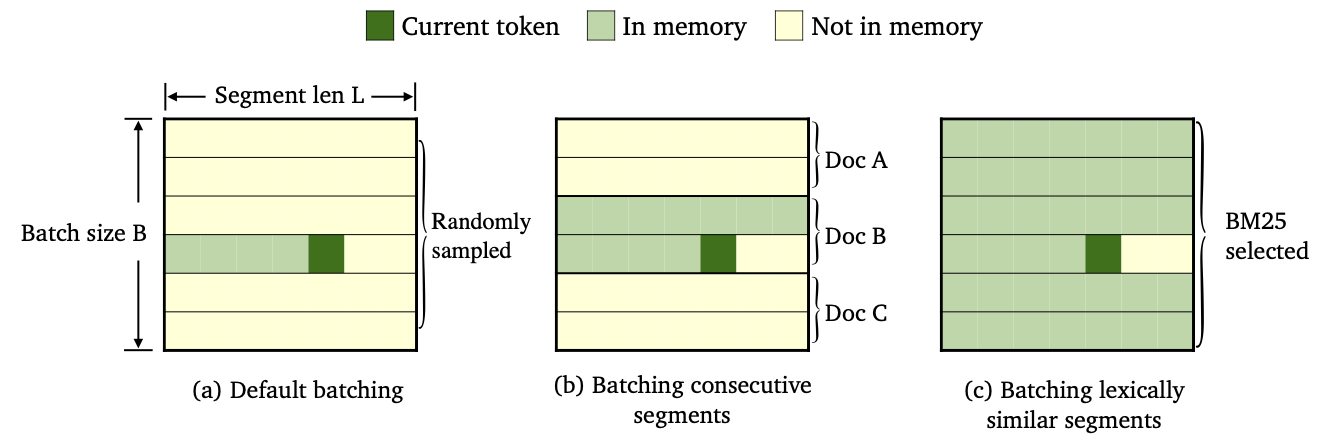
우리는 다른 데이터 배치 및 메모리 구조 방법을 사용하여 3 가지 종류의 Trimelm을 교육했습니다.
--criterion trime_loss 로 훈련되었습니다--criterion trime_long_loss 또는 --criterion trime_long_loss_same_device 로 교육을 받았습니다.--keep-order 필요합니다.trime_long_loss 사용하는 경우 --train-mem-size 통해 메모리 크기를 지정해야합니다 (연속 세그먼트의 Num.은 args.train_mem_size/args.tokens_per_sample )입니다.trime_long_loss_same_device 사용하는 경우 모든 연속 세그먼트가 동일한 GPU 장치에로드 된 것으로 가정합니다 (동등한 args.mem_size == args.max_tokens ). trime_long_loss_same_device 사용은 trime_long_loss 사용하는 것보다 더 효율적입니다. 크로스 GPU 통신이 적기 때문입니다.--criterion trime_ext_loss 로 훈련되었습니다--predefined-batches 에 의해 지정됩니다.p 사용하면 로컬 메모리를 비활성화합니다 (예 : 다른 세그먼트의 토큰 만 사용하여 메모리를 구성). probablity p --cross-sent-ratio 에 의해 지정됩니다다음은 trimelm_ext 모델을 훈련시키는 예입니다. Train_Scripts 실험에서 사용한 모든 교육 스크립트를 찾을 수 있습니다.
우리는 4 NVIDIA RTX3090 GPU에 대한 모델을 훈련시킵니다.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.json중요한 주장 :
--arch 모델 아키텍처를 지정합니다. 실험에서 우리는 다음 아키텍처를 사용하고 있습니다.transformer_lm_wiki103 (Wikitext-103 용 247m 모델)transformer_lm_wiki103_150M (Wikitext-103 용 150m 모델)transformer_lm_enwik8 (ENWIK8 용 38m 모델)--criterion 손실 값을 계산하는 함수를 지정합니다. 우리가 지원하는 기능에 대해서는 위의 설명을 참조하십시오.--tokens-per-sample 세그먼트 길이를 지정합니다.--max-tokens 각 GPU에로드 할 토큰 수를 지정합니다.--update-freq 그라디언트 획득 단계를 지정합니다.--ce-warmup-epoch 처음에 원래 CE 손실을 사용하여 훈련을 예열하는 데 얼마나 많은 시대를 지정합니다.--cross-sent-ratio 로컬 메모리를 비활성화 할 확률 p 지정합니다.--predefined-batches 사전 정의 된 배치의 파일 경로를 지정합니다 (BM25에서 배치 세그먼트를 사용). --criterion trime_ext_loss 로 trimelm_ext 모델을 훈련시킬 때 BM25 점수를 사용하여 훈련 데이터를 배치합니다.
우리는 Pyserini 라이브러리를 사용하여 BM25 지수를 구축합니다. 라이브러리는 PIP를 통해 설치할 수 있습니다.
pip install pyserini 먼저 교육 세트에서 모든 세그먼트를 .json 파일로 저장합니다.
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengths그런 다음 Pyserini를 사용하여 BM25 지수를 구축합니다.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRaw다음으로, 각 교육 세그먼트에 대해 위에서 구축 한 BM25 인덱스를 사용하여 유사한 세그먼트를 검색합니다.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).마지막으로, 검색 결과를 바탕으로 그룹 유사한 세그먼트 별 배치를 만듭니다.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json 출력 파일 wiki103-l3072-batches.json 에는 훈련 세그먼트 지수 목록이 포함되어 있으며 인접한 세그먼트가 비슷할 수 있습니다.
배치 파일 wiki103-l3072-batches.json trimelm_ext를 훈련하는 동안 --predefined-batches 와 함께 사용될 수 있습니다. 훈련하는 동안 파일에서 서브리스트를 시퀀싱하여 단순히 훈련 배치를받습니다.
기계 번역 코드 및 실험은 하위 디렉토리를 확인하십시오.
코드 나 논문과 관련된 질문이 있거나 코드를 사용할 때 문제가 발생하면 Zexuan Zhong ([email protected]) 을 이메일로 보내거나 문제를여십시오. 세부 사항으로 문제를 지정하여 더 나은 시간을 더 빨리 도와 줄 수 있습니다!
귀하의 연구에서 우리의 코드를 사용하는 경우, 우리의 작업을 인용하십시오.
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}우리의 저장소는 FairSeQ, Knnlm 및 Adaptive-KNN-MT 프로젝트를 기반으로합니다. 우리는 저자들에게 큰 코드를 오픈 소싱 해준 감사합니다!


