qa lora
1.0.0
Qa-Lora ได้รับการยอมรับจาก ICLR 2024!
ที่เก็บนี้ให้การใช้งาน Pytorch อย่างเป็นทางการของ QA-LORA: การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่ที่รับรู้เชิงปริมาณ
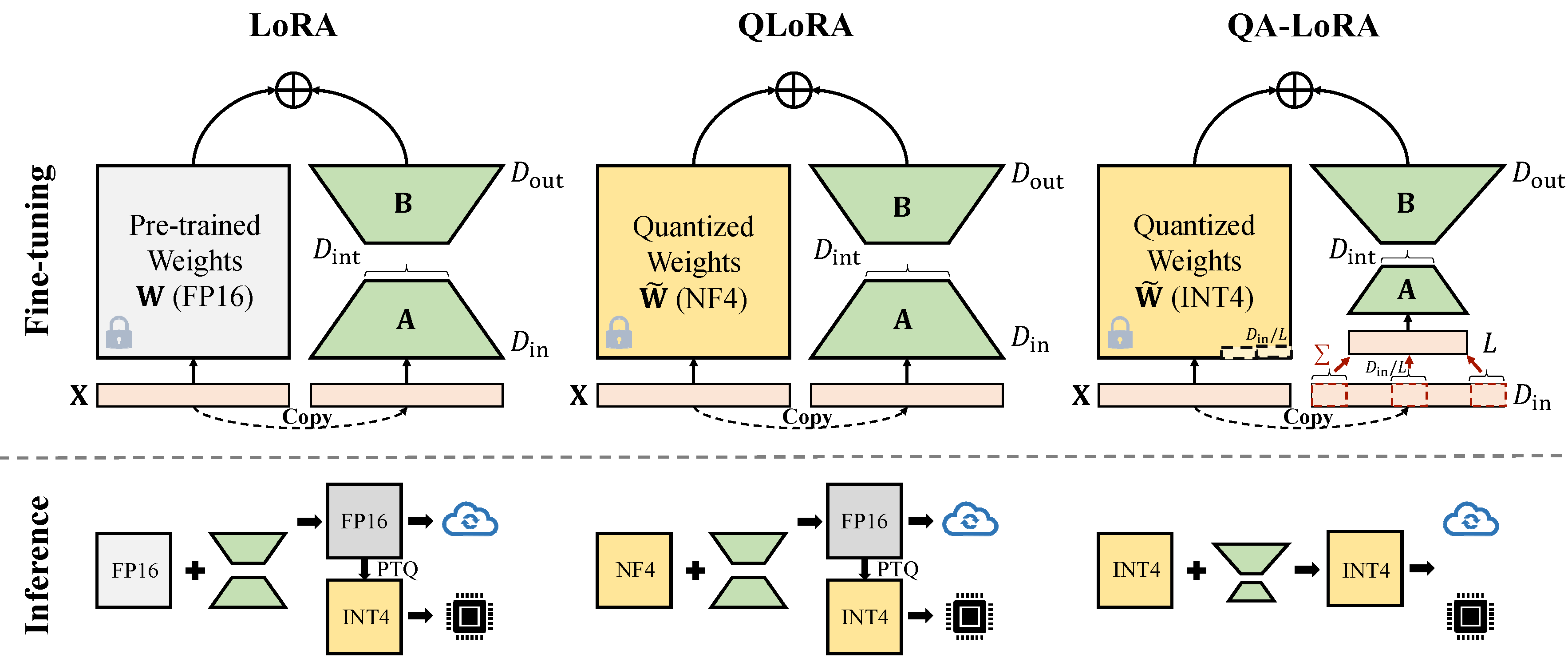
Qa-Lora สามารถใช้งานได้อย่างง่ายดายด้วยรหัสสองสามบรรทัดและมันจะช่วยให้ LORA ดั้งเดิมมีความสามารถสองเท่า: (i) ในระหว่างการปรับจูนน้ำหนักของ LLM จะถูกวัดปริมาณ (เช่น int4) เพื่อลดเวลาและการใช้หน่วยความจำ; (ii) หลังจากการปรับแต่งอย่างละเอียด LLM และน้ำหนักเสริมจะถูกรวมเข้ากับแบบจำลองเชิงปริมาณโดยไม่สูญเสียความแม่นยำ
แก้ไขความขัดแย้งด้วยรุ่น Auto-GPTQ ใหม่ล่าสุด
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * เปลี่ยน peft_utils.py ในเส้นทาง Auto-GPTQ ของคุณเอง (Python Path/Auto_GPTQ/UTILS/PEFT_UTILS.PY) กับเส้นทางใหม่ สำหรับผู้ใช้ GPTQlora คุณจะต้องเปลี่ยนไฟล์ peft_utils.py เท่านั้น
เราใช้ GPTQ สำหรับการหาปริมาณ bits = 4, กลุ่มขนาด = 32, act-order = false ถ้าคุณเปลี่ยนขนาดกลุ่มคุณต้องเปลี่ยน group_size ใน peft_utils.py และ merge.py ตามนั้น
python qalora.py --model_path < path >โครงสร้างไฟล์ของจุดตรวจสอบโมเดลมีดังนี้:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
โปรดทราบว่าโมดูล Lora ที่ผ่านการฝึกอบรมของเราสามารถรวมเข้ากับโมเดลเชิงปริมาณได้อย่างสมบูรณ์แบบ เรานำเสนอสคริปต์ที่ผสานง่าย ๆ ใน repo นี้
มีการใช้งานสองประเภทของการลดขนาด (x จาก d_in เป็น d_in // l) ทั้งสองมีคณิตศาสตร์เทียบเท่า
นำการดำเนินการ avgpooling แต่น้ำหนักของอะแดปเตอร์จะถูกหารด้วย d_in // l ระหว่างการผสาน (อ้างอิงถึง merge.py )
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]ใช้ประโยชน์จากการดำเนินการรวม อะแดปเตอร์ไม่จำเป็นต้องแบ่งระหว่างการผสาน)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]การใช้งาน GPTQ บางอย่างเช่น GPTQ-for-llama จะบีบอัดศูนย์เป็น qzeros คุณต้องถอดรหัส Qzeros ก่อนและกู้คืนศูนย์รูปแบบ FP16
รหัสของเราขึ้นอยู่กับ Qlora, GptQlora, Auto-GPTQ


