Revisit KNN
1.0.0
CCL2023紙的代碼和數據集重新調整K-NN,用於微調預訓練的語言模型。
我們的模型的架構可以看如下:
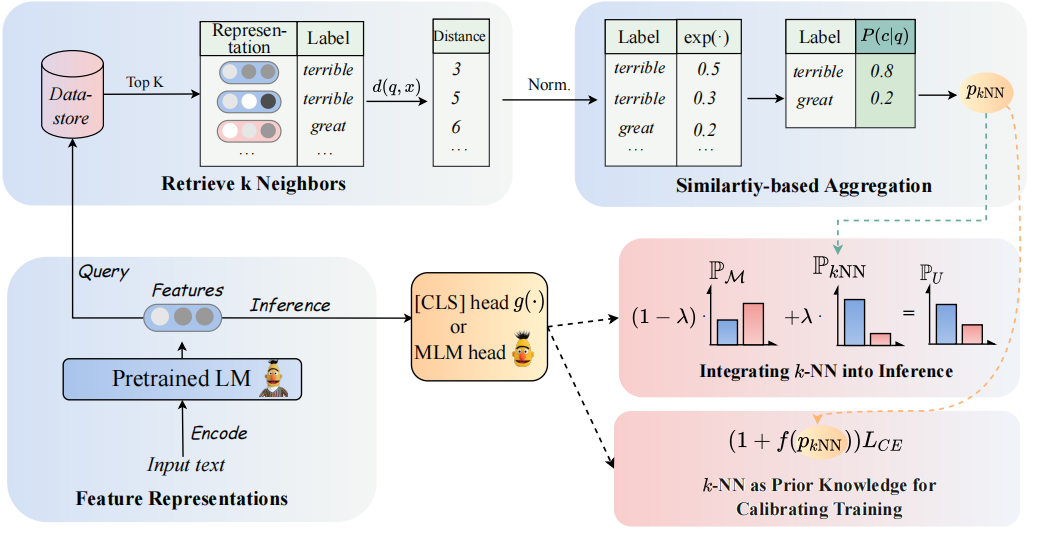
我們重新訪問K-NN分類器,以增強基於PLMS的分類器。具體而言,我們建議通過兩個步驟採用PLM的文本表示的K-NN:
(1)利用K-NN作為校準訓練過程的先驗知識。
(2)線性插值K-NN與PLMS分類器的分佈進行了預測。
我們方法的關鍵是引入K-NN指導培訓,該培訓將K-NN預測概率作為訓練期間的概率與辛苦示例的指示。我們分別在8個不同的終端任務中進行了有關微調和及時調整的廣泛實驗。
?注意:我們項目中有兩個主要文件夾。文件夾
GLUE_task包括六個單膠任務(SST-5,TREC,QNLI,MNLI,BOOLQ,CB),該文件夾RE_task包含兩個信息提取任務(Semeval,Tacrev)。
環境要求分別放置在GLUE_task和RE_task中。
pip install -r requirements.txt
膠水任務的環境要求和重新任務之間存在一些差異:
transformers的版本為4.11.3,而RE任務中的transformers版本為4.7。transformers框架的膠水任務,基於pytorch_lightning框架重新任務。 我們將GLUE的幾個數據數據放置在GLUE_task/data/training_data/k_shot文件夾中。原始的完整數據集可以在Glue網站上下載。您還可以按照以下命令運行以生成基於原始數據集的膠水任務的少量數據:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]使用下面的COMAND獲取用於培訓的答案單詞。
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semeval{words_words} .pt將保存在數據集中,您需要在get_label_word.py中分配model_name_or_path和dataset_name。
在幾個鏡頭的情況下,我們採用k=16 ,並採用3種不同的種子1, 2, 3 。少數數據將生成dataset/task_name/k-shot ,此外,您需要將驗證數據,測試數據和關係數據複製到少量數據路徑。
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1由於尺寸的限制,我們只提供了幾個數據。完整的數據可以在其原始論文中找到。
運行的SCIPT放置在GLUE_task/scripts中。有多個腳本:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
只需選擇一個腳本並運行以下命令:
cd GLUE_task
bash scripts/run_xxx.sh運行的SCIPT放置在RE_task/scripts中。還有多個腳本,例如膠水任務:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
只需選擇一個腳本並運行以下命令:
cd RE_task
bash scripts/run_xxx.sh如果使用代碼,請引用以下論文:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

