Revisit KNN
1.0.0
Kode dan kumpulan data untuk kertas CCL2023 yang meninjau kembali K-NN untuk menyempurnakan model bahasa pra-terlatih.
Arsitektur model kami dapat dilihat sebagai berikut:
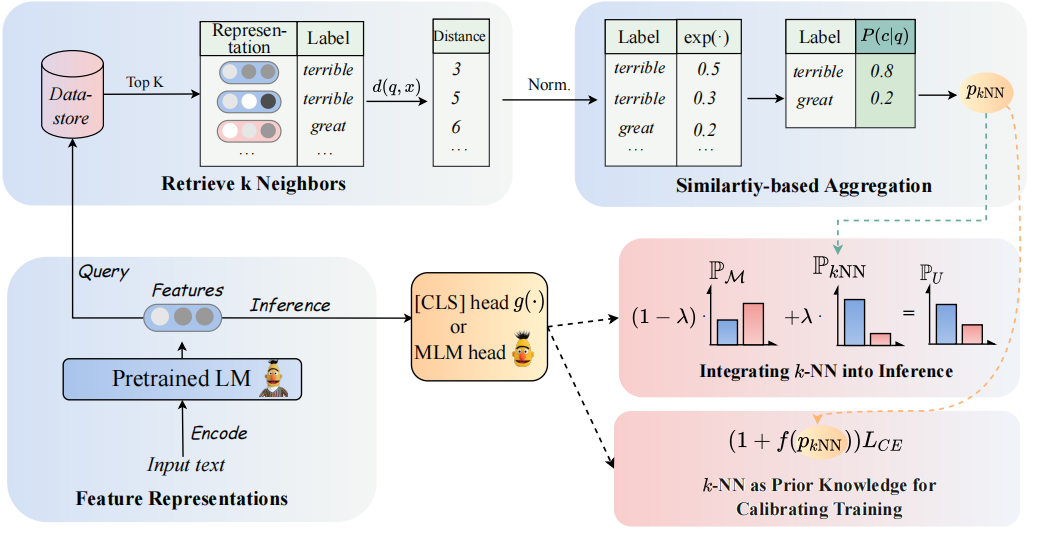
Kami meninjau kembali pengklasifikasi K-NN untuk menambah pengklasifikasi berbasis PLMS. Secara khusus, kami mengusulkan untuk mengadopsi K-NN dengan representasi tekstual PLM dalam dua langkah:
(1) Manfaatkan K-NN sebagai pengetahuan sebelumnya untuk mengkalibrasi proses pelatihan.
(2) secara linear interpolasi distribusi yang diprediksi K-NN dengan pengklasifikasi PLM.
Kunci dari pendekatan kami adalah pengenalan pelatihan yang dipandu K-NN yang berkaitan dengan probabilitas yang diprediksi K-NN sebagai indikasi untuk contoh yang mudah vs sulit selama pelatihan. Kami melakukan eksperimen ekstensif pada penyesuaian dan tuning yang cepat, masing-masing, di 8 tugas akhir yang beragam.
? Catatan: Ada dua folder file utama dalam proyek kami. Folder
GLUE_taskmencakup enam tugas lem tunggal (SST-5, TREC, QNLI, MNLI, BOOLQ, CB), folderRE_taskmencakup dua tugas ekstraksi informasi (Semeval, Tacrev).
Persyaratan lingkungan ditempatkan masing -masing di GLUE_task dan RE_task .
pip install -r requirements.txt
Ada beberapa perbedaan antara persyaratan lingkungan dari tugas lem dan tugas kembali:
transformers dalam tugas lem adalah 4.11.3, sedangkan versi transformers dalam tugas RE adalah 4.7.transformers dari Huggingface, Tugas RE berdasarkan kerangka pytorch_lightning . Kami menempatkan beberapa data lem dari lem di folder GLUE_task/data/training_data/k_shot . Dataset lengkap asli dapat diunduh di situs web lem. Anda juga dapat menjalankan perintah berikut untuk menghasilkan data beberapa-shot dari tugas lem berdasarkan dataset asli:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]Gunakan comand di bawah ini untuk mendapatkan kata -kata jawaban untuk digunakan dalam pelatihan.
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semeval{Ansages_words} .pt akan disimpan dalam dataset, Anda perlu menetapkan model_name_or_path dan dataset_name di get_label_word.py.
Dalam skenario beberapa tembakan, kami mengambil k=16 dan mengambil 3 biji berbeda dari 1, 2, 3 . Data beberapa-shot akan dihasilkan ke dataset/task_name/k-shot , terlebih lagi, Anda perlu menyalin data validasi, data uji dan data hubungan ke jalur data beberapa-shot.
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1Karena batasan ukurannya, kami hanya menyediakan data beberapa shot. Data lengkap dapat ditemukan di koran aslinya.
SCIPTS berjalan ditempatkan di GLUE_task/scripts . Ada multi skrip:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
Pilih saja satu skrip dan jalankan perintah berikut:
cd GLUE_task
bash scripts/run_xxx.sh SCIPTS berjalan ditempatkan di RE_task/scripts . Ada juga multi skrip seperti tugas lem:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
Pilih saja satu skrip dan jalankan perintah berikut:
cd RE_task
bash scripts/run_xxx.shJika Anda menggunakan kode, silakan mengutip makalah berikut:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

