Revisit KNN
1.0.0
Code und Datensätze für das CCL2023-Papier, das K-NN für feine abgebildete Sprachmodelle überprüft.
Die Architektur unseres Modells kann wie folgt gesehen werden:
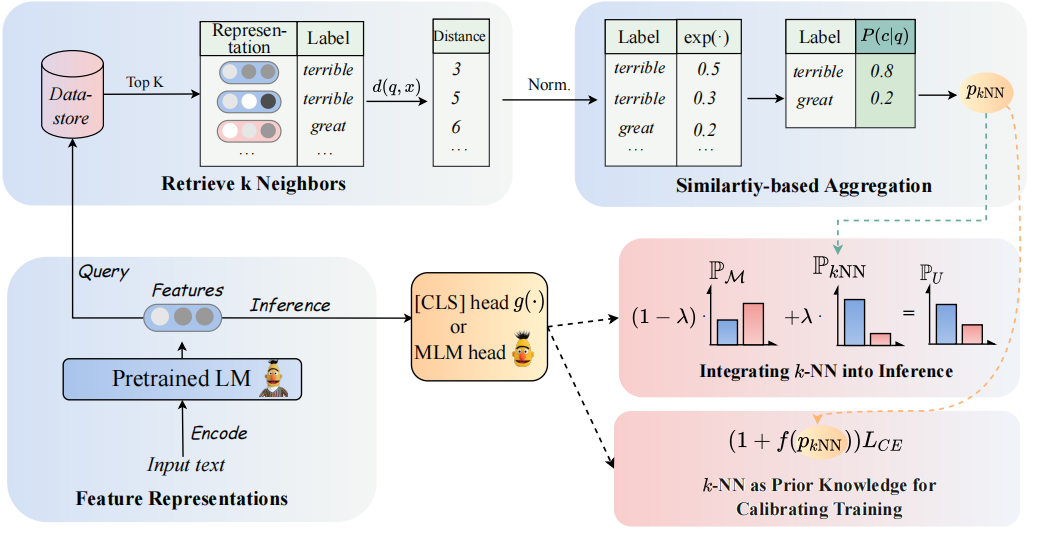
Wir besuchen K-NN-Klassifikatoren für die Erweiterung der PLMS-basierten Klassifikatoren. Insbesondere schlagen wir vor, K-nn in zwei Schritten mit textuellen Darstellungen von PLMs zu übernehmen:
(1) Nutzen Sie das K-NN als Vorkenntnis zur Kalibrierung des Trainingsprozesses.
(2) Interpolieren Sie die k-nn-vorhergesagte Verteilung linear mit der des Klassifizierers von PLMS.
Der Schlüssel zu unserem Ansatz ist die Einführung eines K-NN-geführten Trainings, das die vorhergesagten Wahrscheinlichkeiten als Indikationen für einfache und harte Beispiele während des Trainings betrachtet. Wir führen umfangreiche Experimente zur Feinabstimmung bzw. prompt-stunzig in 8 verschiedenen Endaufgaben durch.
? Hinweis: In unserem Projekt befinden sich zwei Hauptdateiordner. Der Ordner
GLUE_taskenthält sechs Einzelkleberaufgaben (SST-5, TREC, QNLI, MNLI, BOOLQ, CB). Der OrdnerRE_taskenthält zwei Aufgaben zur Extraktion von Informationen (Semeval, Tacrev).
Die Umgebungsanforderungen werden in GLUE_task bzw. RE_task aufgestellt.
pip install -r requirements.txt
Es gibt einige Unterschiede zwischen den Umweltanforderungen der Kleberaufgabe und der RE -Aufgabe:
transformers in der Kleberaufgabe ist 4.11.3, während die Version der transformers in der RE -Aufgabe 4.7 beträgt.transformers -Framework von Huggingface, RE -Aufgabe basierend auf dem Framework pytorch_lightning . Wir haben die wenigen Schussdaten von Klebstoff im Ordner von GLUE_task/data/training_data/k_shot platziert. Die ursprünglichen vollständigen Datensätze können auf der GLUE -Website heruntergeladen werden. Sie können auch den folgenden Befehl ausführen, um die wenigen Schussdaten von Kleberaufgaben basierend auf den ursprünglichen Datensätzen zu generieren:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]Verwenden Sie den Comand unten, um die Antwortwörter für das Training zu erhalten.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semevalDie {Answer_words} .PT werden im Datensatz gespeichert. Sie müssen die model_name_or_path und dataset_name im Get_Label_Word.py zuweisen.
In dem wenigen Shot-Szenario nehmen wir k=16 und nehmen 3 verschiedene Samen von 1, 2, 3 . Die wenigen Daten werden in dataset/task_name/k-shot generiert. Darüber hinaus müssen Sie die Validierungsdaten, Testdaten und Beziehungsdaten auf wenige Shot-Datenpfad kopieren.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1Aufgrund der Größenbeschränkung stellen wir nur die wenigen Daten zur Verfügung. Die vollständigen Daten finden Sie in ihren ursprünglichen Papieren.
Die laufenden Scipts werden in GLUE_task/scripts platziert. Es gibt Multi -Skripte:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
Wählen Sie einfach ein Skript aus und führen Sie den folgenden Befehl aus:
cd GLUE_task
bash scripts/run_xxx.sh Die laufenden Scipts werden in RE_task/scripts platziert. Es gibt auch Multi -Skripte wie Kleberaufgabe:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
Wählen Sie einfach ein Skript aus und führen Sie den folgenden Befehl aus:
cd RE_task
bash scripts/run_xxx.shWenn Sie den Code verwenden, zitieren Sie bitte das folgende Papier:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

