Revisit KNN
1.0.0
微調整前の訓練モデルのためにK-NNを再検討するCCL2023ペーパーのコードとデータセット。
モデルのアーキテクチャは次のように見ることができます。
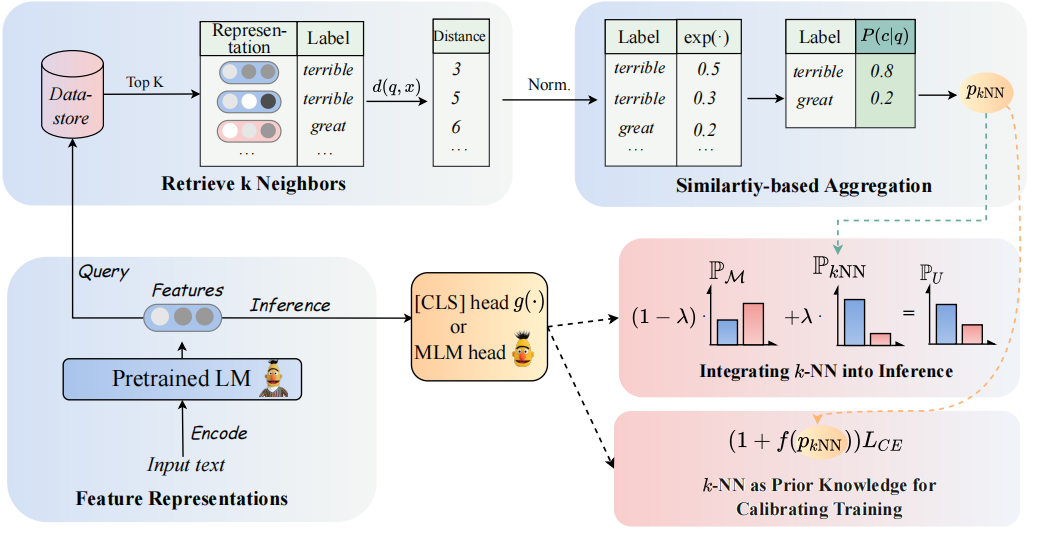
PLMSベースの分類子を拡張するために、K-NN分類器を再訪します。具体的には、2つのステップでPLMのテキスト表現を使用してK-NNを採用することを提案します。
(1)トレーニングプロセスを調整するための事前知識としてK-NNを活用します。
(2)K-NN予測分布をPLMSの分類器の分布と線形補間します。
私たちのアプローチの鍵は、K-NNが予測された確率をトレーニング中の簡単な例とハード例の適応と見なすK-NNガイド付きトレーニングの導入です。 8つの多様なエンドタスクで、それぞれ微調整と迅速な調整に関する広範な実験を実施しています。
?注:プロジェクトには2つのメインファイルフォルダーがあります。フォルダー
GLUE_taskには、6つの単一接着剤タスク(SST-5、TREC、QNLI、MNLI、BOOLQ、CB)が含まれており、フォルダーRE_taskは2つの情報抽出タスク(Semeval、Tacrev)が含まれています。
環境要件は、それぞれGLUE_taskとRE_taskに配置されています。
pip install -r requirements.txt
接着剤タスクの環境要件とREタスクの間にはいくつかの違いがあります。
transformersのバージョンは4.11.3で、REタスクのtransformersのバージョンは4.7です。pytorch_lightningフレームワークに基づいたREタスク、ハギングフェイスからのtransformersフレームワークに基づく接着タスク。 GLUE_task/data/training_data/k_shotフォルダーにGlueのいくつかのショットデータを配置しました。元の完全なデータセットは、Glue Webサイトからダウンロードできます。また、次のコマンドを実行して、元のデータセットに基づいて接着剤タスクの少数のデータを生成することもできます。
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]以下のコマンドを使用して、トレーニングで使用する回答語を取得します。
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semeval{Answer_Words} .ptはデータセットに保存されます。Get_label_word.pyにModel_name_or_pathとdataset_nameを割り当てる必要があります。
少ないショットシナリオでは、 k=16を採取し、 1, 2, 3の3つの異なる種子を採取します。少数のデータはdataset/task_name/k-shotに生成されます。さらに、検証データ、テストデータ、および関係データを少数のデータパスにコピーする必要があります。
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1規模の制限があるため、少数のデータを提供するだけです。完全なデータは、元の論文で見つけることができます。
実行中のSciptは、 GLUE_task/scriptsに配置されます。マルチスクリプトがあります:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
1つのスクリプトを選択して、次のコマンドを実行するだけです。
cd GLUE_task
bash scripts/run_xxx.sh実行中のSciptは、 RE_task/scriptsに配置されます。接着剤タスクのようなマルチスクリプトもあります:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
1つのスクリプトを選択して、次のコマンドを実行するだけです。
cd RE_task
bash scripts/run_xxx.shコードを使用する場合は、次の論文を引用してください。
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

