qa lora
1.0.0
QA-Lora a été acceptée par ICLR 2024!
Ce référentiel fournit la mise en œuvre officielle Pytorch de QA-Lora: adaptation à faible rang consciente de la quantification des modèles de grands langues.
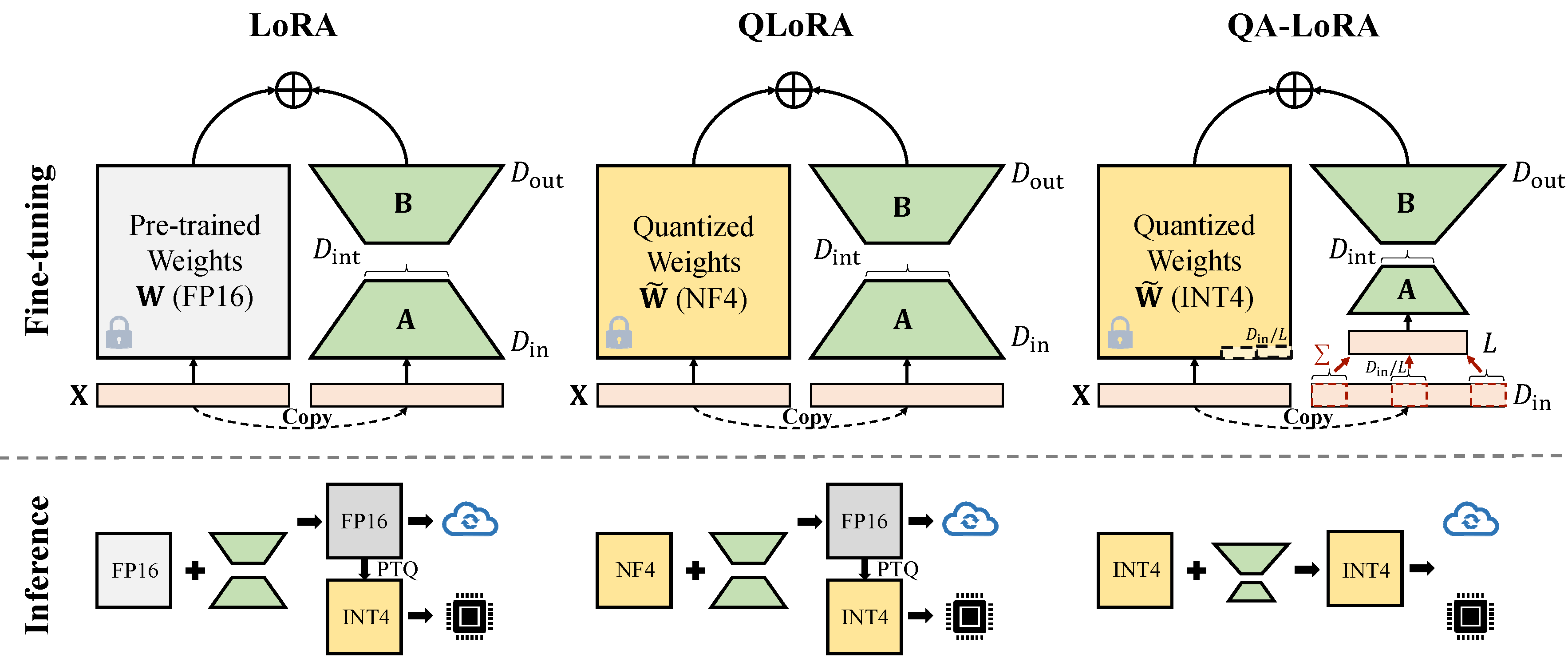
QA-Lora est facilement implémentée avec quelques lignes de code, et il équipe la LORA d'origine de deux capacités: (i) pendant le réglage fin, les poids du LLM sont quantifiés (par exemple, dans INT4) pour réduire le temps et l'utilisation de la mémoire; (ii) Après un réglage fin, les poids LLM et auxiliaires sont naturellement intégrés dans un modèle quantifié sans perte de précision.
Corrigez le conflit avec la dernière version Auto-GPTQ.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * Changez le peft_utils.py dans votre propre chemin Auto-GPTQ (Python Path / Auto_GPTQ / UTILS / PEFT_UTILS.py) avec le nouveau. Pour les utilisateurs de GPTQLORA, il vous suffit de modifier le fichier peft_utils.py .
Nous utilisons GPTQ pour la quantification. bits = 4, groupe-size = 32, Act-Order = false Si vous modifiez la taille de groupe, vous devez modifier le groupe_size dans peft_utils.py et merge.py en conséquence.
python qalora.py --model_path < path >La structure du fichier du point de contrôle du modèle est la suivante:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
Notez que nos modules LORA formés peuvent être parfaitement fusionnés dans le modèle quantifié. Nous offrons un simple script fusionné dans ce dépôt.
Il existe deux types d'implémentations de la réduction de la dimension (x de d_in à d_in // l). Les deux sont l'équivalent mathématique.
Adopter l'opération AVGPooling. Mais les poids des adaptateurs seront divisés par d_in // l pendant la fusion (reportez-vous à merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]Utiliser l'opération de somme. Les adaptateurs n'ont pas besoin d'être divisés pendant la fusion)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]Certaines implémentations GPTQ telles que GPTQ-for-Llama compressent en outre les zéros en qzeros. Vous devez d'abord décoder les Qzeros et restaurer les zéros du format FP16.
Notre code est basé sur Qlora, Gptqlora, Auto-GPTQ


