TRIME
1.0.0
Ceci est le référentiel de nos modèles de langage de formation en papier EMNLP2022 avec augmentation de la mémoire, par Zexuan Zhong, Tao Lei et Danqi Chen.
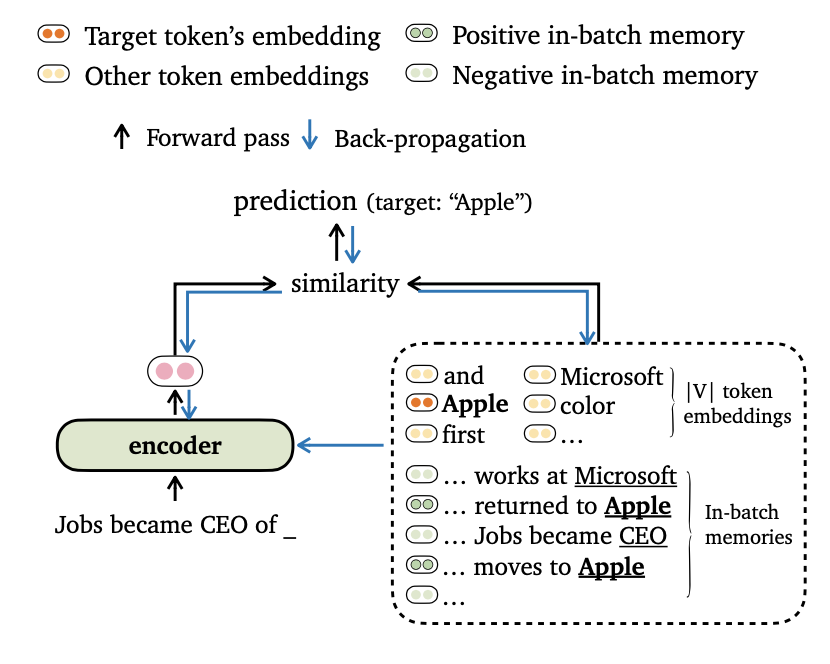
Nous proposons un nouveau trime d'objectif de formation pour la modélisation du langage, qui aligne les sorties du modèle avec les incorporations de jetons et les souvenirs en lots . Nous conduisons également de nouvelles façons de faire un lots de données et de construire des souvenirs d'entraînement, afin que nos modèles puissent tirer parti des contextes à longue portée et de la banque de données externe efficacement.
Veuillez trouver plus de détails sur ce travail dans notre article.
Le code est basé sur les exigences / dépendances suivantes (nous spécifions la version que nous avons utilisée dans nos expériences entre parenthèses):
Vous pouvez installer ce projet (basé sur Fairseq) comme suit:
pip install --editable . Nous effectuons des expériences sur les ensembles de données WikiteXT-103 et Enwik8 . Veuillez utiliser get_data.sh pour télécharger et prétraiter les ensembles de données.
bash get_data.sh {wikitext-103 | enwik8} Les ensembles de données traités seront stockés dans data-bin/wikitext-103 et data-bin/enwik8 .
Nous montrons les exemples d'exécution de modèles pré-formés sur wikitext-103 avec la taille du modèle = 247m et la longueur du segment = 3072. Pour d'autres expériences (par exemple, avec différents ensembles de données ou modèles), nous nous référons à run_pretrain_models.md pour les scripts sur tous les paramètres expérimentaux.
Trimelm utilise uniquement la mémoire locale (construite à l'aide de jetons dans l'entrée). Il peut être considéré comme un remplacement léger pour les modèles Vanilla Langauge.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10Arguments:
--use-local Spécifie l'utilisation de la mémoire locale.--softmax-temp Spécifie le terme de température utilisé lors du calcul de la perte.Trimelm_Long utilise la mémoire locale et la mémoire à long terme pendant l'inférence. Le modèle est capable de tirer parti de longs contextes, bien qu'il soit formé avec des plus courts.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01Arguments:
--use-long Spécifie l'utilisation de la mémoire à long terme.--mem-size Spécifie la taille de la mémoire locale + à long terme.Trimelm_EXT utilise la mémoire locale, la mémoire à long terme et la mémoire externe. Pendant l'inférence, nous exécutons le modèle sur l'ensemble de formation pour construire la mémoire externe et utilisons la bibliothèque FAISS pour créer un index pour récupérer les voisins les plus proches de la mémoire externe. Nous calibrons également une distribution séparée sur la mémoire et interpolons la distribution de sortie et la distribution de la mémoire, de la même manière que KNN-LM (voir les détails du papier).
Nous téléchargeons d'abord le trimelm_ext pré-formé:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..Ensuite, nous générons la mémoire externe (touches et valeurs) à l'aide de l'ensemble de formation, puis construisons l'index FAISS:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipMaintenant, nous sommes prêts à évaluer le modèle:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54Arguments:
--use-external Spécifie à l'aide de la mémoire externe.--dstore-filename et indexfile Spécifiez le plan de données et les chemins d'index FAISS.--use-interp spécifie l'utilisation d'une interpolation linéaire entre deux distributions pour calibrer la probabilité finale.--lmbda et --interp-temp spécifiez le terme temerpature et le poids lors de l'utilisation de l'interpolation linéaire.Nous énumérons les performances des modèles pré-formés publiés sur Wikitext-103 et Enwik8, ainsi que leurs liens de téléchargement.
| Ensemble de données | Modèle | Dev | Test | Hyper-paramètres |
|---|---|---|---|---|
| Wikitext-103 | Trimeler (247m, l = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | Trimelm_long (247m, l = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | Trimelm_ext (247m, l = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | Trimeler (150m, l = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | Trimelm_long (150m, l = 150) | 21.76 | 22,62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | Trimeler (38m, l = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | Trimelm_long (38m, l = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
Nous suivons la recette de formation de Fairseq (par exemple, optimiseur, taux d'apprentissage, taille du lot) pour entraîner Trimelm. Différemment, nous utilisons nos propres fonctions de perte (spécifiées par --criterion ) et les méthodes de lots de données.
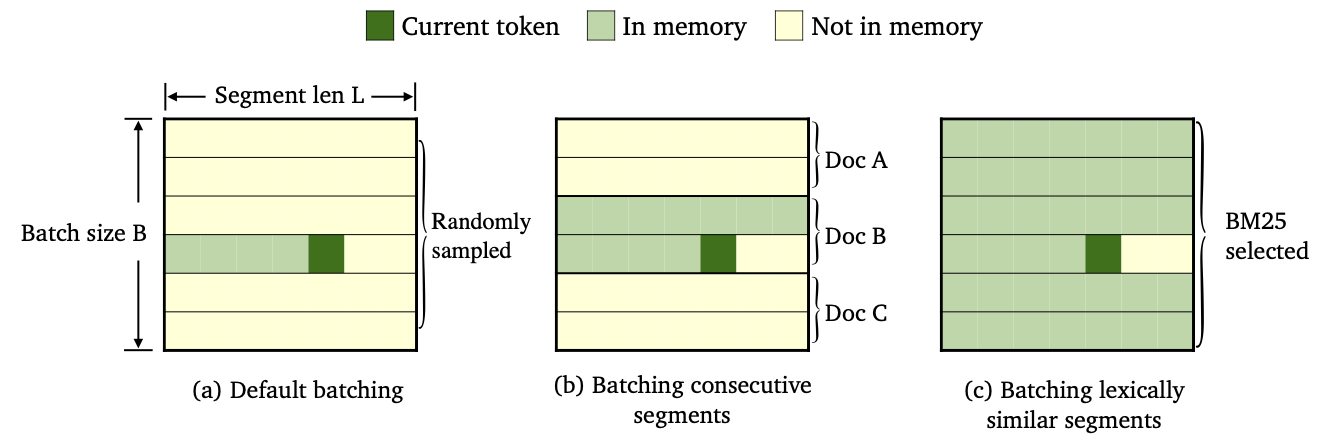
Nous avons formé trois variétés de trimelm en utilisant différentes méthodes de lots de données et de construction de mémoire.
--criterion trime_loss--criterion trime_long_loss ou --criterion trime_long_loss_same_device--keep-order est nécessaire pour laver les segments consécutifs.trime_long_loss , nous devons spécifier la taille de la mémoire via --train-mem-size (num. Des segments consécutifs seront args.train_mem_size/args.tokens_per_sample ).trime_long_loss_same_device , nous supposons que tous les segments consécutifs sont chargés dans le même périphérique GPU (équivalencement args.mem_size == args.max_tokens ). L'utilisation trime_long_loss_same_device est plus efficace que l'utilisation trime_long_loss , car elle nécessite moins de communications cross-gpu.--criterion trime_ext_loss--predefined-batches .p , nous désactivons la mémoire locale (c'est-à-dire en utilisant uniquement des jetons à partir d'autres segments pour construire la mémoire). La probabilité p est spécifiée par --cross-sent-ratioVoici un exemple de formation d'un modèle trimelm_ext. Vous pouvez trouver tous les scripts de formation que nous avons utilisés dans nos expériences dans Train_Scripts.
Nous formons nos modèles sur 4 GPU NVIDIA RTX3090.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonArguments importants:
--arch spécifie l'architecture du modèle. Dans nos expériences, nous utilisons les architectures suivantes.transformer_lm_wiki103 (un modèle 247m pour wikitext-103)transformer_lm_wiki103_150M (un modèle 150m pour wikitext-103)transformer_lm_enwik8 (un modèle de 38m pour Enwik8)--criterion Spécifie la fonction pour calculer les valeurs de perte. Voir Description ci-dessus sur les fonctions que nous prenons en charge.--tokens-per-sample spécifie la longueur du segment.--max-tokens spécifie le nombre de jetons à charger dans chaque GPU.--update-freq spécifie les étapes d'accrulation du gradient.--ce-warmup-epoch Spécifie le nombre d'époches que la perte d'origine CE est utilisée au début pour échauffer la formation.--cross-sent-ratio Spécifie la probabilité p pour désactiver la mémoire locale.--predefined-batches spécifient le chemin du fichier des lots prédéfinis (nous utilisons BM25 pour les segments par lots). Lors de la formation du modèle Trimelm_EXT avec --criterion trime_ext_loss , nous utilisons les scores BM25 pour laver les données de formation.
Nous utilisons la bibliothèque Pyserini pour créer l'index BM25. La bibliothèque peut être installée via PIP.
pip install pyserini Nous enregistrons d'abord tous les segments de l'ensemble de formation dans un fichier .json .
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsEnsuite, nous construisons l'index BM25 à l'aide de Pyserini.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawEnsuite, pour chaque segment de formation, nous recherchons les segments similaires en utilisant l'index BM25 que nous avons construit ci-dessus.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).Enfin, sur la base des résultats de récupération, nous créons des lots par groupe de segments similaires.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json Le fichier de sortie wiki103-l3072-batches.json contient une liste des indices de segments de formation et de segments adjacents est probablement similaire.
Le fichier batch wiki103-l3072-batches.json peut être utilisé lors de la formation de trimelm_ext, avec l'argument --predefined-batches . Pendant la formation, nous obtenons simplement des lots de formation en prenant des sous-listes séquencées à partir du fichier.
Pour le code et les expériences de traduction automatique, veuillez consulter le sous-répertoire.
Si vous avez des questions liées au code ou au document, ou si vous rencontrez des problèmes lorsque vous utilisez le code, n'hésitez pas à envoyer un e-mail à Zexuan Zhong ([email protected]) ou ouvrez un problème. Veuillez essayer de spécifier le problème avec les détails afin que nous puissions vous aider mieux et plus rapidement!
Si vous utilisez notre code dans votre recherche, veuillez citer notre travail:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}Notre dépôt est basé sur les projets Fairseq, KNNLM et Adaptive-Knn-MT. Nous remercions les auteurs pour l'ouverture du grand code!


