Revisit KNN
1.0.0
รหัสและชุดข้อมูลสำหรับ CCL2023 Paper Revisiting K-NN สำหรับแบบจำลองภาษาที่ได้รับการฝึกอบรมล่วงหน้า
สถาปัตยกรรมของโมเดลของเราสามารถมองเห็นได้ดังนี้:
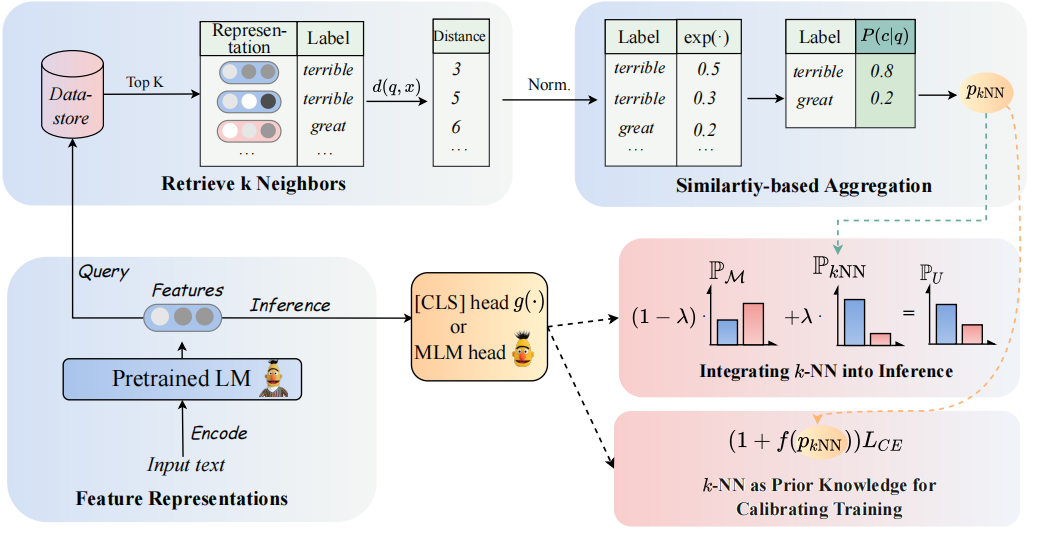
เราทบทวนตัวแยกประเภท K-NN เพื่อเพิ่มตัวแยกประเภทที่ใช้ PLMS โดยเฉพาะเราเสนอให้นำ K-NN มาใช้กับการเป็นตัวแทนข้อความของ PLMS ในสองขั้นตอน:
(1) ใช้ประโยชน์จาก K-NN เป็นความรู้ก่อนหน้านี้สำหรับการสอบเทียบกระบวนการฝึกอบรม
(2) การผสมผสานการกระจาย K-NN เชิงเส้นเป็นเส้นตรงกับตัวจําแนกของ PLMS
กุญแจสำคัญในแนวทางของเราคือการแนะนำการฝึกอบรมไกด์ K-NN ที่เกี่ยวกับความน่าจะเป็นที่คาดการณ์ไว้ K-NN เป็นตัวบ่งชี้สำหรับตัวอย่างที่ง่ายและยากในระหว่างการฝึกอบรม เราทำการทดลองอย่างกว้างขวางเกี่ยวกับการปรับแต่งและการปรับแต่งตามลำดับใน 8 งานที่หลากหลาย
- หมายเหตุ: มีสองโฟลเดอร์ไฟล์หลักในโครงการของเรา โฟลเดอร์
GLUE_taskประกอบด้วยงานกาวหกชิ้น (SST-5, TREC, QNLI, MNLI, BOOLQ, CB), โฟลเดอร์RE_taskรวมถึงงานสกัดข้อมูลสองรายการ (semeval, tacrev)
ข้อกำหนดด้านสิ่งแวดล้อมถูกวางไว้ใน GLUE_task และ RE_task ตามลำดับ
pip install -r requirements.txt
มีความแตกต่างบางประการระหว่างข้อกำหนดด้านสิ่งแวดล้อมของงานกาวและงาน RE:
transformers ในงานกาวคือ 4.11.3 ในขณะที่เวอร์ชันของ transformers ในงาน RE คือ 4.7transformers จาก HuggingFace งาน RE ตามเฟรมเวิร์ก pytorch_lightning เราวางข้อมูลการยิงสองสามครั้งของกาวในโฟลเดอร์ GLUE_task/data/training_data/k_shot ชุดข้อมูลเต็มรูปแบบดั้งเดิมสามารถดาวน์โหลดได้ที่เว็บไซต์กาว นอกจากนี้คุณยังสามารถเรียกใช้คำสั่งต่อไปนี้เพื่อสร้างข้อมูลการยิงสองสามครั้งของงานกาวตามชุดข้อมูลต้นฉบับ:
cd GLUE_task
python tools/generate_k_shot_data.py --k 16 --task SST-2 --seed [13, 42, 100]ใช้ comand ด้านล่างเพื่อรับคำตอบที่จะใช้ในการฝึกอบรม
cd RE_task
python get_label_word.py --model_name_or_path roberta-large-uncased --dataset_name semeval{answer_words} .pt จะถูกบันทึกไว้ในชุดข้อมูลคุณต้องกำหนด model_name_or_path และ dataset_name ใน get_label_word.py
ในสถานการณ์สองสามครั้งเราใช้ k=16 และใช้เมล็ดพันธุ์ที่แตกต่างกัน 3 ชนิดจาก 1, 2, 3 ข้อมูลไม่กี่นัดจะถูกสร้างขึ้นไปยัง dataset/task_name/k-shot นอกจากนี้คุณต้องคัดลอกข้อมูลการตรวจสอบข้อมูลทดสอบและข้อมูลความสัมพันธ์กับเส้นทางข้อมูลไม่กี่ตัว
cd RE_task
python generate_k_shot.py --data_dir ./dataset --k 16 --dataset semeval
cd dataset
cd semeval
cp rel2id.json val.txt test.txt ./k-shot/16-1เนื่องจากข้อ จำกัด ขนาดเราจึงให้ข้อมูลไม่กี่ครั้ง ข้อมูลเต็มสามารถพบได้ที่เอกสารต้นฉบับ
Scipts ที่กำลังทำงานอยู่ใน GLUE_task/scripts มีหลายสคริปต์:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer based on the mdoel checkpoints of pt and ft.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # PT / FT in zero-shot setting.
run_ssl_exp_infer.sh # UNION_infer in zero-shot setting.
run_ssl_exp_train.sh # UNION_all in zero-shot setting.
เพียงแค่เลือกหนึ่งสคริปต์และเรียกใช้คำสั่งต่อไปนี้:
cd GLUE_task
bash scripts/run_xxx.sh Scipts ที่กำลังทำงานอยู่ใน RE_task/scripts นอกจากนี้ยังมีสคริปต์หลายอย่างเช่นงานกาว:
run_exp.sh # PT / FT: prompt-tuning or fine-tuning without knn.
run_knn_infer_exp.sh # UNION_infer: pt or ft with knn infer.
run_knn_train_exp.sh # UNION_all: pt or ft with knn train and knn infer.
run_ssl_exp.sh # Zero-shot setting.
เพียงแค่เลือกหนึ่งสคริปต์และเรียกใช้คำสั่งต่อไปนี้:
cd RE_task
bash scripts/run_xxx.shหากคุณใช้รหัสโปรดอ้างอิงกระดาษต่อไปนี้:
@article { DBLP:journals/corr/abs-2304-09058 ,
author = { Lei Li and
Jing Chen and
Bozhong Tian and
Ningyu Zhang } ,
title = { Revisiting k-NN for Fine-tuning Pre-trained Language Models } ,
journal = { CoRR } ,
volume = { abs/2304.09058 } ,
year = { 2023 } ,
url = { https://doi.org/10.48550/arXiv.2304.09058 } ,
doi = { 10.48550/arXiv.2304.09058 } ,
eprinttype = { arXiv } ,
eprint = { 2304.09058 } ,
timestamp = { Tue, 02 May 2023 16:30:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2304-09058.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}

