qa lora
1.0.0
Qa-Lora был принят ICLR 2024!
Этот репозиторий обеспечивает официальную внедрение Pytorch of Qa-Lora: квантование с низкой адаптацией крупных языковых моделей.
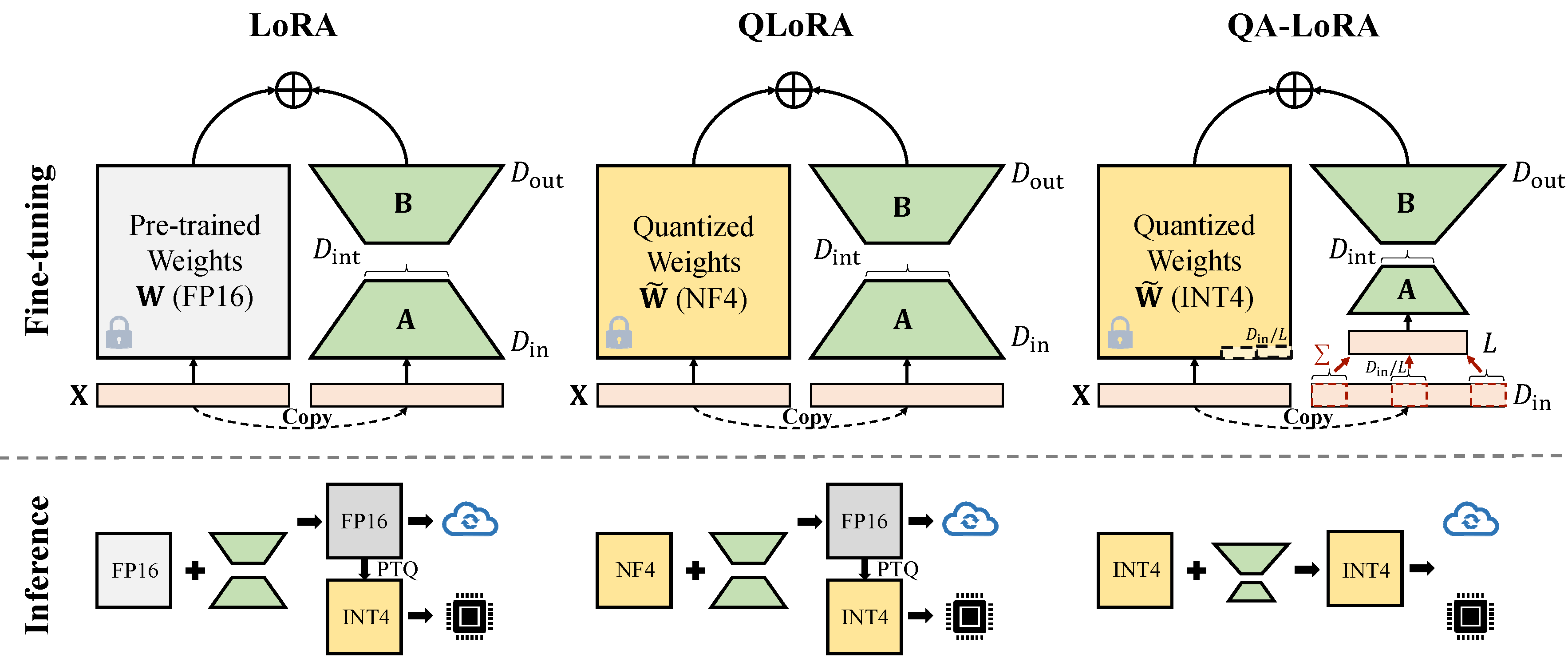
Qa-Lora легко реализуется с помощью нескольких строк кода, и он оснащает оригинальную Lora двукратными способностями: (i) во время точной настройки веса LLM квантованы (например, Int4) для сокращения времени и использования памяти; (ii) После тонкой настройки LLM и вспомогательные веса естественным образом интегрированы в квантовую модель без потери точности.
Исправьте конфликт с новейшей версией Auto-GPTQ.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * Измените peft_utils.py в своем собственном пути Auto-GPTQ (Python Path/auto_gptq/utils/peft_utils.py) с новым. Для пользователей gptqlora вам нужно только изменить файл peft_utils.py .
Мы используем GPTQ для квантования. BITS = 4, GROUP-SIFE = 32, ACT-ORDER = FALSE Если вы измените размер группы, вам необходимо соответственно изменить GROUP_SIZE в peft_utils.py и merge.py .
python qalora.py --model_path < path >Структура файла модели контрольной точки заключается в следующем:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
Обратите внимание, что наши обученные модули LORA могут быть идеально объединены в квантованную модель. Мы предлагаем простой объединенный сценарий в этом репо.
Существует два вида реализации сокращения размера (x от d_in до d_in // l). Оба являются математическими эквивалентами.
Принять операцию Avgpooling. Но веса адаптеров будут разделены на D_IN // L во время Merge (см. merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]Используйте операцию суммы. Адаптеры не нужно разделять во время слияния)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]Некоторая реализация GPTQ, такая как GPTQ-FOR-LLAMA, дополнительно сжимает нули в Qzeros. Вы должны сначала расшифровать Qzeros и восстановить формат FP16 нули.
Наш код основан на Qlora, Gptqlora, Auto-GPTQ


