Revisit KNN
1.0.0
Code et ensembles de données pour le papier CCL2023 Revisitant K-NN pour les modèles de langage pré-formées à réglage fin.
L'architecture de notre modèle peut être considérée comme suit:
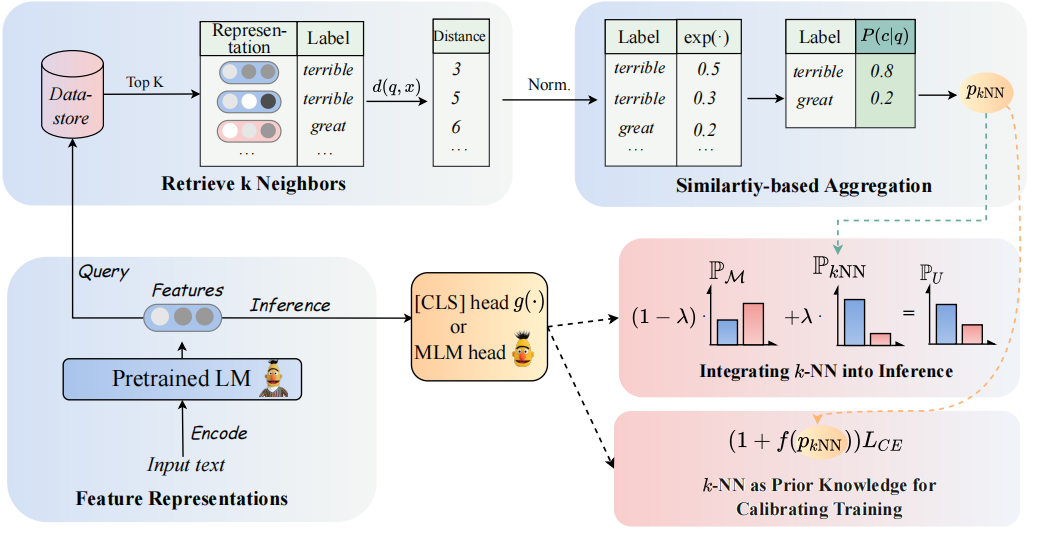
Nous revisitons les classificateurs K-NN pour augmenter les classificateurs basés sur PLMS. Plus précisément, nous proposons d'adopter K-NN avec des représentations textuelles de PLMS en deux étapes:
(1) Tirez parti du K-NN comme connaissance préalable pour calibrer le processus de formation.
(2) interpoler linéairement la distribution prédite K-NN avec celle du classificateur de PLMS.
La clé de notre approche est l'introduction d'une formation guidée par K-NN qui concerne K-NN les probabilités prédites comme indications pour des exemples faciles et difficiles pendant la formation. Nous effectuons des expériences approfondies sur le réglage fin et le réglage rapide, respectivement, dans 8 tâches finales diverses.
? Remarque: il y a deux dossiers de fichiers principaux dans notre projet. Le dossier
GLUE_taskcomprend six tâches de colle unique (SST-5, TREC, QNLI, MNLI, Boolq, CB), le dossierRE_taskcomprend deux tâches d'extraction d'informations (Semeval, Tacrev).
Les exigences environnementales sont placées respectivement dans GLUE_task et RE_task .
pip install -r requirements.txt
Il existe certaines différences entre les exigences environnementales de la tâche de colle et de la tâche:
transformers dans la tâche de colle est 4.11.3, tandis que la version des transformers dans la tâche RE est 4.7.transformers de HuggingFace, RE Tâche basée sur le cadre pytorch_lightning . Nous avons placé les données à quelques coups de Glue dans GLUE_task/data/training_data/k_shot . Les ensembles de données complets originaux peuvent être téléchargés sur le site Web de Glue. Vous pouvez également exécuter la commande suivante pour générer les données à quelques tirs des tâches de colle basées sur les ensembles de données d'origine:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]Utilisez le Comand ci-dessous pour obtenir les mots de réponse à utiliser dans la formation.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semevalLe {réponse_words} .t sera enregistré dans l'ensemble de données, vous devez attribuer le modèle_name_or_path et dataset_name dans le get_label_word.py.
Dans le scénario à quelques coups, nous prenons k=16 et prenons 3 graines différentes de 1, 2, 3 . Les données à quelques tirs seront générées pour dataset/task_name/k-shot , en outre, vous devez copier les données de validation, les données de test et les données de relation avec un chemin de données à quelques coups.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1En raison de la limitation de la taille, nous fournissons simplement les données à quelques coups. Les données complètes peuvent être trouvées dans leurs articles d'origine.
Les Scipts en cours d'exécution sont placés dans GLUE_task/scripts . Il y a plusieurs scripts:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
Choisissez simplement un script et exécutez la commande suivante:
cd GLUE_task
bash scripts/run_xxx.sh Les Scipts en cours d'exécution sont placés dans RE_task/scripts . Il existe également des scripts multiples comme la tâche de colle:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
Choisissez simplement un script et exécutez la commande suivante:
cd RE_task
bash scripts/run_xxx.shSi vous utilisez le code, veuillez citer l'article suivant:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

