qa lora
1.0.0
¡Qa-lora ha sido aceptado por ICLR 2024!
Este repositorio proporciona la implementación oficial de Pytorch de QA-lora: adaptación de bajo rango de cuantificación de modelos de idiomas grandes.
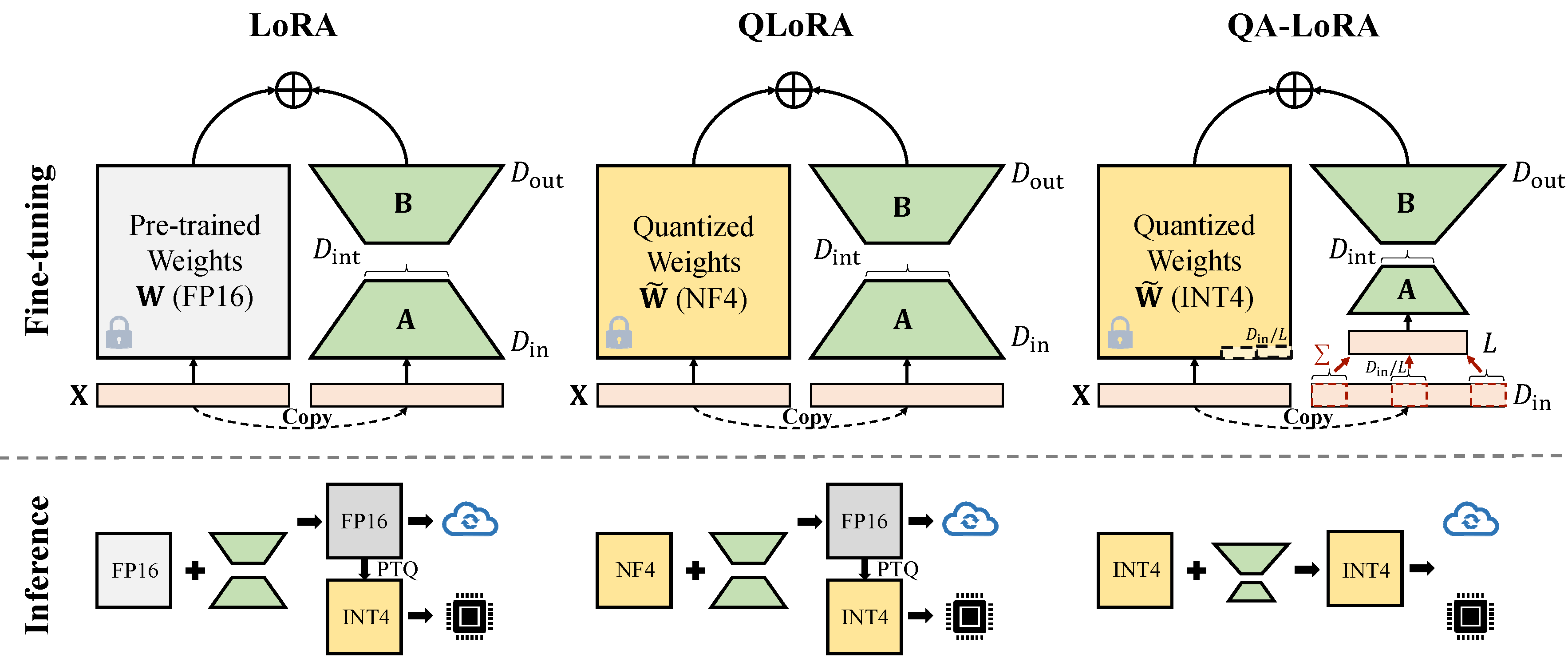
Qa-Lora se implementa fácilmente con algunas líneas de código, y equipa el Lora original con habilidades dobles: (i) Durante el ajuste fino, los pesos de la LLM se cuantifican (por ejemplo, INT4) para reducir el uso del tiempo y la memoria; (ii) Después del ajuste fino, el LLM y los pesos auxiliares se integran naturalmente en un modelo cuantificado sin pérdida de precisión.
Arregle el conflicto con la nueva versión Auto-GPTQ.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * Cambie el peft_utils.py en su propia ruta automática (python ruta/auto_gptq/utils/peft_utils.py) con la nueva. Para los usuarios de Gptqlora, solo necesita cambiar el archivo peft_utils.py .
Usamos GPTQ para cuantización. bits = 4, grupo de grupo = 32, ACT-orden = falso Si cambia el tamaño de grupo, debe cambiar el grupo_size en peft_utils.py y merge.py en consecuencia.
python qalora.py --model_path < path >La estructura del archivo del punto de control del modelo es la siguiente:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
Tenga en cuenta que nuestros módulos Lora capacitados se pueden fusionar perfectamente en el modelo cuantificado. Ofrecemos un simple script fusionado en este repositorio.
Hay dos tipos de implementaciones de la reducción de dimensiones (x de d_in a d_in // l). Ambos son equivalentes matemáticos.
Adoptar la operación AVGPooling. Pero los pesos de los adaptadores se dividirán por d_in // l durante la fusión (consulte merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]Utilice la operación de suma. Los adaptadores no necesitan dividirse durante la fusión)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]Algunas implementación de GPTQ, como GPTQ-for-Llama, comprimen aún más los ceros en Qzeros. Debe decodificar primero los Qzeros y restaurar los ceros de formato FP16.
Nuestro código se basa en Qlora, Gptqlora, Auto-GPTQ


