TRIME
1.0.0
นี่คือพื้นที่เก็บข้อมูลสำหรับแบบจำลองภาษาการฝึกอบรมกระดาษ EMNLP2022 ของเราพร้อมการเสริมหน่วยความจำโดย Zexuan Zhong, Tao Lei และ Danqi Chen
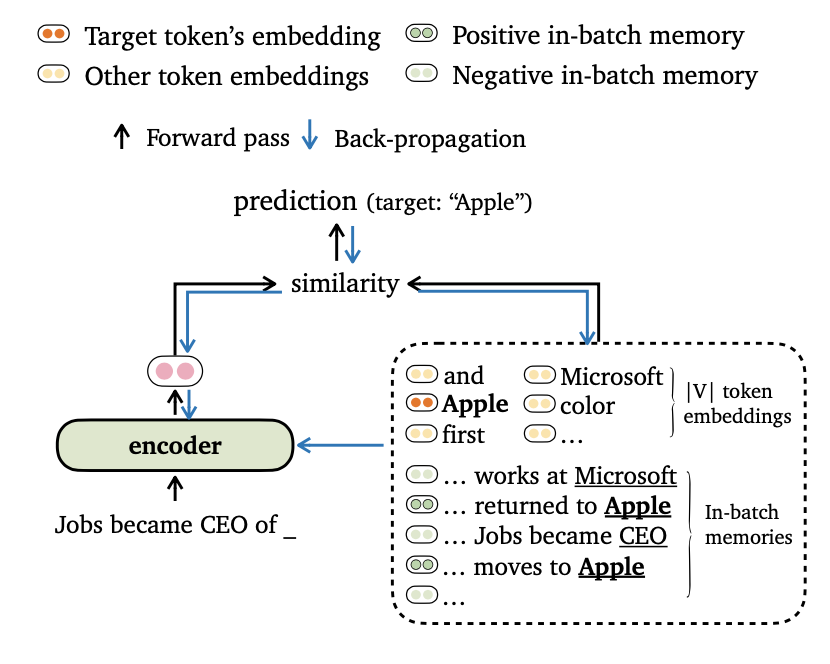
เราเสนอ Trime Trime การฝึกอบรมใหม่สำหรับการสร้างแบบจำลองภาษาซึ่งจัดเรียงโมเดลเอาท์พุทกับทั้งการฝังโทเค็นและ ความทรงจำในชุด นอกจากนี้เรายังกำหนดวิธีการใหม่สำหรับการแบตช์ข้อมูลและการสร้างความทรงจำในการฝึกอบรมเพื่อให้แบบจำลองของเราสามารถใช้ประโยชน์จาก บริบทระยะยาว และ ที่เก็บข้อมูลภายนอก ได้อย่างมีประสิทธิภาพ
โปรดค้นหารายละเอียดเพิ่มเติมของงานนี้ในบทความของเรา
รหัสขึ้นอยู่กับข้อกำหนด/การพึ่งพาต่อไปนี้ (เราระบุเวอร์ชันที่เราใช้ในการทดลองของเราในวงเล็บ):
คุณสามารถติดตั้งโครงการนี้ (ตาม Fairseq) ดังนี้:
pip install --editable . เราทำการทดลองเกี่ยวกับชุดข้อมูล Wikitext-103 และ Enwik8 โปรดใช้ get_data.sh เพื่อดาวน์โหลดและประมวลผลชุดข้อมูลล่วงหน้า
bash get_data.sh {wikitext-103 | enwik8} ชุดข้อมูลที่ประมวลผลจะถูกเก็บไว้ใน data-bin/wikitext-103 และ data-bin/enwik8
เราแสดงตัวอย่างของการรันโมเดลที่ผ่านการฝึกอบรมมาก่อนบน Wikitext-103 ด้วยขนาดรุ่น = 247m และความยาวเซ็กเมนต์ = 3072 สำหรับการทดลองอื่น ๆ (เช่นด้วยชุดข้อมูลหรือรุ่นที่แตกต่างกัน) เราอ้างถึง run_pretrained_models.md สำหรับสคริปต์ในการตั้งค่าการทดลองทั้งหมด
Trimelm ใช้เฉพาะหน่วยความจำภายใน (สร้างขึ้นโดยใช้โทเค็นในอินพุต) มันสามารถดูได้ว่าเป็นการทดแทนที่มีน้ำหนักเบาสำหรับรุ่นวานิลลา Langauge
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10ข้อโต้แย้ง:
--use-local ระบุโดยใช้หน่วยความจำในท้องถิ่น--softmax-temp ระบุคำอุณหภูมิที่ใช้เมื่อคำนวณการสูญเสียTRIMELM_LONG ใช้หน่วยความจำท้องถิ่นและหน่วยความจำระยะยาวในระหว่างการอนุมาน โมเดลสามารถใช้ประโยชน์จากบริบทที่ยาวนานแม้ว่าจะได้รับการฝึกฝนให้สั้นลง
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01ข้อโต้แย้ง:
--use-long ระบุโดยใช้หน่วยความจำระยะยาว--mem-size ระบุขนาดของหน่วยความจำท้องถิ่น + ระยะยาวTRIMELM_EXT ใช้หน่วยความจำภายในหน่วยความจำระยะยาวและหน่วยความจำภายนอก ในระหว่างการอนุมานเราเรียกใช้โมเดลในชุดการฝึกอบรมเพื่อสร้างหน่วยความจำภายนอกและใช้ไลบรารี FAISS เพื่อสร้างดัชนีสำหรับการเรียกคืนหน่วยความจำภายนอกที่ใกล้ที่สุด นอกจากนี้เรายังสอบเทียบการแจกแจงที่แยกออกจากหน่วยความจำและแทรกการแจกแจงเอาต์พุตและการแจกแจงหน่วยความจำคล้ายกับ KNN-LM (ดูรายละเอียดในกระดาษ)
ก่อนอื่นเราดาวน์โหลด trimelm_ext ที่ผ่านการฝึกอบรมมาก่อน:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..จากนั้นเราสร้างหน่วยความจำภายนอก (ปุ่มและค่า) โดยใช้ชุดการฝึกอบรมจากนั้นสร้างดัชนี FAISS:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipตอนนี้เราพร้อมที่จะประเมินรูปแบบ:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54ข้อโต้แย้ง:
--use-external ระบุโดยใช้หน่วยความจำภายนอก--dstore-filename และ indexfile ระบุที่เก็บข้อมูลและเส้นทางดัชนี FAISS--use-interp ระบุโดยใช้การแก้ไขเชิงเส้นระหว่างการแจกแจงสองครั้งเพื่อปรับเทียบความน่าจะเป็นขั้นสุดท้าย--lmbda และ --interp-temp ระบุคำศัพท์และน้ำหนักเมื่อใช้การแก้ไขเชิงเส้นเราแสดงรายการประสิทธิภาพของโมเดลที่ได้รับการฝึกอบรมล่วงหน้าบน Wikitext-103 และ Enwik8 รวมถึงลิงก์ดาวน์โหลดของพวกเขา
| ชุดข้อมูล | แบบอย่าง | คนกิน | ทดสอบ | พารามิเตอร์ไฮเปอร์ |
|---|---|---|---|---|
| Wikitext-103 | Trimelm (247m, l = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | trimelm_long (247m, l = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | trimelm_ext (247m, l = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | Trimelm (150m, l = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | trimelm_long (150m, l = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | Trimelm (38m, l = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | trimelm_long (38m, l = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
เราทำตามสูตรการฝึกอบรมของ Fairseq (เช่นเครื่องมือเพิ่มประสิทธิภาพอัตราการเรียนรู้ขนาดแบทช์) เพื่อฝึกอบรม Trimelm แตกต่างกันเราใช้ฟังก์ชั่นการสูญเสียของเราเอง (ระบุโดย --criterion ) และวิธีการแบทช์ข้อมูล
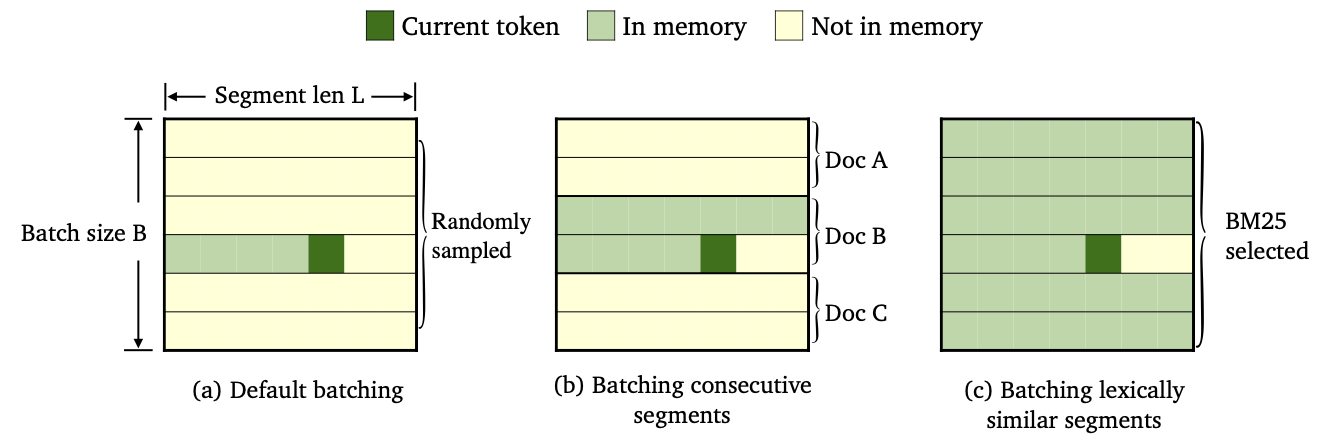
เราฝึกฝน Trimelm สามสายพันธุ์โดยใช้การแบทช์ข้อมูลที่แตกต่างกันและวิธีการก่อสร้างหน่วยความจำ
--criterion trime_loss--criterion trime_long_loss หรือ --criterion trime_long_loss_same_device--keep-order ซื้อเพื่อแบทช์ต่อเนื่องtrime_long_loss เราจำเป็นต้องระบุขนาดหน่วยความจำผ่าน --train-mem-size (NUM. ของเซ็กเมนต์ต่อเนื่องจะเป็น args.train_mem_size/args.tokens_per_sample )trime_long_loss_same_device เราถือว่ากลุ่มต่อเนื่องทั้งหมดจะถูกโหลดในอุปกรณ์ GPU เดียวกัน (เทียบเท่า args.mem_size == args.max_tokens ) การใช้ trime_long_loss_same_device มีประสิทธิภาพมากกว่าการใช้ trime_long_loss เนื่องจากต้องใช้การสื่อสารข้าม GPU น้อยกว่า--criterion trime_ext_loss--predefined-batchesp เราจะปิดการใช้งานหน่วยความจำท้องถิ่น (เช่นใช้โทเค็นจากกลุ่มอื่น ๆ เพื่อสร้างหน่วยความจำ) Probablity p ถูกระบุโดย --cross-sent-ratioนี่คือตัวอย่างของการฝึกอบรมโมเดล trimelm_ext คุณสามารถค้นหาสคริปต์การฝึกอบรมทั้งหมดที่เราใช้ในการทดลองของเราใน Train_Scripts
เราฝึกอบรมโมเดลของเราใน 4 Nvidia RTX3090 GPU
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonข้อโต้แย้งที่สำคัญ:
--arch ระบุสถาปัตยกรรมแบบจำลอง ในการทดลองของเราเราได้ใช้สถาปัตยกรรมต่อไปนี้transformer_lm_wiki103 (รุ่น 247m สำหรับ Wikitext-103)transformer_lm_wiki103_150M (รุ่น 150m สำหรับ wikitext-103)transformer_lm_enwik8 (รุ่น 38m สำหรับ enwik8)--criterion ระบุฟังก์ชั่นเพื่อคำนวณค่าการสูญเสีย ดูคำอธิบายด้านบนเกี่ยวกับฟังก์ชั่นที่เราสนับสนุน--tokens-per-sample ระบุความยาวส่วน--max-tokens ระบุจำนวนโทเค็นที่จะโหลดในแต่ละ GPU--update-freq ระบุขั้นตอนการสะสมการไล่ระดับสี--ce-warmup-epoch ระบุจำนวนยุคที่การสูญเสีย CE ดั้งเดิมใช้ในช่วงเริ่มต้นเพื่ออุ่นเครื่องการฝึกอบรม--cross-sent-ratio ระบุความน่าจะเป็น p เพื่อปิดการใช้งานหน่วยความจำท้องถิ่น--predefined-batches ระบุเส้นทางไฟล์ของแบทช์ที่กำหนดไว้ล่วงหน้า (เราใช้ BM25 ไปยังกลุ่มแบทช์) เมื่อฝึกอบรมโมเดล TRIMELM_EXT ด้วย --criterion trime_ext_loss เราจะใช้คะแนน BM25 กับข้อมูลการฝึกอบรมแบบชุด
เราใช้ไลบรารี Pyserini เพื่อสร้างดัชนี BM25 ห้องสมุดสามารถติดตั้งผ่าน PIP
pip install pyserini ก่อนอื่นเราบันทึกทุกกลุ่มจากการฝึกอบรมที่กำหนดไว้ในไฟล์ .json
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsจากนั้นเราสร้างดัชนี BM25 โดยใช้ Pyserini
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawต่อไปสำหรับแต่ละเซ็กเมนต์การฝึกอบรมเราจะค้นหากลุ่มที่คล้ายกันโดยใช้ดัชนี BM25 ที่เราสร้างไว้ข้างต้น
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).ในที่สุดขึ้นอยู่กับผลลัพธ์การดึงเราสร้างแบทช์ตามกลุ่มกลุ่มที่คล้ายกัน
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json ไฟล์เอาต์พุต wiki103-l3072-batches.json มีรายการดัชนีของกลุ่มการฝึกอบรมและส่วนที่อยู่ติดกันมีแนวโน้มที่จะคล้ายกัน
ไฟล์แบตช์ wiki103-l3072-batches.json สามารถใช้ในระหว่างการฝึกอบรมของ trimelm_ext โดยมีอาร์กิวเมนต์ --predefined-batches ในระหว่างการฝึกอบรมเราเพียงแค่ได้รับการฝึกอบรมโดยการรับรายการย่อยตามลำดับจากไฟล์
สำหรับรหัสแปลและการทดลองของเครื่องโปรดตรวจสอบไดเรกทอรีย่อย
หากคุณมีคำถามใด ๆ ที่เกี่ยวข้องกับรหัสหรือกระดาษหรือคุณพบปัญหาใด ๆ เมื่อใช้รหัสอย่าลังเลที่จะส่งอีเมล Zexuan Zhong ([email protected]) หรือเปิดปัญหา โปรดพยายามระบุปัญหาพร้อมรายละเอียดเพื่อให้เราสามารถช่วยคุณได้ดีขึ้นและเร็วขึ้น!
หากคุณใช้รหัสของเราในการวิจัยของคุณโปรดอ้างอิงงานของเรา:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}repo ของเราขึ้นอยู่กับโครงการ Fairseq, KNNLM และ Adaptive-KNN-MT เราขอขอบคุณผู้เขียนที่เปิดรหัสที่ยอดเยี่ยม!


