qa lora
1.0.0
QA-LORAはICLR 2024に受け入れられています!
このリポジトリは、大規模な言語モデルのQA-LORA:量子化に対応する低ランク適応の公式Pytorch実装を提供します。
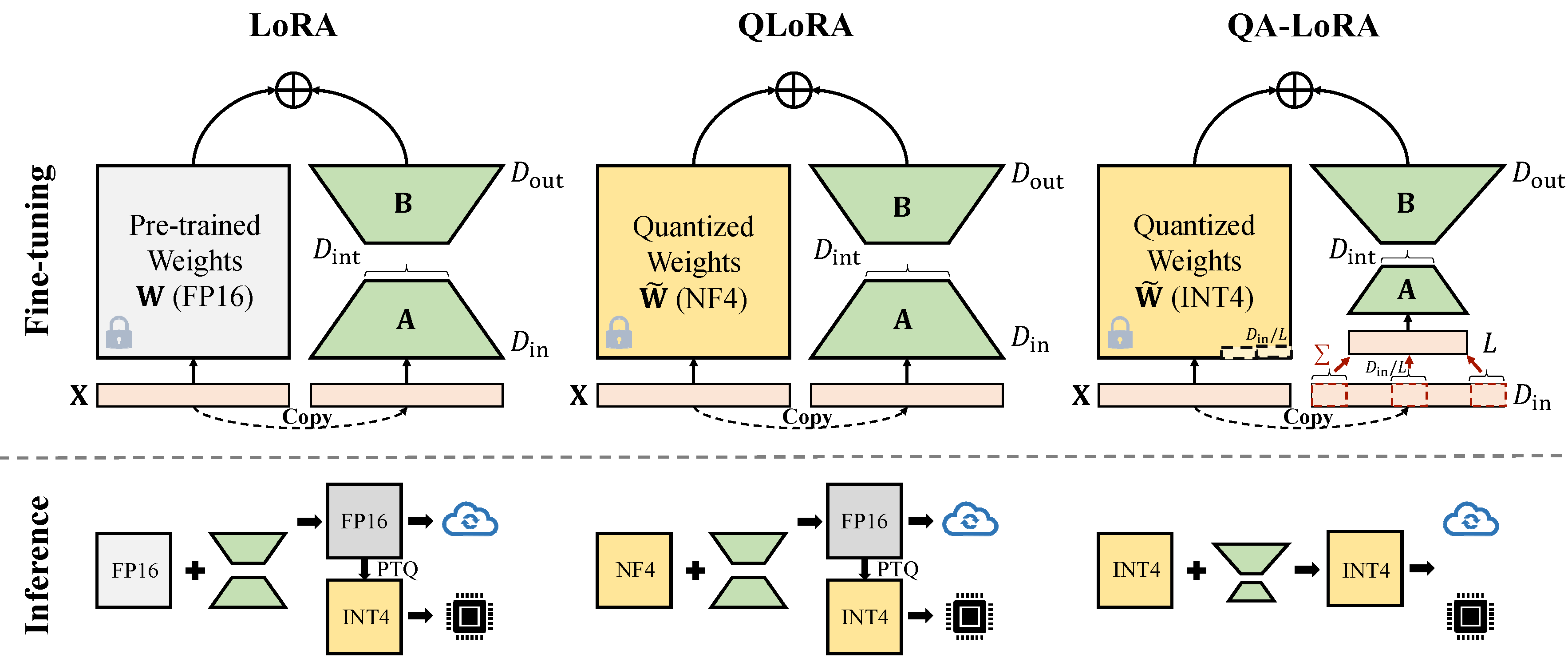
QA-LORAは数行のコードで簡単に実装され、元のLORAに2つの倍の能力を装備します。(i)微調整中に、LLMの重みが量子化され(例:INT4)、時間と記憶の使用量を削減します。 (ii)微調整後、LLMと補助の重みは、精度を失うことなく量子化されたモデルに自然に統合されます。
最新のAuto-GPTQバージョンとの競合を修正します。
conda create -n qalora python=3.8
conda activate qalora
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
git clone -b v0.3.0 https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
pip install .
cd ..
pip install bitsandbytes
pip install -r requirements.txt
pip install protobuf==3.20. *新しいものを使用して、自分のauto-gptqパス(python path/auto_gptq/utils/peft_utils.py)でpeft_utils.py変更します。 GPTQLORAのユーザーの場合、 peft_utils.pyファイルを変更するだけです。
量子化にはGPTQを使用します。 bits = 4、group-size = 32、act-order = falseグループサイズを変更する場合、group_sizeをpeft_utils.pyおよびmerge.pyで変更する必要があります。
python qalora.py --model_path < path >モデルチェックポイントのファイル構造は次のとおりです。
config.json llama7b-4bit-32g.bin special_tokens_map.json tokenizer_config.json
generation_config.json quantize_config.json tokenizer.model
訓練されたLORAモジュールは、量子化されたモデルに完全にマージできることに注意してください。このリポジトリで簡単なマージされたスクリプトを提供しています。
二量体の減少には2種類の実装があります(xからD_INからD_IN // Lへのx)。どちらも数学的な同等です。
Avgpooling Operationを採用します。ただし、アダプターの重みは、マージ中にD_IN // Lで分割されます( merge.pyを参照)。
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x)))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / group_size / model[tmp_key+ ' .scales ' ]合計操作を利用します。マージ中にアダプターを分割する必要はありません)
adapter_result = (lora_B(lora_A(lora_dropout(self.qa_pool(x) * group_size))) * scale).type_as(result)
model[tmp_key+ ' .qzeros ' ] -= (lora[ ' base_model.model. ' +tmp_key+ ' .lora_B.weight ' ] @ lora['base_model.model.'+tmp_key+'.lora_A.weight']).t () * scale / model[tmp_key+ ' .scales ' ]GPTQ-For-lamaなどのGPTQ実装の一部は、ゼロをQzerosにさらに圧縮します。最初にQzerosをデコードし、FP16形式のゼロを復元する必要があります。
私たちのコードは、qlora、gptqlora、auto-gptqに基づいています


