PETL_AST
1.0.0
該存儲庫包含論文的官方代碼:音頻譜圖變壓器的參數效率轉移學習[1] (接受2024 IEEE MLSP研討會上的出版物)以及通過適配器的軟混合物對音頻譜圖變壓器進行有效的微調[2] (接受Interspeech 2024 )。
兩篇論文都研究如何將參數效率轉移學習( PETL )方法應用於各種音頻/語音下游任務的音頻譜圖變壓器(AST)模型。儘管[1]在不同的情況和約束下提供了PETL方法(及時調整,Lora,適配器)的全面概述,但[2]探討瞭如何有效利用PETL的專家體系結構的混合物。
下面我們包括所有詳細信息,以復制我們的結果。重要的是:確保設置與我們用於實驗的環境,因此請使用requients.txt文件安裝相同的軟件包版本。
Umberto Cappellazzo,Daniele Falavigna,Alessio Brutti,Mirco Ravanelli
該論文已在2024年IEEE MLSP研討會上接受。本文探討了用於用於各種音頻和語音處理任務的音頻頻譜變壓器模型的不同PETL方法的使用。此外,我們提出了一種新的適配器設計,該設計利用了構象異構體模型的捲積模塊,從而超過了標準的PETL方法,並通過僅更新0.29%的參數來超越或實現完整的微調。
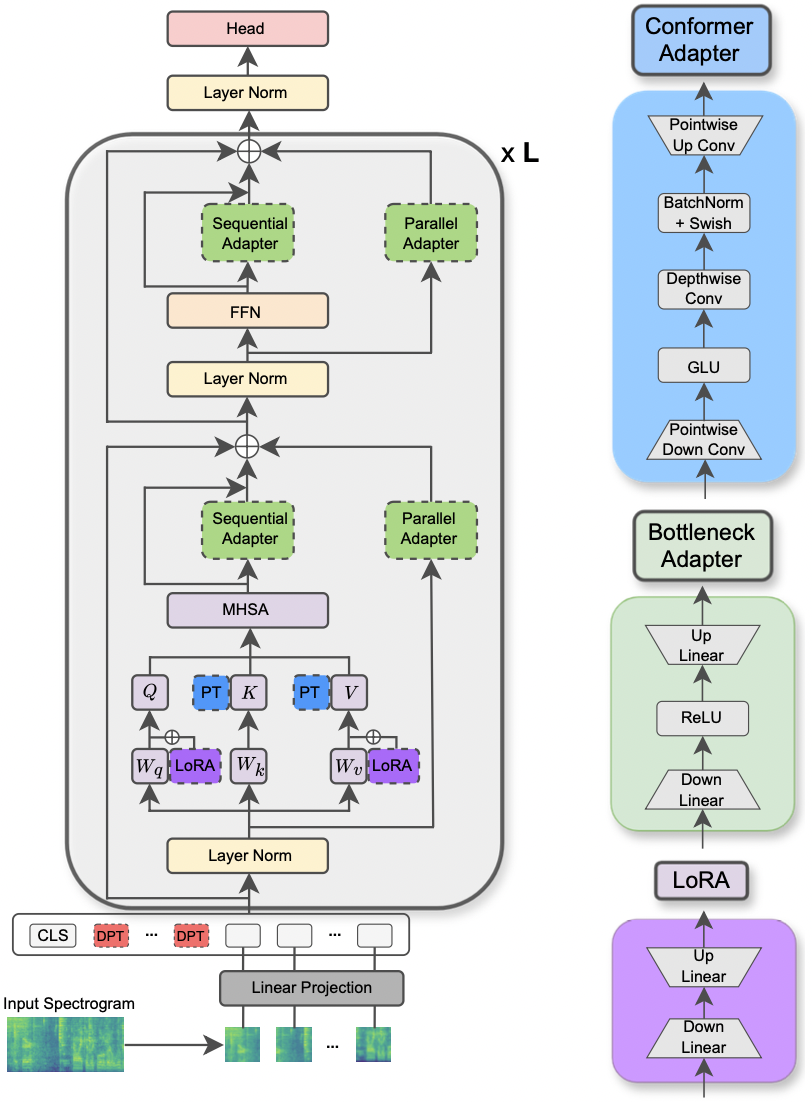 |
|---|
| AST模型和PETL方法的例證。 |
要求用於運行實驗的請求的庫中列出了unignts.txt文件。運行下面的命令以安裝它們。
pip install -r requirements.txt
我使用重量和偏見(https://wandb.ai/site)來跟踪我的實驗(我熱情地推薦它)。但是,您可以通過設置--use_wandb = False在命令行中停用它。
我希望用戶已經下載了他/她自己的數據集。
要運行一個實驗,您需要的所有內容都是使用命令python3 main.py然後使用一些參數傳遞到命令行以指定設置。強制性參數是:
--data_path :通往包含數據集的文件夾的路徑。--dataset_name :選定的數據集。截至目前,有5個數據集可用: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] 。--method :選定的PETL方法。支持的PETL方法列表如下: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] 。請查看其他紙,以進行密集/軟摩爾的實驗。--is_AST :如果設置為true,則使用AST預訓練模型。如果設置為false,則採用WAV2VEC 2.0預訓練模型。main.py腳本以獲取詳細說明。hparams/train.yaml上檢查和修改與優化過程和數據集有關的超參數。當前值對應於我們用於實驗的值,這導致了最佳結果。每種PETL方法都帶有一些特定的參數。我們在下面提供了一個簡短的描述。請注意,在這裡,我們避免使用簡短的參考文獻,請參閱論文。
reduction_rate_adapter >它規則規定了適配器模塊的瓶頸(例如,如果D是隱藏的尺寸,並且RR是降低速率,則適配器的DIM為D /RR); seq_or_par >是平行或順序插入適配器; adapter_type > pfeiffer或houlsby配置; adapter_block >瓶頸或構象異構體(我們提出的適配器設計); apply_residual >是否應用剩餘連接。如本文所述,平行適配器應分配為殘差,而順序適配器則從殘差中受益。prompt_len_prompt >使用多少提示; is_deep_prompt >如果要啟用深度提示(DPT),則設置為True ,否則請提示(SPT); drop_prompt >提示的輟學率。在我們的實驗中,我們將其設置為0. 。reduction_rate_lora >請參閱reduction_rate_adapter ; alpha_lora >原始論文中定義的lora_alpha。這用於縮放(例如,s = alpha_lora/rr)。例如,假設我們想使用配置構象異構體,並行,pfeiffer,rr = 64測試適配器,並在FSC數據集上對AST模型進行測試。然後,運行的命令是:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer '如果要運行幾次學習實驗,則只需要將標誌設置為True --is_few_shot_exp並指定每個類別的樣本# --few_shot_samples 。
請在任何問題上與我聯繫:umbertocappellazzo [at] gmail [dot] com。
我們感謝加拿大數字研究聯盟(Alliancecan.ca)的支持。
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo,Daniele Falavigna,Alessio Brutti
該論文已在Interspeech 2024接受。它研究了專家(MOE)的混合物來有效地進行AST進行微調。具體而言,我們將最近的軟MOE方法調整為參數效率設置,在該設置中,每個專家都由適配器模塊表示。我們稱其為軟莫阿(適配器的軟混合物)。 Soft-MOA在降低計算成本的同時,與密集的對應物(密集-MOA)達到了性能均衡。此外,它表現出比傳統單個適配器的優越性能。
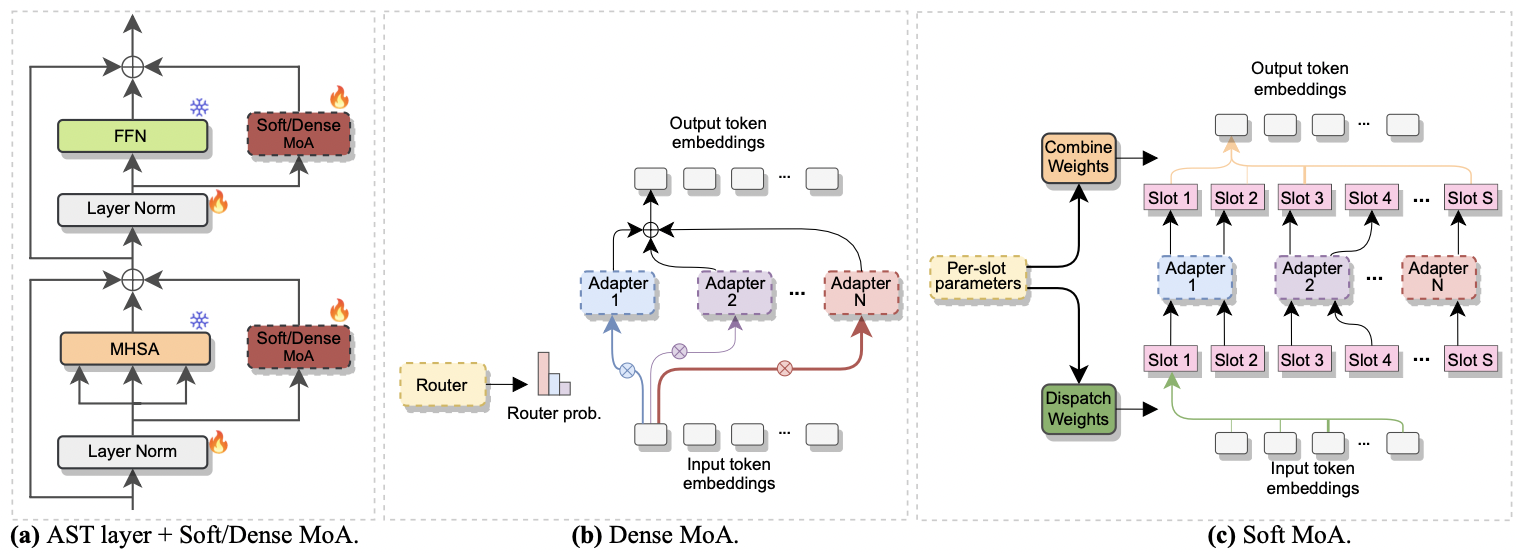 |
|---|
| a)適配器插入每個AST層。 b)密集的moa。 c)軟莫阿。 |
用密集和柔軟的MOA進行實驗很輕鬆。我們遵循用於紙張[1]的相同過程。我們只需要將--method參數設置為Dense-MoA或Soft-MoA ,並指定一些臨時參數:
--reduction_rate_moa :與其他PETL方法完全一樣,我們需要為每個適配器專家指定降低率。降低速率越高,瓶頸尺寸越小。--adapter_type_moa : pfeiffer或houlsby配置。--location_moa :是否應用於平行於MHSA或FFN塊的軟/密集MOA層。如果可以選擇-adapter_type_moa == houlsa,mhsa和ffn被選擇。--adapter_module_moa :適配器的類型。到目前為止,我們支持瓶頸和交流。--num_adapters :每個軟/緻密MOA層都使用了多少個適配器。在我們的實驗中,該值介於2到15之間。--num_slots :軟MOA中使用的插槽數。通常將其設置為1或2。 [ NB :僅用於軟MOA]--normalize :是否按照原始軟MOE紙中提出的L2標準化輸入矢量和PHI矩陣(請參閱第2.3節,“歸一化”)。如本文中所述,如果模型的隱藏大小像我們的情況一樣小(例如,768),則標準化操作幾乎沒有影響,因此我們沒有使用歸一化。 [ NB :僅用於軟莫阿]例如,假設我們要在FSC數據集上測試Soft-MOA。另外,我們選擇僅在MHSA層中包含軟MOA層,並使用7個BOTSENECK適配器。然後,運行的命令是:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

