TRIME
1.0.0
これは、Zexuan Zhong、Tao Lei、およびDanqi ChenによるMemory Augmentationを備えたEMNLP2022ペーパートレーニング言語モデルのリポジトリです。
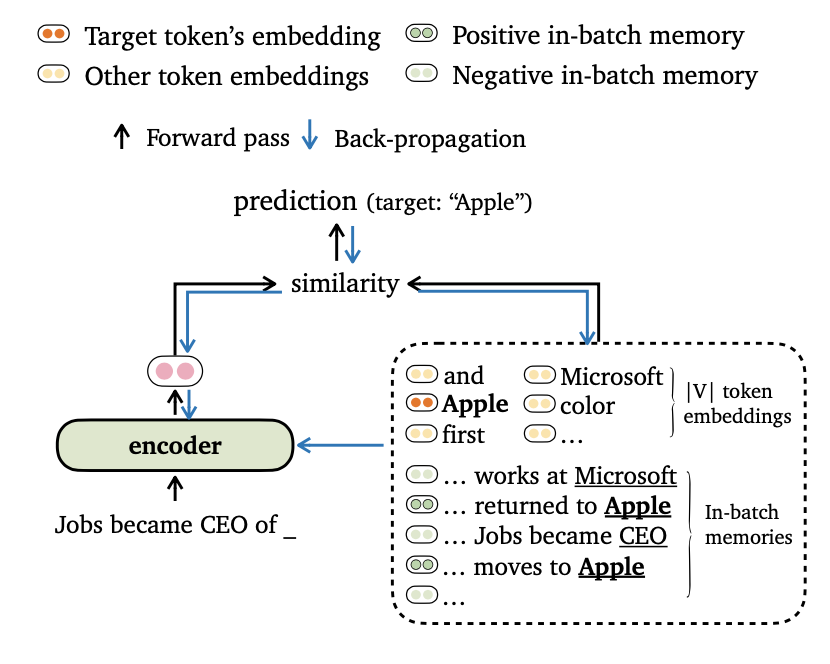
モデルの出力をトークン埋め込みとバッチ内のメモリの両方に合わせるための言語モデリングのための新しいトレーニング目標のTRIMEを提案します。また、モデルが長距離コンテキストと外部データストアを効果的に活用できるように、データバッチのバッチバッチとトレーニングメモリの構築の新しい方法を考案します。
私たちの論文でこの作品の詳細をご覧ください。
コードは、次の要件/依存関係に基づいています(ブラケットでの実験で使用したバージョンを指定します):
次のように(FairSeqに基づく)このプロジェクトをインストールできます。
pip install --editable .Wikitext-103およびENWIK8データセットで実験を実施します。 get_data.shを使用して、データセットをダウンロードして前処理してください。
bash get_data.sh {wikitext-103 | enwik8}処理されたデータセットはdata-bin/wikitext-103およびdata-bin/enwik8に保存されます。
モデルサイズ= 247mおよびセグメント長= 3072でWikitext-103で事前に訓練されたモデルを実行する例を示します。他の実験(例:異なるデータセットやモデルを使用)については、すべての実験設定のスクリプトについてrun_pretrained_models.mdを参照してください。
Trimelmはローカルメモリのみを使用します(入力内のトークンを使用して構築されています)。 Vanilla Langaugeモデルの軽量置換術と見なすことができます。
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10議論:
--use-localローカルメモリを使用して指定します。--softmax-temp損失を計算するときに使用される温度用語を指定します。Trimelm_longは、推論中にローカルメモリと長期メモリを使用します。モデルは長いコンテキストを活用することができますが、より短いコンテキストでトレーニングされています。
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01議論:
--use-long長期メモリを使用して指定します。--mem-sizeローカル +長期メモリのサイズを指定します。Trimelm_extは、ローカルメモリ、長期メモリ、および外部メモリを使用します。推論中に、トレーニングセットでモデルを実行して外部メモリを構築し、FAISSライブラリを使用してインデックスを構築して、Top-Kの最近隣人を外部メモリを取得するために構築します。また、メモリ上の分離分布を較正し、KNN-LMと同様に、出力分布とメモリ分布を補間します(論文の詳細を参照)。
最初に事前に訓練されたTrimelm_extをダウンロードします:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..次に、トレーニングセットを使用して外部メモリ(キーと値)を生成し、FAISSインデックスを作成します。
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipこれで、モデルを評価する準備ができました。
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54議論:
--use-external外部メモリを使用して指定します。--dstore-filenameおよびindexfileデータストアとFAISSインデックスパスを指定します。--use-interp 2つの分布間の線形補間を使用して最終的な確率を調整することを指定します。--lmbdaおよび--interp-temp線形補間を使用するときに温度項と重量を指定します。Wikitext-103とENWIK8でリリースされた事前訓練を受けたモデルのパフォーマンスと、そのダウンロードリンクをリストします。
| データセット | モデル | 開発者 | テスト | ハイパーパラメーター |
|---|---|---|---|---|
| wikitext-103 | トリメルム (247m、L = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| wikitext-103 | trimelm_long (247m、L = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| wikitext-103 | trimelm_ext (247m、L = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| wikitext-103 | トリメルム (150m、L = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| wikitext-103 | trimelm_long (150m、L = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | トリメルム (38m、l = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | trimelm_long (38m、l = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
FairSeqのトレーニングレシピ(例えば、オプティマイザー、学習率、バッチサイズ)に従って、Trimelmを訓練します。別の方法では、独自の損失関数( --criterionで指定)とデータバッチングメソッドを使用します。
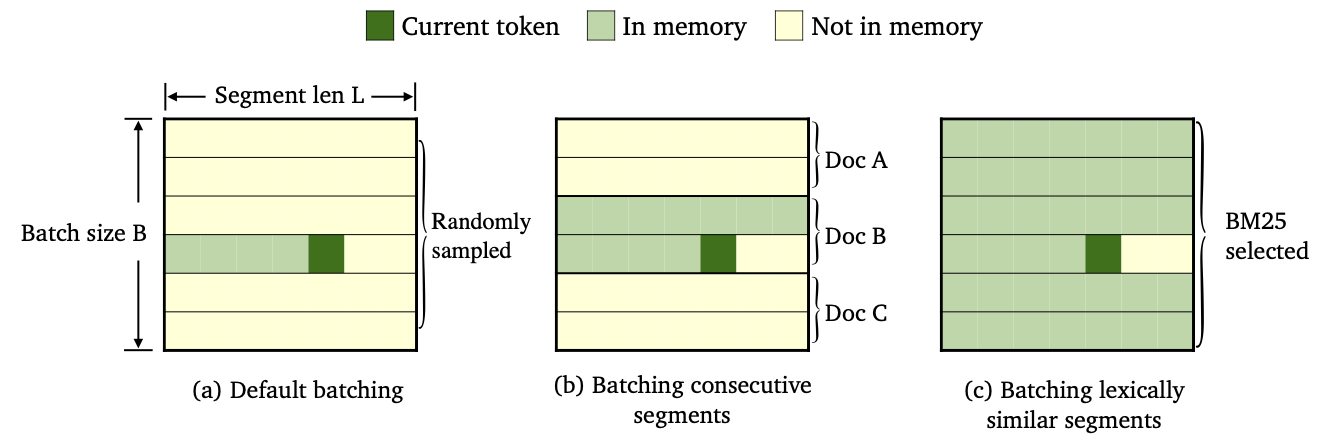
さまざまなデータバッチとメモリ構築方法を使用して、3種類のTrimelmを訓練しました。
--criterion trime_lossで訓練されています--criterion trime_long_lossまたは--criterion trime_long_loss_same_deviceでトレーニングされています--keep-orderが必要です。trime_long_loss args.train_mem_size/args.tokens_per_sample使用する場合、 --train-mem-sizeを介してメモリサイズを指定する必要があります。trime_long_loss_same_deviceを使用する場合、すべての連続したセグメントが同じGPUデバイス(同等にargs.mem_size == args.max_tokens )にロードされると仮定します。 trime_long_loss_same_deviceを使用すると、Cross-GPU通信が少ないため、 trime_long_lossを使用するよりも効率的です。--criterion trime_ext_lossでトレーニングされています--predefined-batchesによって指定されています。pでは、ローカルメモリを無効にします(つまり、他のセグメントのトークンのみを使用してメモリを構築します)。確率p --cross-sent-ratioで指定されていますTrimelm_extモデルのトレーニングの例を次に示します。 Train_scriptsで実験で使用したすべてのトレーニングスクリプトを見つけることができます。
4つのNVIDIA RTX3090 GPUでモデルをトレーニングします。
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.json重要な議論:
--archモデルアーキテクチャを指定します。実験では、次のアーキテクチャを使用しています。transformer_lm_wiki103 (wikitext-103の247mモデル)transformer_lm_wiki103_150M (wikitext-103の150mモデル)transformer_lm_enwik8 (enwik8の38mモデル)--criterion損失値を計算する関数を指定します。私たちがサポートする機能についての上記の説明を参照してください。--tokens-per-sampleセグメントの長さを指定します。--max-tokens各GPUにロードされるトークンの数を指定します。--update-freq勾配蓄積ステップを指定します。--ce-warmup-epochトレーニングをウォームアップするために、最初のCE損失が最初に使用されるエポーシュの数を指定します。--cross-sent-ratioローカルメモリを無効にする確率pを指定します。--predefined-batches事前定義されたバッチのファイルパスを指定します(BM25を使用してセグメントを使用します)。Trime_ext Modelを使用してTrimelm_extモデルをトレーニングするとき、 --criterion trime_ext_lossを使用すると、BM25スコアを使用してトレーニングデータをバッチします。
Pyseriniライブラリを使用して、BM25インデックスを構築します。ライブラリはPIP経由でインストールできます。
pip install pyserini最初に、トレーニングセットからすべてのセグメントを.jsonファイルに保存します。
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengths次に、Pyseriniを使用してBM25インデックスを構築します。
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRaw次に、トレーニングセグメントごとに、上記で構築したBM25インデックスを使用して同様のセグメントを検索します。
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).最後に、検索結果に基づいて、グループ類似セグメントごとにバッチを作成します。
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json出力ファイルwiki103-l3072-batches.jsonには、トレーニングセグメントのインデックスのリストが含まれており、隣接するセグメントは類似している可能性があります。
バッチファイルwiki103-l3072-batches.json 、Trimelm_extのトレーニング中に使用できます--predefined-batchesトレーニング中に、ファイルからサブリストを順番に取得することにより、単にトレーニングバッチを取得します。
機械翻訳コードと実験については、サブディレクトリをご覧ください。
コードや論文に関連する質問がある場合、またはコードを使用する際に問題が発生した場合は、Zexuan Zhong ([email protected])にメールするか、問題を開きます。私たちがあなたをより良く、より迅速に助けることができるように、詳細とともに問題を指定してみてください!
調査でコードを使用する場合は、私たちの作業を引用してください。
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}当社のレポは、FairSeq、KNNLM、およびAdaptive-KNN-MTプロジェクトに基づいています。優れたコードをオープンソーシングしてくれた著者に感謝します!


