qa lora
1.0.0
QA-Lora wurde von ICLR 2024 akzeptiert!
Dieses Repository bietet die offizielle Pytorch-Implementierung von QA-LORA: quantisierungsbewusstes niedrigem Anpassung von Großsprachenmodellen.
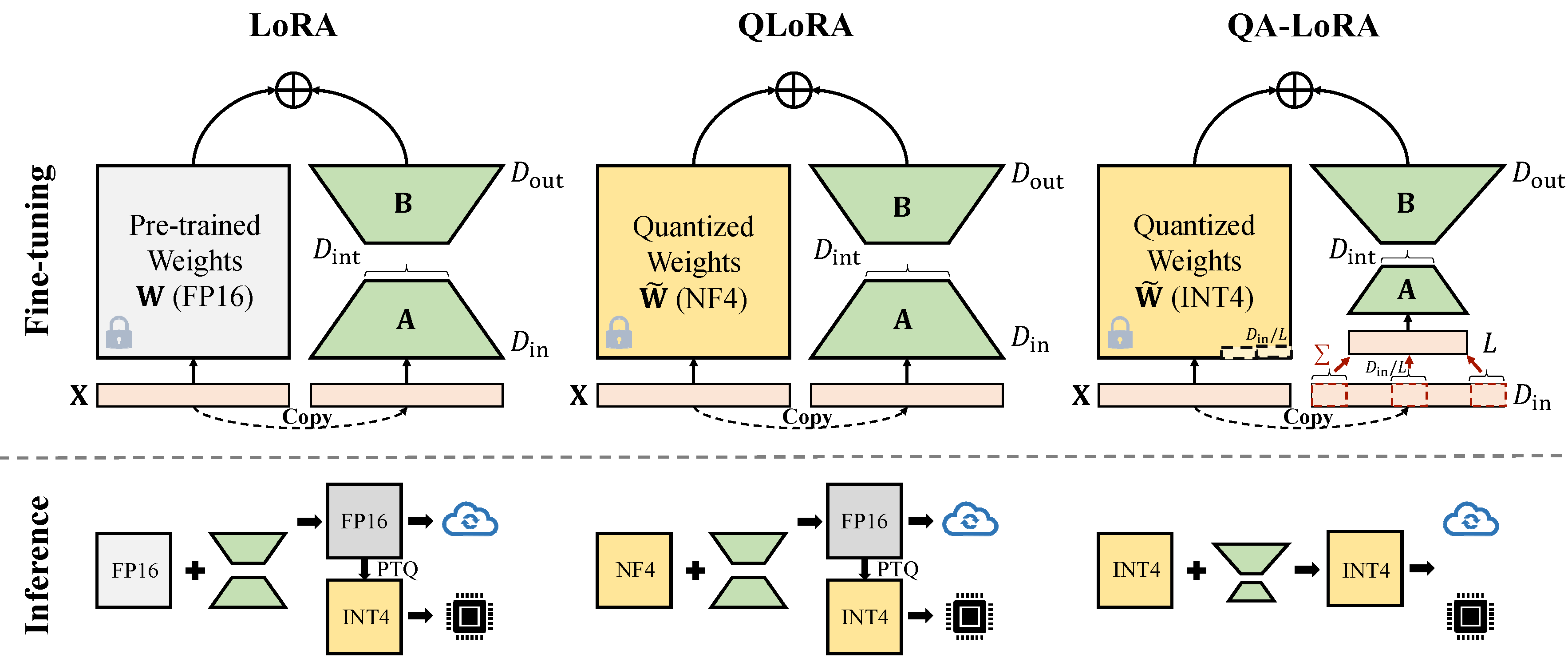
QA-Lora kann leicht mit einigen Codezeilen implementiert werden und vergleichbar mit zweifachen Fähigkeiten: (i) Während der Feinabstimmung werden die LLM-Gewichte (z. B. in INT4) quantisiert (z. (ii) Nach der Feinabstimmung werden die LLM- und Hilfsgewichte natürlich ohne Genauigkeitsverlust in ein quantisiertes Modell integriert.
Beheben Sie den Konflikt mit der neuesten Auto-GPTQ-Version.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * Ändern Sie die peft_utils.py in Ihrem eigenen Auto-GPTQ-Pfad (Python Path/Auto_GPTQ/utils/peft_utils.py) mit dem neuen. Für die Benutzer von GPTQlora müssen Sie nur die Datei peft_utils.py ändern.
Wir verwenden GPTQ zur Quantisierung. Bits = 4, Gruppengröße = 32, act-ordentlich = false Wenn Sie die Gruppengröße ändern, müssen Sie die Group_Size in peft_utils.py und merge.py entsprechend ändern.
python qalora.py --model_path < path >Die Dateistruktur des Modell -Checkpoint lautet wie folgt:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
Beachten Sie, dass unsere ausgebildeten Lora -Module perfekt in das quantisierte Modell verschmolzen werden können. Wir bieten in diesem Repo ein einfaches fusioniertes Skript an.
Es gibt zwei Arten von Implementierungen der Dimensionsreduzierung (x von d_in zu d_in // l). Beide sind mathematisches Äquivalent.
Avgpooling -Operation adoptieren. Die Gewichte der Adapter werden jedoch während der Zusammenführung durch d_in // l geteilt (siehe merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]Summenoperation verwenden. Die Adapter müssen während der Zusammenführung nicht geteilt werden)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]Einige GPTQ-Implementierungen wie GPTQ-for-Llama komprimieren die Nullen weiter in Qzeros. Sie müssen zuerst die Qzeros dekodieren und FP16 -Format -Nullen wiederherstellen.
Unser Code basiert auf Qlora, gptqlora, Auto-gptq


