Revisit KNN
1.0.0
미세 조정 된 언어 모델을위한 CCL2023 용지의 코드 및 데이터 세트.
우리 모델의 아키텍처는 다음과 같이 볼 수 있습니다.
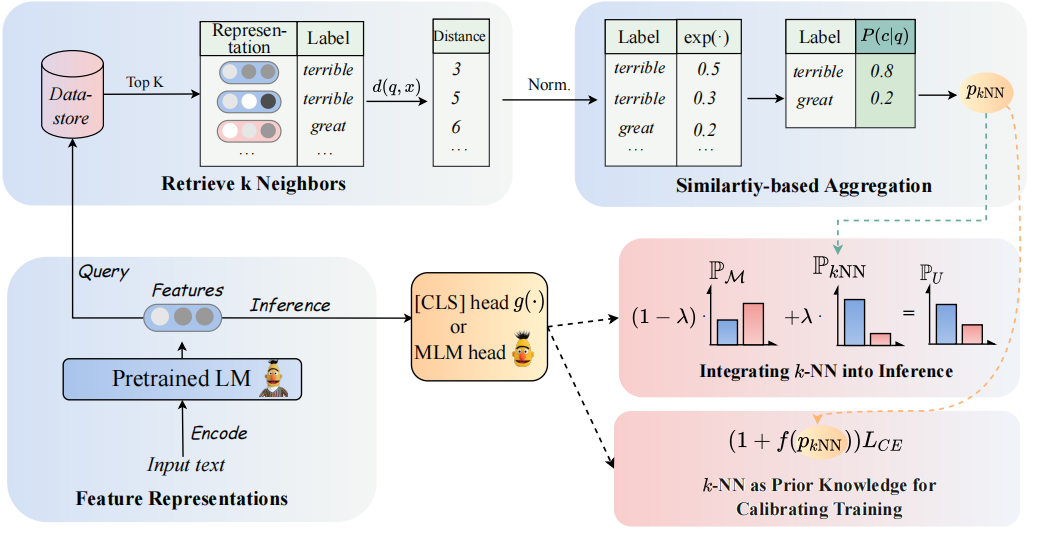
PLMS 기반 분류기를 증강시키기 위해 K-NN 분류기를 다시 방문합니다. 구체적으로, 우리는 PLM의 텍스트 표현으로 K-NN을 두 단계로 채택 할 것을 제안합니다.
(1) K-NN을 교육 프로세스를 교정하기위한 사전 지식으로 활용하십시오.
(2) K-NN 예측 분포를 PLM의 분류기의 선형 보간.
우리의 접근 방식의 핵심은 K-NN 예측 확률을 훈련 중 쉬운 예제에 대한 징후로 간주하는 K-NN 가이드 훈련의 도입입니다. 우리는 8 개의 다양한 엔드 작업에 걸쳐 미세 조정 및 프롬프트 조정에 대한 광범위한 실험을 수행합니다.
? 참고 : 프로젝트에는 두 개의 기본 파일 폴더가 있습니다. Folder
GLUE_task에는 6 개의 단일 접착제 작업 (SST-5, TREC, QNLI, MNLI, BOOLQ, CB)이 포함되어 있으며 폴더RE_task에는 두 가지 정보 추출 작업 (Semeval, Tacrev)이 포함됩니다.
환경 요구 사항은 각각 GLUE_task 및 RE_task 에 배치됩니다.
pip install -r requirements.txt
접착제 작업의 환경 요구 사항과 RE 작업에는 몇 가지 차이가 있습니다.
transformers 버전은 4.11.3이고 RE 작업의 transformers 버전은 4.7입니다.pytorch_lightning transformers 워크를 기반으로하는 Huggingf GLUE_task/data/training_data/k_shot 폴더에 접착제의 몇 가지 샷 데이터를 배치했습니다. 원래 전체 데이터 세트는 Glue 웹 사이트에서 다운로드 할 수 있습니다. 원래 데이터 세트를 기반으로 한 접착제 작업의 몇 가지 샷 데이터를 생성하기 위해 다음 명령을 실행할 수도 있습니다.
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]아래의 comand를 사용하여 교육에 사용할 답변 단어를 얻으십시오.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semeval{answer_words} .pt는 데이터 세트에 저장되므로 get_label_word.py에 model_name_or_path 및 dataset_name을 할당해야합니다.
소수의 샷 시나리오에서, 우리는 k=16 취하고 1, 2, 3 의 3 개의 다른 씨앗을 취합니다. 소수의 데이터는 dataset/task_name/k-shot 에 생성 될 것입니다. 또한 유효성 검사 데이터, 테스트 데이터 및 관계 데이터를 소수의 데이터 경로에 복사해야합니다.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1크기 제한으로 인해 소수의 데이터 만 제공합니다. 전체 데이터는 원래 논문에서 찾을 수 있습니다.
달리기 궤도는 GLUE_task/scripts 에 배치됩니다. 다중 스크립트가 있습니다.
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
하나의 스크립트를 선택하고 다음 명령을 따라 실행하십시오.
cd GLUE_task
bash scripts/run_xxx.sh 달리기 궤도는 RE_task/scripts 에 배치됩니다. 접착제 작업과 같은 다중 스크립트도 있습니다.
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
하나의 스크립트를 선택하고 다음 명령을 따라 실행하십시오.
cd RE_task
bash scripts/run_xxx.sh코드를 사용하는 경우 다음 논문을 인용하십시오.
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

