qa lora
1.0.0
O QA-Lora foi aceito pelo ICLR 2024!
Este repositório fornece a implementação oficial de Pytorch de QA-Lora: adaptação de baixo rank de QA-Lora: consciência de quantização de grandes modelos de linguagem.
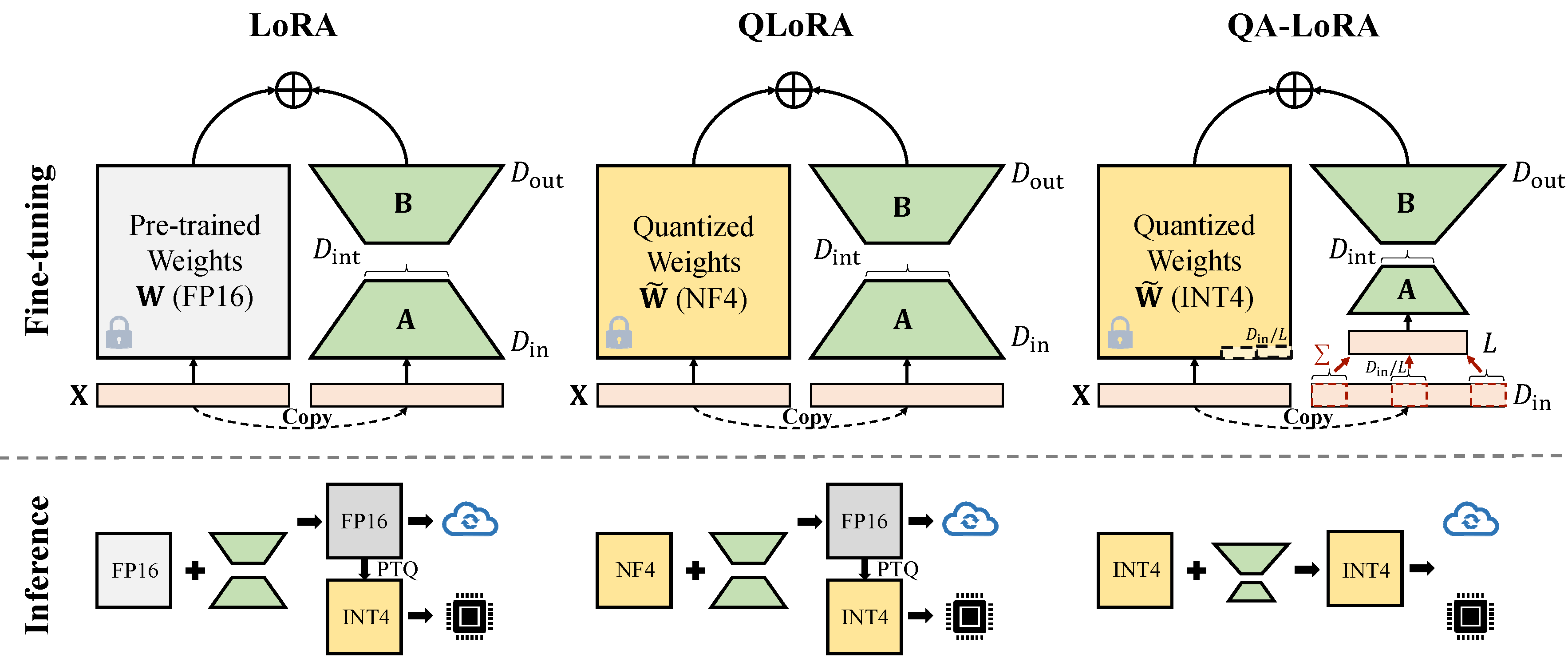
O QA-LORA é facilmente implementado com algumas linhas de código e equipa o LORA original com habilidades duplas: (i) durante o ajuste fino, os pesos do LLM são quantizados (por exemplo, em Int4) para reduzir o tempo e o uso da memória; (ii) Após o ajuste fino, o LLM e os pesos auxiliares são naturalmente integrados a um modelo quantizado sem perda de precisão.
Corrija o conflito com a mais recente versão do Auto-GPTQ.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * Altere o peft_utils.py em seu próprio caminho automático (Python Path/Auto_GPTQ/utils/peft_utils.py) com o novo. Para os usuários do GPTQLORA, você só precisa alterar o arquivo peft_utils.py .
Usamos GPTQ para quantização. bits = 4, tamanho do grupo = 32, ação de ação = false Se você alterar o tamanho do grupo, precisará alterar o grupo_size em peft_utils.py e merge.py de acordo.
python qalora.py --model_path < path >A estrutura do arquivo do ponto de verificação do modelo é a seguinte:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
Observe que nossos módulos LORA treinados podem ser perfeitamente mesclados no modelo quantizado. Oferecemos um script simples e mesclado neste repositório.
Existem dois tipos de implementações da redução da dimensão (x de d_in para d_in // l). Ambos são equivalentes matemáticos.
Adote operação de avgpooling. Mas os pesos dos adaptadores serão divididos por d_in // L durante a mesclagem (consulte merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]Utilize operação da soma. Os adaptadores não precisam ser divididos durante a mesclagem)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]Alguma implementação do GPTQ, como o GPTQ-For-llama, comprime ainda mais os Zeros em Qzeros. Você precisa decodificar o QZEROS primeiro e restaurar o formato FP16 Zeros.
Nosso código é baseado em Qlora, Gptqlora, Auto-GPTQ


