qa lora
1.0.0
QA-Lora telah diterima oleh ICLR 2024!
Repositori ini memberikan implementasi Pytorch resmi QA-Lora: Kuantisasi-sadar adaptasi peringkat rendah dari model bahasa besar.
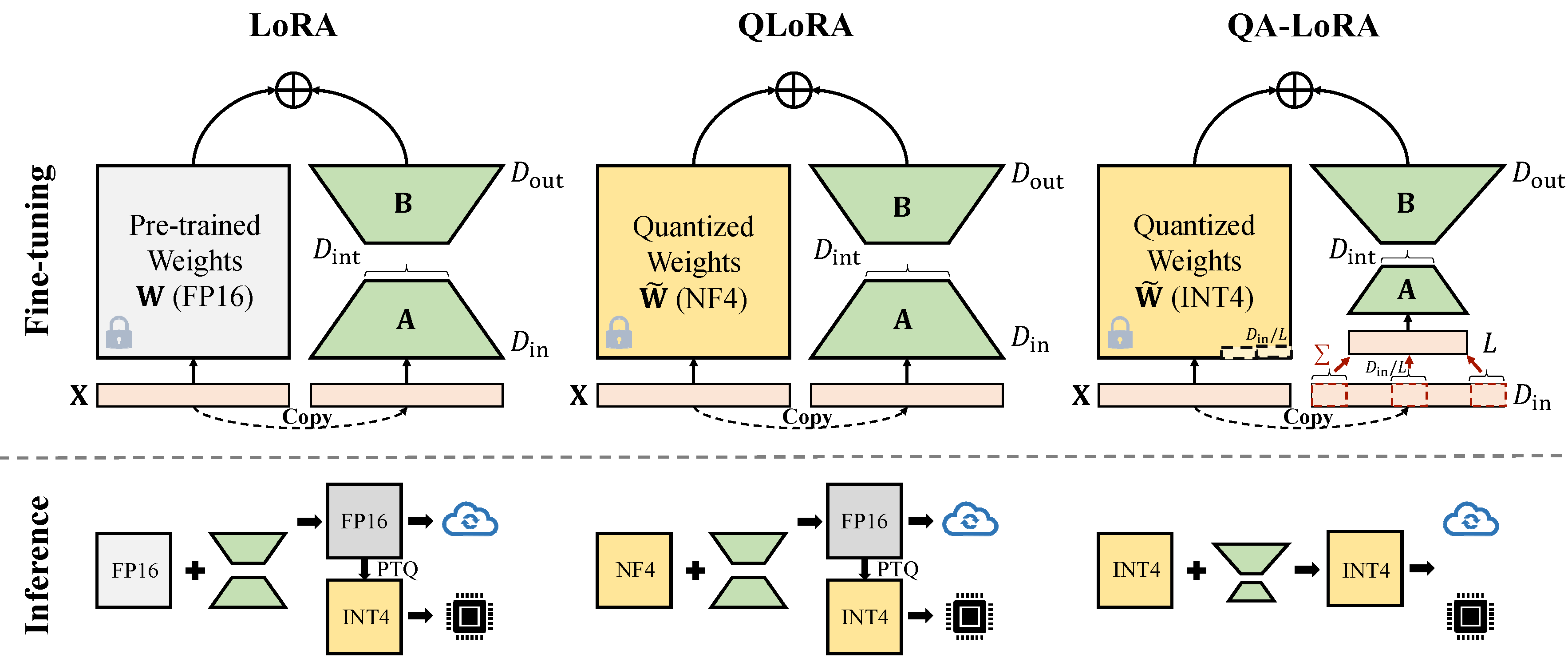
QA-Lora mudah diimplementasikan dengan beberapa baris kode, dan melengkapi LORA asli dengan kemampuan dua kali lipat: (i) selama penyesalan, bobot LLM dikuantisasi (misalnya, ke dalam INT4) untuk mengurangi waktu dan penggunaan memori; (ii) Setelah penyempurnaan, LLM dan bobot tambahan secara alami diintegrasikan ke dalam model yang dikuantisasi tanpa kehilangan akurasi.
Perbaiki konflik dengan versi Auto-GPTQ terbaru.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * Ubah peft_utils.py di jalur Auto-GPTQ Anda sendiri (Python Path/auto_gptq/utils/peft_utils.py) dengan yang baru. Untuk pengguna Gptqlora, Anda hanya perlu mengubah file peft_utils.py .
Kami menggunakan GPTQ untuk kuantisasi. bit = 4, ukuran grup = 32, ACT-order = false Jika Anda mengubah ukuran grup, Anda perlu mengubah grup_size di peft_utils.py dan merge.py sesuai.
python qalora.py --model_path < path >Struktur file dari pos pemeriksaan model adalah sebagai berikut:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
Perhatikan bahwa modul Lora kami yang terlatih dapat digabungkan dengan sempurna ke dalam model terkuantisasi. Kami menawarkan skrip gabungan sederhana dalam repo ini.
Ada dua jenis implementasi pengurangan dimensi (x dari d_in ke d_in // l). Keduanya setara matematika.
Mengadopsi operasi avgpooling. Tetapi bobot adaptor akan dibagi dengan d_in // l selama penggabungan (lihat merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]Memanfaatkan operasi jumlah. Adaptor tidak perlu dibagi selama penggabungan)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]Beberapa implementasi GPTQ seperti GPTQ-untuk-llama lebih lanjut mengompres nol ke qzeros. Anda perlu memecahkan kode qzeros terlebih dahulu dan mengembalikan format fp16 nol.
Kode kami didasarkan pada qlora, gptqlora, auto-gptq


