Revisit KNN
1.0.0
الكود ومجموعات البيانات الخاصة بورق CCL2023 إعادة النظر في K-NN لضبط نماذج اللغة المسبقة قبل التدريب.
يمكن رؤية بنية نموذجنا على النحو التالي:
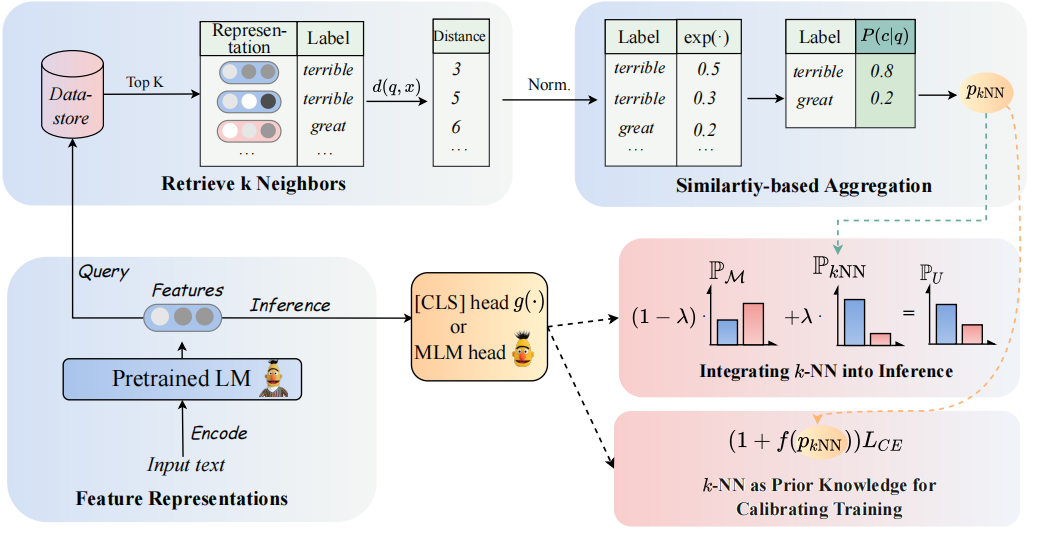
نقوم بإعادة النظر في المصنفات K-NN لزيادة المصنفات المستندة إلى PLMS. على وجه التحديد ، نقترح تبني K-NN مع تمثيلات نصية لـ PLMs في خطوتين:
(1) الاستفادة من K-NN باعتبارها المعرفة السابقة لمعايرة عملية التدريب.
(2) تداخل خطيا التوزيع المتوقع K-NN مع تصنيف PLMs.
مفتاح نهجنا هو إدخال التدريب الموجهة K-NN والذي يعتبر K-NN الاحتمالات المتوقعة كمؤشرات للأمثلة السهلة مقابل الصعبة أثناء التدريب. نقوم بإجراء تجارب واسعة النطاق على الضبط الدقيق والضبط السريع ، على التوالي ، عبر 8 مهام نهاية متنوعة.
؟ ملاحظة: هناك نوعان من مجلدات الملفات الرئيسية في مشروعنا. يتضمن المجلد
GLUE_taskست مهام غراء مفردة (SST-5 ، TREC ، QNLI ، MNLI ، BOOLQ ، CB) ، يتضمن المجلدRE_taskاستخراج المعلومات (Semeval ، Tacrev).
يتم وضع المتطلبات البيئية في GLUE_task و RE_task على التوالي.
pip install -r requirements.txt
هناك بعض الاختلافات بين المتطلبات البيئية لمهمة الغراء ومهمة إعادة:
transformers في مهمة الغراء هو 4.11.3 ، في حين أن إصدار transformers في مهمة Re هو 4.7.transformers من Huggingface ، إعادة المهمة بناءً على إطار pytorch_lightning . وضعنا بيانات قليلة من الغراء في مجلد GLUE_task/data/training_data/k_shot . يمكن تنزيل مجموعات البيانات الكاملة الأصلية على موقع Glue. يمكنك أيضًا تشغيل الأمر التالي لإنشاء بيانات قليلة من مهام الغراء بناءً على مجموعات البيانات الأصلية:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]استخدم COMAND أدناه للحصول على كلمات الإجابة لاستخدامها في التدريب.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semevalسيتم حفظ {approw_words} .PT في مجموعة البيانات ، تحتاج إلى تعيين model_name_or_path و dataset_name في get_label_word.py.
في سيناريو الطلقة القليلة ، نأخذ k=16 ونأخذ 3 بذور مختلفة من 1, 2, 3 . سيتم إنشاء بيانات قليلة إلى dataset/task_name/k-shot ، علاوة على ذلك ، تحتاج إلى نسخ بيانات التحقق من الصحة وبيانات الاختبار وبيانات العلاقة إلى مسار بيانات قليلة.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1بسبب قيود الحجم ، نقدم فقط بيانات القليل من اللقطة. يمكن العثور على البيانات الكاملة في أوراقها الأصلية.
يتم وضع الصدفة الجري في GLUE_task/scripts . هناك نصوص متعددة:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
فقط اختر نصًا واحدًا وتشغيله التالي:
cd GLUE_task
bash scripts/run_xxx.sh يتم وضع الصقور الجري في RE_task/scripts . هناك أيضًا نصوص متعددة مثل مهمة الغراء:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
فقط اختر نصًا واحدًا وتشغيله التالي:
cd RE_task
bash scripts/run_xxx.shإذا كنت تستخدم الرمز ، يرجى الاستشهاد بالورقة التالية:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

