Revisit KNN
1.0.0
Código y conjuntos de datos para el documento CCL2023 revisando K-NN para ajustar modelos de idiomas previamente capacitados.
La arquitectura de nuestro modelo se puede ver de la siguiente manera:
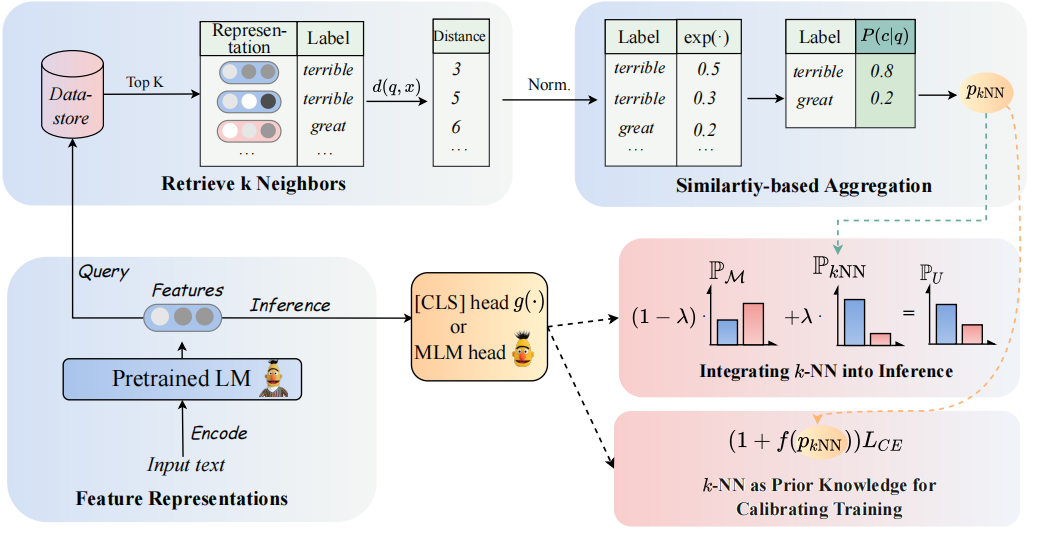
Revisamos los clasificadores K-NN para aumentar los clasificadores basados en PLMS. Específicamente, proponemos adoptar K-NN con representaciones textuales de PLM en dos pasos:
(1) Aproveche el K-NN como el conocimiento previo para calibrar el proceso de capacitación.
(2) Interpolar linealmente la distribución predicha K-NN con la del clasificador de PLMS.
La clave de nuestro enfoque es la introducción de la capacitación guiada de K-NN que considera que K-NN predijo las probabilidades como indicaciones para ejemplos fáciles versus difíciles durante el entrenamiento. Llevamos a cabo amplios experimentos sobre ajuste y ajuste rápido, respectivamente, en 8 tareas finales diversas.
? Nota: Hay dos carpetas de archivos principales en nuestro proyecto. La carpeta
GLUE_taskincluye seis tareas de pegamento único (SST-5, TREC, QNLI, MNLI, BOOLQ, CB), la carpetaRE_taskincluye dos tareas de extracción de información (Semeval, Tacrev).
Los requisitos ambientales se colocan en GLUE_task y RE_task respectivamente.
pip install -r requirements.txt
Existen algunas diferencias entre los requisitos ambientales de la tarea de pegamento y la tarea RE:
transformers en la tarea de pegamento es 4.11.3, mientras que la versión de transformers en la tarea RE es 4.7.transformers desde Huggingface, re tarea basada en el marco pytorch_lightning . Colocamos los datos de pocos disparos de pegamento en la carpeta GLUE_task/data/training_data/k_shot . Los conjuntos de datos completos originales se pueden descargar en el sitio web de Glue. También puede ejecutar el siguiente comando para generar los datos de pocos disparos de las tareas de pegamento en función de los conjuntos de datos originales:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]Use el COMAND a continuación para obtener las palabras de respuesta para usar en la capacitación.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semevalEl {respuestas_words} .pt se guardará en el conjunto de datos, debe asignar el model_name_or_path y DataSet_name en el get_label_word.py.
En el escenario de pocos disparos, tomamos k=16 y tomamos 3 semillas diferentes de 1, 2, 3 . Los datos de pocos disparos se generarán en dataset/task_name/k-shot , además, debe copiar los datos de validación, los datos de prueba y los datos de relación con la ruta de datos de pocos disparos.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1Debido a la limitación del tamaño, solo proporcionamos los datos de pocos disparos. Los datos completos se pueden encontrar en sus documentos originales.
Los scipts en ejecución se colocan en GLUE_task/scripts . Hay múltiples scripts:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
Simplemente elija un script y ejecute el siguiente comando:
cd GLUE_task
bash scripts/run_xxx.sh Los scipts en ejecución se colocan en RE_task/scripts . También hay múltiples scripts como la tarea de pegamento:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
Simplemente elija un script y ejecute el siguiente comando:
cd RE_task
bash scripts/run_xxx.shSi usa el código, cite el siguiente documento:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

