TRIME
1.0.0
هذا هو المستودع لنماذج لغة التدريب على الورق EMNLP2022 مع زيادة الذاكرة ، بقلم Zexuan Zhong و Tao Lei و Danqi Chen.
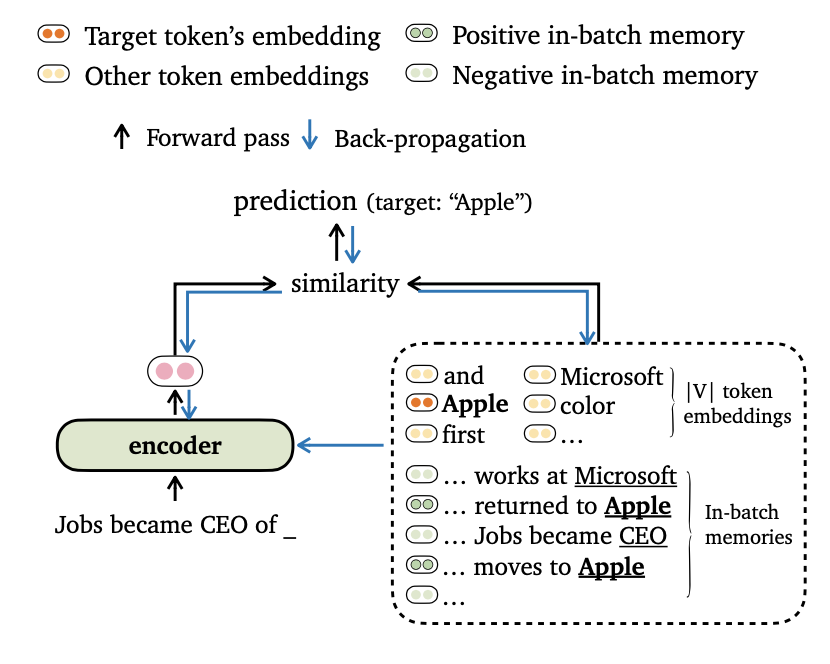
نقترح هدفًا جديدًا لتدريبًا لتدريبات النمذجة اللغوية ، والتي تتوافق مع مخرجات النموذج مع كل من التضمين الرمزي والذكريات في الدفعة . نضع أيضًا طرقًا جديدة لتكوين البيانات وبناء ذكريات التدريب ، بحيث يمكن للموديلات لدينا الاستفادة من السياقات بعيدة المدى وخزانة البيانات الخارجية بشكل فعال.
يرجى العثور على مزيد من التفاصيل عن هذا العمل في ورقتنا.
يعتمد الرمز على المتطلبات/التبعيات التالية (نحدد الإصدار الذي استخدمناه في تجاربنا بين قوسين):
يمكنك تثبيت هذا المشروع (استنادًا إلى FairSeq) على النحو التالي:
pip install --editable . نجري تجارب على مجموعات بيانات Wikitext-103 و ENWIK8 . يرجى استخدام get_data.sh لتنزيل مجموعات البيانات والمعالجة المسبقة.
bash get_data.sh {wikitext-103 | enwik8} سيتم تخزين مجموعات البيانات المعالجة في data-bin/wikitext-103 و data-bin/enwik8 .
نعرض أمثلة على تشغيل النماذج التي تم تدريبها مسبقًا على Wikitext-103 مع حجم النموذج = 247 متر وطول القطاع = 3072. للتجارب الأخرى (على سبيل المثال ، مع مجموعات بيانات أو نماذج مختلفة) ، نشير إلى Run_pretrained_models.md للبرامج النصية في جميع الإعدادات التجريبية.
يستخدم Trimelm الذاكرة المحلية فقط (تم إنشاؤها باستخدام الرموز في الإدخال). يمكن اعتباره بديلاً خفيف الوزن لنماذج الفانيليا لانجاو.
# download the pre-trained TrimeLM
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime.zip ;
unzip wiki103-247M-trime.zip ; rm -f wiki103-247M-trime.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --softmax-temp 1.17
# the following output is expected:
# Loss (base 2): 4.0962, Perplexity: 17.10الحجج:
--use-local باستخدام الذاكرة المحلية.--softmax-temp مصطلح درجة الحرارة المستخدمة عند حساب الخسارة.يستخدم Trimelm_Long الذاكرة المحلية والذاكرة طويلة الأجل أثناء الاستدلال. هذا النموذج قادر على الاستفادة من السياقات الطويلة ، على الرغم من أنه يتم تدريبه مع سياقات أقصر.
# download the pre-trained TRIME_long
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_long.zip ;
unzip wiki103-247M-trime_long.zip ; rm -f wiki103-247M-trime_long.zip
cd ..
# run evaluation
python eval_lm-trime.py data-bin/wikitext-103
--path pretrained_models/wiki103-247M-trime_long/checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.22
# the following output is expected:
# Loss (base 2): 4.0879, Perplexity: 17.01الحجج:
--use-long باستخدام الذاكرة طويلة الأجل.--mem-size حجم الذاكرة المحلية + طويلة الأجل.يستخدم Trimelm_ext الذاكرة المحلية والذاكرة طويلة الأجل والذاكرة الخارجية. أثناء الاستدلال ، نقوم بتشغيل النموذج على مجموعة التدريب لبناء الذاكرة الخارجية واستخدام مكتبة FAISS لإنشاء فهرس لاسترداد كبار الجيران الأقرب للذاكرة الخارجية. نقوم أيضًا بمعايرة توزيع منفصل على الذاكرة ونحقق توزيع الإخراج وتوزيع الذاكرة ، على غرار KNN-LM (انظر التفاصيل في الورقة).
نقوم أولاً بتنزيل trimelm_ext المدربين مسبقًا:
mkdir pretrained_models ; cd pretrained_models
wget https://nlp.cs.princeton.edu/projects/trime/pretrained_models/wiki103-247M-trime_ext.zip ;
unzip wiki103-247M-trime_ext.zip ; rm -f wiki103-247M-trime_ext.zip
cd ..بعد ذلك ، ننشئ الذاكرة الخارجية (المفاتيح والقيم) باستخدام مجموعة التدريب ثم إنشاء فهرس FAISS:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
# generate the external memory (keys and values) using the training set
python eval_lm.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode none --max-tokens 3072
--softmax-batch 1024 --gen-subset train
--context-window 2560 --tokens-per-sample 512
--dstore-mmap ${MODEL_PATH} /dstore --knn-keytype last_ffn_input
--dstore-size 103224461
--save-knnlm-dstore --fp16 --dstore-fp16
# build Faiss index
python build_dstore.py
--dstore_mmap ${MODEL_PATH} /dstore
--dstore_size 103224461 --dimension 1024
--faiss_index ${MODEL_PATH} /knn.index
--num_keys_to_add_at_a_time 500000
--starting_point 0 --dstore_fp16 --dist ipالآن ، نحن على استعداد لتقييم النموذج:
MODEL_PATH=pretrained_models/wiki103-247M-trime_ext
python eval_lm-trime.py data-bin/wikitext-103
--path ${MODEL_PATH} /checkpoint_best.pt
--sample-break-mode complete --max-tokens 3072 --context-window 2560
--softmax-batch 1024 --gen-subset valid --fp16
--max-sentences 1 --knn-keytype last_ffn_input
--use-local --use-long --mem-size 12288 --softmax-temp 1.25
--use-external --dstore-filename ${MODEL_PATH} /dstore --indexfile ${MODEL_PATH} /knn.index.ip
--probe 32 --dstore-fp16 --faiss-metric-type ip --no-load-keys --k 1024
--use-interp --interp-temp 10.5 --lmbda 0.3
# the following output is expected:
# Loss (base 2): 3.9580, Perplexity: 15.54الحجج:
--use-external باستخدام الذاكرة الخارجية.--dstore-filename و indexfile مسارات مخزن البيانات ومسارات فهرس FAISS.--use-interp--lmbda و --interp-temp حدد مصطلح temerpature والوزن عند استخدام الاستيفاء الخطي.ندرج أداء النماذج التي تم إصدارها مسبقًا على Wikitext-103 و Enwik8 ، بالإضافة إلى روابط التنزيل الخاصة بهم.
| مجموعة البيانات | نموذج | ديف | امتحان | المفردات المفرطة |
|---|---|---|---|---|
| Wikitext-103 | تريملم (247m ، L = 3072) | 17.10 | 17.76 | --softmax-temp 1.17 |
| Wikitext-103 | trimelm_long (247m ، L = 3072) | 17.01 | 17.64 | --softmax-temp 1.22 --mem-size 12288 |
| Wikitext-103 | trimelm_ext (247m ، L = 3072) | 15.54 | 15.46 | --softmax-temp 1.25 --mem-size 12288 --interp-temp 10.5 --lmbda 0.3 |
| Wikitext-103 | تريملم (150m ، L = 150) | 24.45 | 25.61 | --softmax-temp 1.03 |
| Wikitext-103 | trimelm_long (150m ، L = 150) | 21.76 | 22.62 | --softmax-temp 1.07 --mem-size 15000 |
| enwik8 | تريملم (38 م ، L = 512) | 1.14 | 1.12 | --softmax-temp 1.05 |
| enwik8 | trimelm_long (38 م ، L = 512) | 1.08 | 1.05 | --softmax-temp 1.10 --mem-size 24576 |
نتبع وصفة التدريب في Fairseq (على سبيل المثال ، محسن ، معدل التعلم ، حجم الدُفعة) لتدريب Trimelm. بشكل مختلف ، نستخدم وظائف الخسارة الخاصة بنا (المحددة بواسطة --criterion ) وطرق تكوين البيانات.
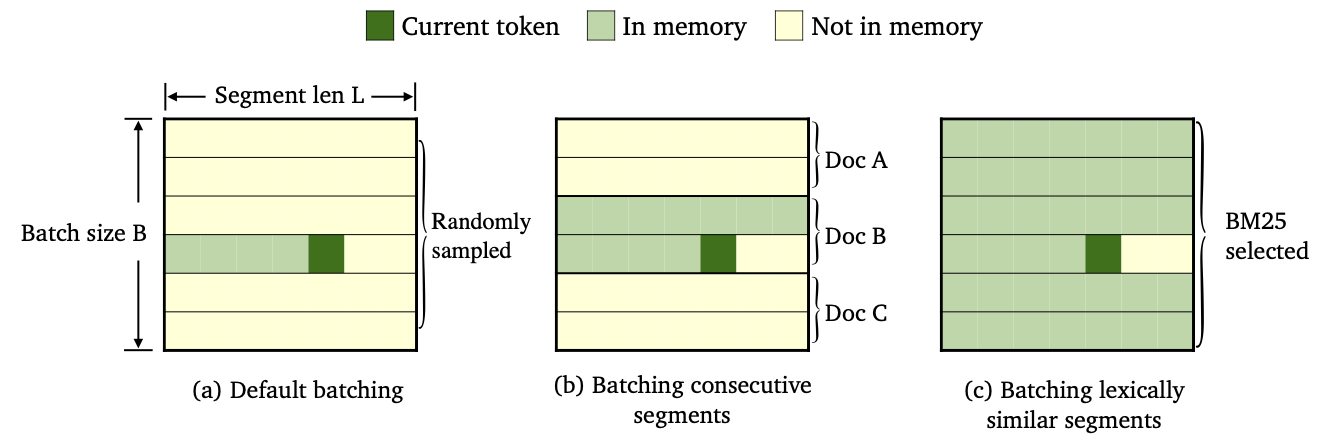
قمنا بتدريب ثلاثة أنواع من Trimelm باستخدام طرق مختلفة للبيانات وبناء الذاكرة.
--criterion trime_loss--criterion trime_long_loss أو --criterion trime_long_loss_same_device--keep-order لقياس الأجزاء المتتالية.trime_long_loss ، نحتاج إلى تحديد حجم الذاكرة من خلال --train-mem-size (num. من الأجزاء المتتالية سيكون args.train_mem_size/args.tokens_per_sample ).trime_long_loss_same_device ، نفترض أن يتم تحميل جميع الأجزاء المتتالية في نفس جهاز GPU ( args.mem_size == args.max_tokens بشكل مكافئ). باستخدام trime_long_loss_same_device أكثر كفاءة من استخدام trime_long_loss ، لأنه يتطلب اتصالات أقل عبر GPU.--criterion trime_ext_loss--predefined-batches .p ، نقوم بتعطيل الذاكرة المحلية (أي فقط باستخدام الرموز من قطاعات أخرى لبناء الذاكرة). تم تحديد probablity p بواسطة- --cross-sent-ratioفيما يلي مثال على تدريب نموذج trimelm_ext. يمكنك العثور على جميع البرامج النصية التدريبية التي استخدمناها في تجاربنا في Train_scripts.
نقوم بتدريب نماذجنا على 4 NVIDIA RTX3090 وحدات معالجة الرسومات.
# download the results of bm25 batching
wget https://nlp.cs.princeton.edu/projects/trime/bm25_batch/wiki103-l3072-batches.json -P data-bin/wikitext-103/
python train.py --task language_modeling data-bin/wikitext-103
--save-dir output/wiki103-247M-trime_ext
--arch transformer_lm_wiki103
--max-update 286000 --max-lr 1.0 --t-mult 2 --lr-period-updates 270000 --lr-scheduler cosine --lr-shrink 0.75
--warmup-updates 16000 --warmup-init-lr 1e-07 --min-lr 1e-09 --optimizer nag --lr 0.0001 --clip-norm 0.1
--criterion trime_ext_loss --max-tokens 3072 --update-freq 6 --tokens-per-sample 3072 --seed 1
--sample-break-mode none --skip-invalid-size-inputs-valid-test --ddp-backend=no_c10d --knn-keytype last_ffn_input --fp16
--ce-warmup-epoch 9 --cross-sent-ratio 0.9
--predefined-batches data-bin/wikitext-103/wiki103-l3072-batches.jsonحجج مهمة:
--arch العمارة النموذجية. في تجاربنا ، كنا نستخدم البنية التالية.transformer_lm_wiki103 (نموذج 247M لـ Wikitext-103)transformer_lm_wiki103_150M (نموذج 150M لـ Wikitext-103)transformer_lm_enwik8 (نموذج 38M لـ ENWIK8)--criterion الوظيفة لحساب قيم الخسارة. انظر الوصف أعلاه حول الوظائف التي ندعمها.--tokens-per-sample يحدد طول القطاع.--max-tokens يحدد عدد الرموز المراد تحميلها في كل وحدة معالجة الرسومات.--update-freq خطوات تراكم التدرج.--ce-warmup-epoch عدد الأحداث التي يتم استخدام خسارة CE الأصلية في البداية لتسخين التدريب.--cross-sent-ratio p تعطيل الذاكرة المحلية.--predefined-batches مسار الملف للدفعات المحددة مسبقًا (نستخدم BM25 لشرائح الدُفعات). عند تدريب نموذج trimelm_ext باستخدام --criterion trime_ext_loss ، نستخدم درجات BM25 لبيانات التدريب.
نستخدم مكتبة Pyserini لبناء فهرس BM25. يمكن تثبيت المكتبة عبر PIP.
pip install pyserini نقوم أولاً بحفظ جميع الأجزاء من التدريب في ملف .json .
mkdir -p bm25/wiki103-l3072/segments
CUDA_VISIBLE_DEVICES=0 python train.py --task language_modeling
data-bin/wikitext-103
--max-tokens 6144 --tokens-per-sample 3072
--arch transformer_lm_wiki103
--output-segments-to-file bm25/wiki103-l3072/segments/segments.json
# Modify --tokens-per-sample for different segment lengthsثم ، نقوم ببناء فهرس BM25 باستخدام Pyserini.
python -m pyserini.index.lucene
--collection JsonCollection
--input bm25/wiki103-l3072/segments
--index bm25/wiki103-l3072/bm25_index
--generator DefaultLuceneDocumentGenerator --threads 1
--storePositions --storeDocvectors --storeRawبعد ذلك ، لكل قطاع تدريب ، نبحث في الأجزاء المماثلة باستخدام فهرس BM25 الذي قمنا بإنشائه أعلاه.
python bm25_search.py
--index_path bm25/wiki103-l3072/bm25_index/
--segments_path bm25/wiki103-l3072/segments/segments.json
--results_path bm25/wiki103-l3072/bm25_results
# Use --num_shards and --shard_id; you can parallel the computation of NN search (e.g., --num_shards 20).أخيرًا ، استنادًا إلى نتائج الاسترجاع ، نقوم بإنشاء دفعات حسب مجموعة شرائح مماثلة.
python bm25_make_batches.py
--results_path bm25/wiki103-l3072/bm25_results
--batch_file data-bin/wikitext-103/wiki103-l3072-batches.json يحتوي ملف الإخراج wiki103-l3072-batches.json على قائمة من مؤشرات قطاعات التدريب والقطاعات المجاورة من المحتمل أن تكون متشابهة.
يمكن استخدام ملف الدُفعات wiki103-l3072-batches.json أثناء تدريب Trimelm_ext ، مع الوسيطة --predefined-batches . أثناء التدريب ، نحصل ببساطة على دفعات التدريب عن طريق أخذ قوائم فرعية من الملف.
للحصول على رمز الترجمة الآلي والتجارب ، يرجى مراجعة الدليل الفرعي.
إذا كانت لديك أي أسئلة تتعلق بالرمز أو الورقة ، أو واجهت أي مشاكل عند استخدام الكود ، فلا تتردد في إرسال بريد إلكتروني إلى Zexuan Zhong ([email protected]) أو فتح مشكلة. يرجى محاولة تحديد المشكلة مع التفاصيل حتى نتمكن من مساعدتك بشكل أفضل وأسرع!
إذا كنت تستخدم التعليمات البرمجية الخاصة بنا في بحثك ، فيرجى الاستشهاد بعملنا:
@inproceedings { zhong2022training ,
title = { Training Language Models with Memory Augmentation } ,
author = { Zhong, Zexuan and Lei, Tao and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2022 }
}يعتمد ريبو لدينا على مشاريع Fairseq و KNNLM و Adaptive-Knn-MT. نشكر المؤلفين على التعليم المفتوح الرمز العظيم!


