qa lora
1.0.0
Qa-Lora已被ICLR 2024接受!
該存儲庫提供了QA-LORA的官方Pytorch實施:大型語言模型的量化低級別適應。
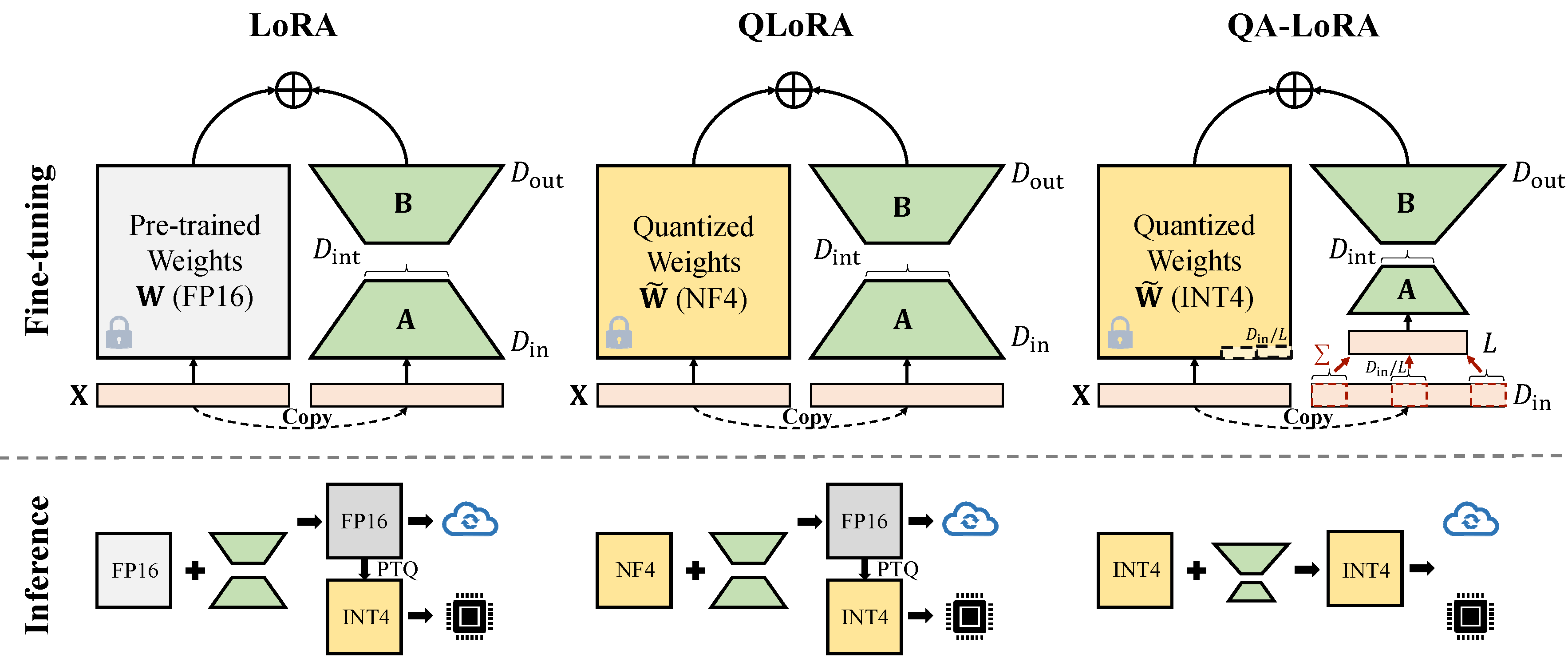
Qa-Lora可以輕鬆地使用幾行代碼實現,並且它使原始Lora具有兩倍的能力:(i)在微調期間,LLM的權重量化(例如,將其定量為INT4),以減少時間和內存使用; (ii)微調後,LLM和輔助權重自然地集成到量化模型中而不會損失精度。
使用最新的自動GPTQ版本來修復衝突。
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. *使用新的peft_utils.py 。對於GPTQlora的用戶,您只需要更改peft_utils.py文件即可。
我們使用GPTQ進行量化。位= 4,組大小= 32,act-order = false如果更改組大小,則需要相應地更改peft_utils.py中的merge.py 。
python qalora.py --model_path < path >模型檢查點的文件結構如下:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
請注意,我們訓練的洛拉模塊可以完美合併到量化的模型中。我們在此存儲庫中提供了一個簡單的合併腳本。
減少尺寸有兩種實現(x從d_in到d_in // l)。兩者都是數學等效的。
採用AVGPooling操作。但是,在合併期間,適配器的權重將由d_in // l分配(請參閱merge.py )。
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]利用總和操作。合併期間,適配器不需要分開)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]一些GPTQ實施(例如GPTQ為for-lalama)進一步將零壓縮到Qzeros中。您需要先解碼Qzeros並恢復FP16格式零。
我們的代碼基於Qlora,gptqlora,auto-gptq


