Revisit KNN
1.0.0
Código e conjuntos de dados para o papel CCL2023 Revisitando K-NN para modelos de idiomas pré-treinados de ajuste fino.
A arquitetura do nosso modelo pode ser vista da seguinte maneira:
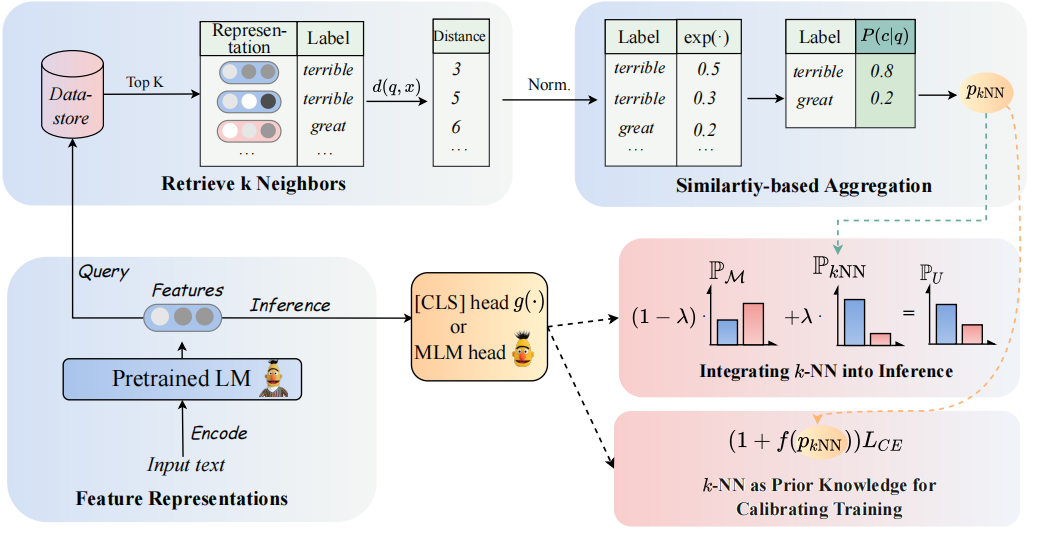
Revisitamos os classificadores da K-NN para aumentar os classificadores baseados em PLMs. Especificamente, propomos adotar o K-NN com representações textuais de PLMs em duas etapas:
(1) Aproveite o K-NN como o conhecimento prévio para calibrar o processo de treinamento.
(2) Interpolar linearmente a distribuição K-NN prevista com a do classificador de PLMs.
A chave para a nossa abordagem é a introdução do treinamento guiado da K-NN, que diz respeito à K-NN, as probabilidades previam como indicações para exemplos fáceis e difíceis durante o treinamento. Realizamos extensos experimentos sobre ajustes finos e ajustes, respectivamente, em 8 diversas tarefas finais.
? Nota: Existem duas pastas de arquivos principais em nosso projeto. A pasta
GLUE_taskinclui seis tarefas de cola única (SST-5, TREC, QNLI, MNLI, BOOLQ, CB), a pastaRE_taskinclui duas tarefas de extração de informações (semeval, tacrev).
Os requisitos ambientais são colocados em GLUE_task e RE_task respectivamente.
pip install -r requirements.txt
Existem algumas diferenças entre os requisitos ambientais da tarefa de cola e a tarefa de RE:
transformers na tarefa de cola é 4.11.3, enquanto a versão dos transformers na tarefa RE é 4.7.transformers da HuggingFace, RE Task com base na estrutura pytorch_lightning . Colocamos os poucos dados de cola na pasta GLUE_task/data/training_data/k_shot . Os conjuntos de dados completos originais podem ser baixados no site de cola. Você também pode executar o seguinte comando para gerar os dados de poucos tiro de tarefas de cola com base nos conjuntos de dados originais:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]Use o comand abaixo para obter as palavras de resposta para usar no treinamento.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semevalO {Answer_words} .pt será salvo no conjunto de dados, você precisa atribuir o modelo_name_or_path e o DATASET_NAME no get_label_word.py.
No cenário de poucos tiros, tomamos k=16 e pegamos 3 sementes diferentes de 1, 2, 3 . Os dados de poucos tiro serão gerados para dataset/task_name/k-shot , além disso, você precisa copiar os dados de validação, os dados de teste e os dados de relação com o caminho de dados de poucos tiro.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1Devido à limitação de tamanho, apenas fornecemos os dados de poucos anos. Os dados completos podem ser encontrados em seus artigos originais.
Os SCIPTs em execução são colocados em GLUE_task/scripts . Existem scripts múltiplos:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
Basta escolher um script e executar o seguinte comando:
cd GLUE_task
bash scripts/run_xxx.sh Os SCIPTs em execução são colocados em RE_task/scripts . Também existem scripts multi como tarefa de cola:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
Basta escolher um script e executar o seguinte comando:
cd RE_task
bash scripts/run_xxx.shSe você usar o código, cite o seguinte artigo:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

