qa lora
1.0.0
تم قبول QA-Lora بواسطة ICLR 2024!
يوفر هذا المستودع تنفيذ Pytorch الرسمي لـ QA-Lora: التكيف المنخفض للتكيف المنخفض للصفاء لنماذج اللغة الكبيرة.
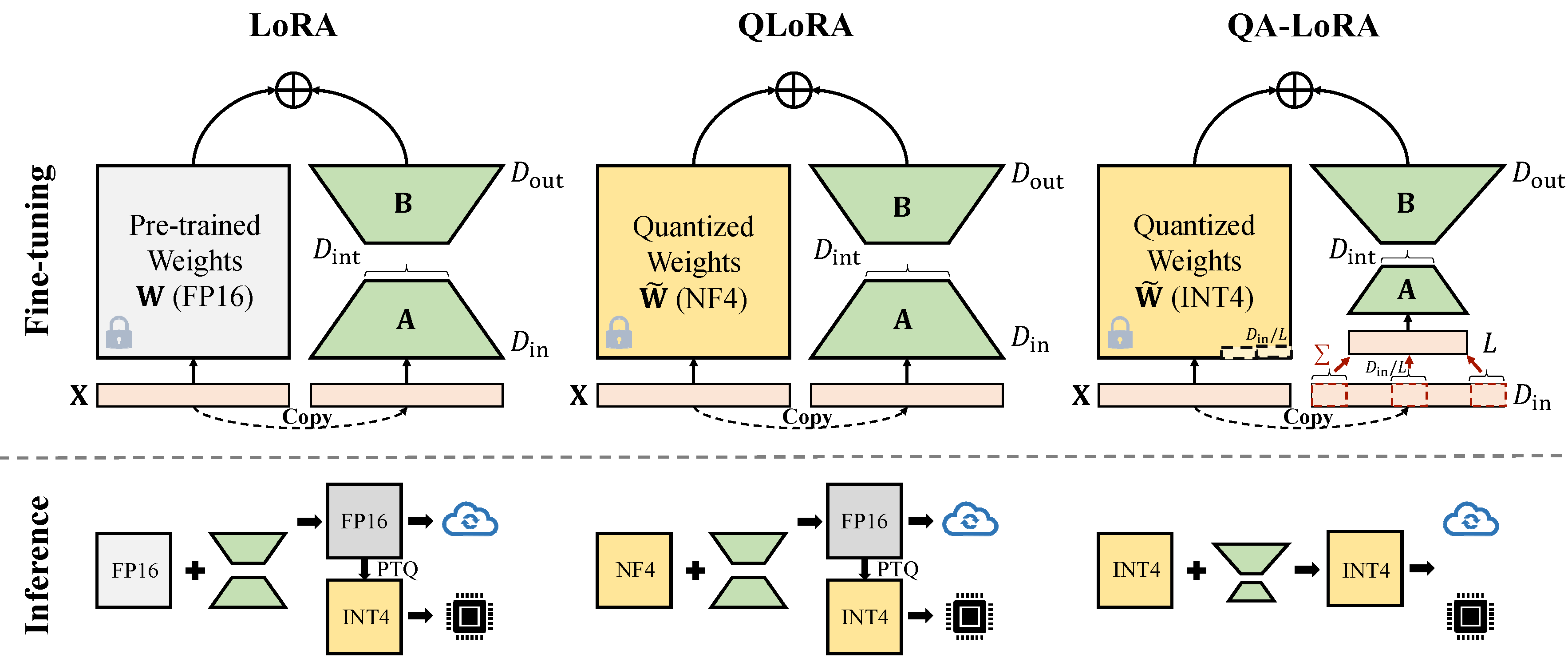
يتم تنفيذ QA-Lora بسهولة مع بضعة أسطر من التعليمات البرمجية ، وهي تزيد من Lora الأصلي بقدرات ذات شقين: (1) أثناء ضبطها ، يتم كمية أوزان LLM (على سبيل المثال ، إلى INT4) لتقليل الوقت والذاكرة ؛ (2) بعد الضبط الدقيق ، يتم دمج LLM والأوزان المساعدة بشكل طبيعي في نموذج كمي دون فقدان الدقة.
إصلاح الصراع مع أحدث إصدار من GPTQ.
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. * قم بتغيير peft_utils.py في مسار GPTQ الخاص بك (مسار Python/Auto_gptq/utils/peft_utils.py) مع المسار الجديد. بالنسبة لمستخدمي GPTQLORA ، تحتاج فقط إلى تغيير ملف peft_utils.py .
نحن نستخدم GPTQ لتحديد الكمي. Bits = 4 ، حجم المجموعة = 32 ، Act-order = false إذا قمت بتغيير حجم المجموعة ، فأنت بحاجة إلى تغيير Group_size في peft_utils.py و merge.py وفقًا لذلك.
python qalora.py --model_path < path >هيكل ملف نقطة تفتيش النموذج كما يلي:
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
لاحظ أنه يمكن دمج وحدات Lora المدربة لدينا بشكل مثالي في النموذج الكمي. نحن نقدم البرنامج النصي المدمج البسيط في هذا الريبو.
هناك نوعان من تطبيقات تخفيض الخافت (x من d_in إلى d_in // l). كلاهما مكافئ رياضي.
تبني عملية Avgpooling. ولكن سيتم تقسيم أوزان المحولات على D_IN // L أثناء الدمج (راجع merge.py ).
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]الاستفادة من عملية المبلغ. لا تحتاج المحولات إلى تقسيمها أثناء الدمج)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]بعض تنفيذ GPTQ مثل GPTQ-For-Llama يزيد من ضغط الأصفار إلى Qzeros. تحتاج إلى فك تشفير Qzeros أولاً واستعادة أصفار تنسيق FP16.
يعتمد كودنا على Qlora و GPTQlora و Auto-GPTQ


