TRIME
1.0.0
Dies ist das Repository für unsere EMNLP2022 -Papiertrainingssprachenmodelle mit Gedächtnisvergrößerung von Zexuan Zhong, Tao Lei und Danqi Chen.
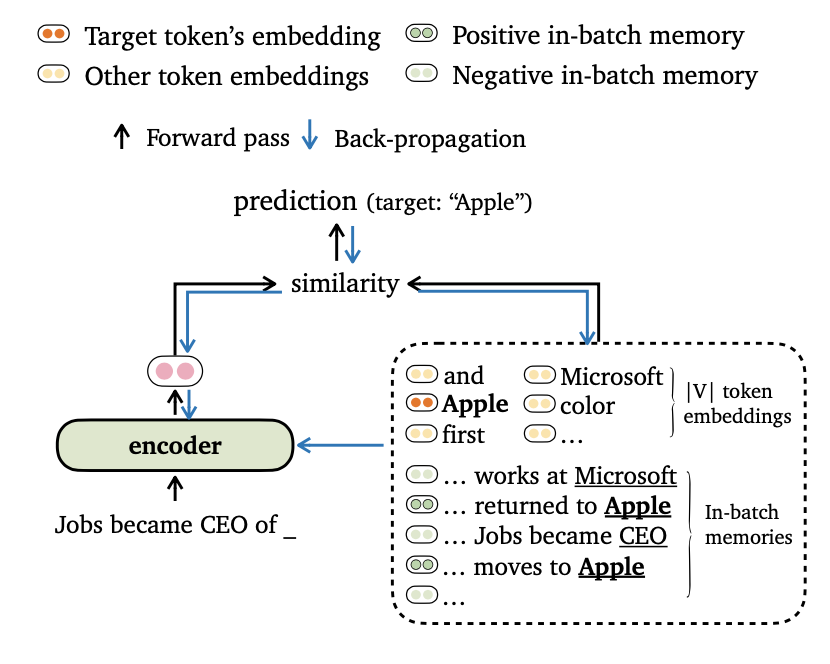
Wir schlagen ein neues Trainingszieltrime für die Sprachmodellierung vor, das die Modellausgänge sowohl mit Token-Einbettungen als auch mit In-Batch-Erinnerungen ausrichtet. Wir entwickeln auch neuartige Möglichkeiten für das Datenmodus und die Konstruktion von Trainingserinnerungen, damit unsere Modelle Langstreckenkontexte und externer Datenspeicher effektiv nutzen können.
Weitere Informationen zu dieser Arbeit finden Sie in unserer Zeitung.
Der Code basiert auf den folgenden Anforderungen/Abhängigkeiten (wir geben die Version an, die wir in unseren Experimenten in Klammern verwendet haben):
Sie können dieses Projekt (basierend auf Fairseq) wie folgt installieren:
pip install --editable . Wir führen Experimente mit den Datensätzen Wikitext-103 und Enwik8 durch. Bitte verwenden Sie get_data.sh , um die Datensätze herunterzuladen und vorzubearbeiten.
bash get_data.sh {wikitext-103 | enwik8} Die verarbeiteten Datensätze werden in data-bin/wikitext-103 und data-bin/enwik8 gespeichert.
Wir zeigen die Beispiele für die Ausführung von vorgebildeten Modellen auf Wikitext-103 mit Modellgröße = 247 m und Segmentlänge = 3072. Für andere Experimente (z. B. mit unterschiedlichen Datensätzen oder Modellen) verweisen wir auf Run_Pretrained_Models.md für die Skripte für alle experimentellen Einstellungen.
Trimelm verwendet nur den lokalen Speicher (konstruiert mit Token im Eingang). Es kann als leichter Ersatz für Vanille -Langauge -Modelle angesehen werden.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10Argumente:
--use-local gibt die Verwendung des lokalen Speichers an.--softmax-temp gibt den Temperaturbegriff an, der bei der Berechnung des Verlusts verwendet wird.Trimelm_long verwendet während der Inferenz den lokalen Speicher und den Langzeitgedächtnis. Das Modell kann lange Kontexte nutzen, obwohl es mit kürzeren geschult ist.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01Argumente:
--use-long spezifiziert die Verwendung des Langzeitgedächtnisses.--mem-size gibt die Größe des lokalen + Langzeitgedächtnisses an.Trimelm_ext verwendet den lokalen Speicher, den Langzeitgedächtnis und den externen Speicher. Während der Inferenz führen wir das Modell auf dem Trainingssatz aus, um den externen Speicher zu erstellen, und verwenden die FAISS-Bibliothek, um den Index zum Abrufen von Top-K-Nachbarn den externen Speicher zu erstellen. Wir kalibrieren auch eine getrennte Verteilung über den Speicher und interpolieren die Ausgangsverteilung und die Speicherverteilung, ähnlich wie KNN-LM (siehe Details im Papier).
Wir laden zuerst den vorgebildeten Trimelm_ext herunter:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..Anschließend generieren wir den externen Speicher (Schlüssel und Werte) unter Verwendung des Trainingssatzes und erstellen dann den FAISS -Index:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipJetzt sind wir bereit, das Modell zu bewerten:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54Argumente:
--use-external gibt die Verwendung des externen Speichers an.--dstore-filename und indexfile Geben Sie den Datenspeicher und die Faiss-Indexpfade an.--use-interp legt die Verwendung einer linearen Interpolation zwischen zwei Verteilungen an, um die endgültige Wahrscheinlichkeit zu kalibrieren.--lmbda und --interp-temp geben den Temerpatur-Term und das Gewicht bei der Verwendung der linearen Interpolation an.Wir listen die Leistung der veröffentlichten vorgebildeten Modelle für Wikitext-103 und Enwik8 sowie deren Download-Links auf.
| Datensatz | Modell | Dev | Prüfen | Hyperparameter |
|---|---|---|---|---|
| Wikitext-103 | Trimelm (247m, L = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | Trimelm_long (247m, L = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | Trimelm_ext (247m, L = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | Trimelm (150 m, l = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | Trimelm_long (150 m, l = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| Enwik8 | Trimelm (38 m, L = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| Enwik8 | Trimelm_long (38 m, L = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
Wir verfolgen das Trainingsrezept von Fairseq (z. B. Optimierer, Lernrate, Chargengröße), um Trimelm zu trainieren. Anders verwenden wir unsere eigenen Verlustfunktionen (angegeben von --criterion ) und Daten -Batching -Methoden.
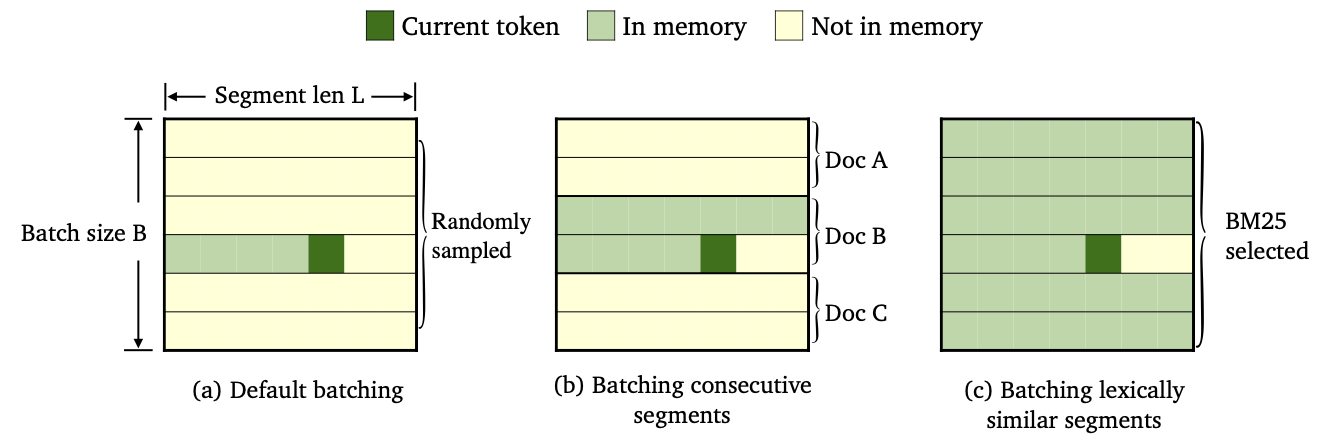
Wir haben drei Sorten von TRIMELM mit unterschiedlichen Datenanschlägen- und Speicherkonstruktionsmethoden ausgebildet.
--criterion trime_loss ausgebildet--criterion trime_long_loss_same_device --criterion trime_long_loss--keep-order ist erforderlich, um aufeinanderfolgende Segmente zu stapeln.trime_long_loss müssen wir die Speichergröße durch --train-mem-size angeben (num. Der aufeinanderfolgenden Segmente werden args.train_mem_size/args.tokens_per_sample sein).trime_long_loss_same_device gehen wir davon aus, dass alle aufeinanderfolgenden Segmente im selben GPU -Gerät geladen sind (äquivalent args.mem_size == args.max_tokens ). Die Verwendung trime_long_loss_same_device ist effizienter als die Verwendung von trime_long_loss , da weniger Cross-GPU-Kommunikation erforderlich ist.--criterion trime_ext_loss trainiert--predefined-batches angegeben.p deaktivieren wir den lokalen Speicher (dh nur Token aus anderen Segmenten, um Speicher zu konstruieren). Die Wahrscheinlichkeit p wird durch --cross-sent-ratio angegebenHier ist ein Beispiel für das Training eines Trimelm_Ext -Modells. Sie können alle Trainingsskripte finden, die wir in unseren Experimenten in Train_scripts verwendet haben.
Wir trainieren unsere Modelle auf 4 Nvidia RTX3090 GPUs.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonWichtige Argumente:
--arch gibt die Modellarchitektur an. In unseren Experimenten haben wir die folgenden Architekturen verwendet.transformer_lm_wiki103 (ein 247M-Modell für Wikitext-103)transformer_lm_wiki103_150M (ein 150-m-Modell für Wikitext-103)transformer_lm_enwik8 (ein 38 -m -Modell für Enwik8)--criterion gibt die Funktion zur Berechnung der Verlustwerte an. Siehe Beschreibung oben darüber, welche Funktionen wir unterstützen.--tokens-per-sample Gibt die Segmentlänge an.--max-tokens gibt die Anzahl der Token an, die in jeder GPU geladen werden sollen.--update-freq gibt die Gradienten-Akkumulationsschritte an.--ce-warmup-epoch gibt an, wie viele Epochen der ursprüngliche CE-Verlust zu Beginn zum Aufwärmen des Trainings verwendet wird.--cross-sent-ratio gibt die Wahrscheinlichkeit p an, den lokalen Speicher zu deaktivieren.--predefined-batches gibt den Dateipfad der vordefinierten Stapel an (wir verwenden BM25 bis Batch-Segmente). Beim Training des TRIMELM_EXT -Modells mit --criterion trime_ext_loss verwenden wir BM25 -Scores, um Trainingsdaten zu stapeln.
Wir verwenden die Pyserini -Bibliothek, um den BM25 -Index zu erstellen. Die Bibliothek kann über PIP installiert werden.
pip install pyserini Wir speichern zuerst alle Segmente vor dem Training, das in eine .json -Datei eingestellt ist.
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsDann erstellen wir den BM25 -Index mit Pyserini.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawAls nächstes suchen wir für jedes Trainingssegment die ähnlichen Segmente mit dem oben erstellten BM25 -Index.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).Schließlich erstellen wir basierend auf den Abrufergebnissen Stapel nach Gruppen ähnliche Segmente.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json Die Ausgabedatei wiki103-l3072-batches.json enthält eine Liste von Trainingssegmenten und benachbarten Segmenten sind wahrscheinlich ähnlich.
Die Batch-Datei wiki103-l3072-batches.json kann während des Trainings von trimelm_ext mit dem Argument --predefined-batches verwendet werden. Während des Trainings erhalten wir einfach Trainingsstapel, indem wir Sublisten sequenzell aus der Datei nehmen.
Für maschinelle Übersetzungscode und -versuche finden Sie das Unterverzeichnis.
Wenn Sie Fragen zu dem Code oder dem Papier haben oder bei der Verwendung des Codes Probleme begegnen, können Sie Zexuan Zhong ([email protected]) per E -Mail oder ein Problem eröffnen. Bitte versuchen Sie, das Problem mit Details anzugeben, damit wir Ihnen besser und schneller helfen können!
Wenn Sie unseren Code in Ihrer Forschung verwenden, zitieren Sie bitte unsere Arbeit:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}Unser Repo basiert auf Projekten Fairseq, KNNLM und Adaptive-KNN-MT. Wir danken den Autoren für das Open-Sourcing den großartigen Code!


