PETL_AST
1.0.0
该存储库包含论文的官方代码:音频谱图变压器的参数效率转移学习[1] (接受2024 IEEE MLSP研讨会上的出版物)以及通过适配器的软混合物对音频谱图变压器进行有效的微调[2] (接受Interspeech 2024 )。
两篇论文都研究如何将参数效率转移学习( PETL )方法应用于各种音频/语音下游任务的音频谱图变压器(AST)模型。尽管[1]在不同的情况和约束下提供了PETL方法(及时调整,Lora,适配器)的全面概述,但[2]探讨了如何有效利用PETL的专家体系结构的混合物。
下面我们包括所有详细信息,以复制我们的结果。重要的是:确保设置与我们用于实验的环境,因此请使用requients.txt文件安装相同的软件包版本。
Umberto Cappellazzo,Daniele Falavigna,Alessio Brutti,Mirco Ravanelli
该论文已在2024年IEEE MLSP研讨会上接受。本文探讨了用于用于各种音频和语音处理任务的音频频谱变压器模型的不同PETL方法的使用。此外,我们提出了一种新的适配器设计,该设计利用了构象异构体模型的卷积模块,从而超过了标准的PETL方法,并通过仅更新0.29%的参数来超越或实现完整的微调。
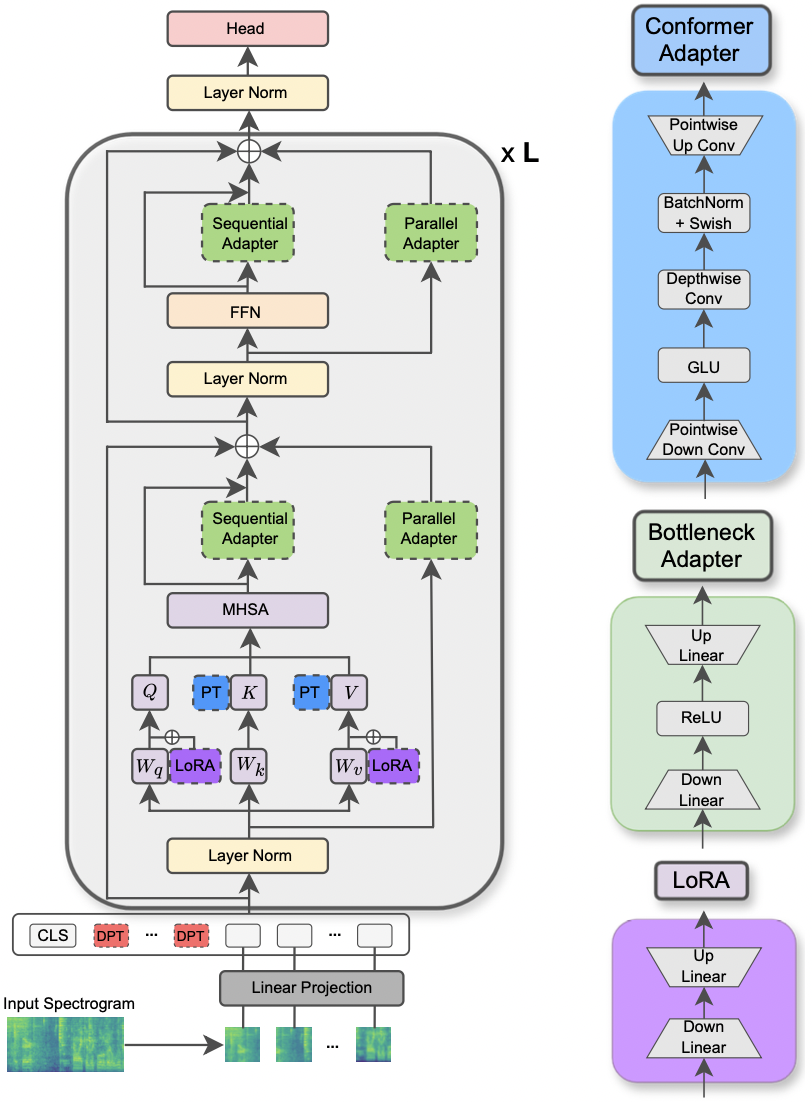 |
|---|
| AST模型和PETL方法的例证。 |
要求用于运行实验的请求的库中列出了unignts.txt文件。运行下面的命令以安装它们。
pip install -r requirements.txt
我使用重量和偏见(https://wandb.ai/site)来跟踪我的实验(我热情地推荐它)。但是,您可以通过设置--use_wandb = False在命令行中停用它。
我希望用户已经下载了他/她自己的数据集。
要运行一个实验,您需要的所有内容都是使用命令python3 main.py然后使用一些参数传递到命令行以指定设置。强制性参数是:
--data_path :通往包含数据集的文件夹的路径。--dataset_name :选定的数据集。截至目前,有5个数据集可用: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] 。--method :选定的PETL方法。支持的PETL方法列表如下: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] 。请查看其他纸,以进行密集/软摩尔的实验。--is_AST :如果设置为true,则使用AST预训练模型。如果设置为false,则采用WAV2VEC 2.0预训练模型。main.py脚本以获取详细说明。hparams/train.yaml上检查和修改与优化过程和数据集有关的超参数。当前值对应于我们用于实验的值,这导致了最佳结果。每种PETL方法都带有一些特定的参数。我们在下面提供了一个简短的描述。请注意,在这里,我们避免使用简短的参考文献,请参阅论文。
reduction_rate_adapter >它规则规定了适配器模块的瓶颈(例如,如果D是隐藏的尺寸,并且RR是降低速率,则适配器的DIM为D /RR); seq_or_par >是平行或顺序插入适配器; adapter_type > pfeiffer或houlsby配置; adapter_block >瓶颈或构象异构体(我们提出的适配器设计); apply_residual >是否应用剩余连接。如本文所述,平行适配器应分配为残差,而顺序适配器则从残差中受益。prompt_len_prompt >使用多少提示; is_deep_prompt >如果要启用深度提示(DPT),则设置为True ,否则请提示(SPT); drop_prompt >提示的辍学率。在我们的实验中,我们将其设置为0. 。reduction_rate_lora >请参阅reduction_rate_adapter ; alpha_lora >原始论文中定义的lora_alpha。这用于缩放(例如,s = alpha_lora/rr)。例如,假设我们想使用配置构象异构体,并行,pfeiffer,rr = 64测试适配器,并在FSC数据集上对AST模型进行测试。然后,运行的命令是:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer '如果要运行几次学习实验,则只需要将标志设置为True --is_few_shot_exp并指定每个类别的样本# --few_shot_samples 。
请在任何问题上与我联系:umbertocappellazzo [at] gmail [dot] com。
我们感谢加拿大数字研究联盟(Alliancecan.ca)的支持。
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo,Daniele Falavigna,Alessio Brutti
该论文已在Interspeech 2024接受。它研究了专家(MOE)的混合物来有效地进行AST进行微调。具体而言,我们将最近的软MOE方法调整为参数效率设置,在该设置中,每个专家都由适配器模块表示。我们称其为软莫阿(适配器的软混合物)。 Soft-MOA在降低计算成本的同时,与密集的对应物(密集-MOA)达到了性能均衡。此外,它表现出比传统单个适配器的优越性能。
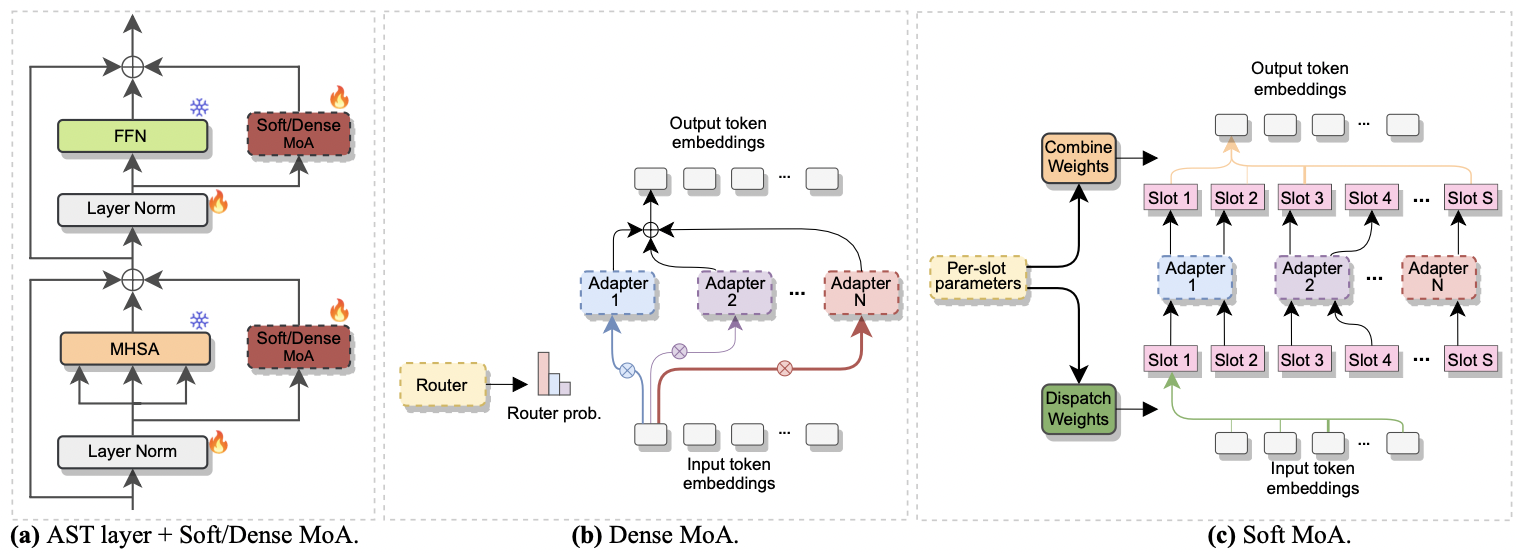 |
|---|
| a)适配器插入每个AST层。 b)密集的moa。 c)软莫阿。 |
用密集和柔软的MOA进行实验很轻松。我们遵循用于纸张[1]的相同过程。我们只需要将--method参数设置为Dense-MoA或Soft-MoA ,并指定一些临时参数:
--reduction_rate_moa :与其他PETL方法完全一样,我们需要为每个适配器专家指定降低率。降低速率越高,瓶颈尺寸越小。--adapter_type_moa : pfeiffer或houlsby配置。--location_moa :是否应用于平行于MHSA或FFN块的软/密集MOA层。如果可以选择-adapter_type_moa == houlsa,mhsa和ffn被选择。--adapter_module_moa :适配器的类型。到目前为止,我们支持瓶颈和交流。--num_adapters :每个软/致密MOA层都使用了多少个适配器。在我们的实验中,该值介于2到15之间。--num_slots :软MOA中使用的插槽数。通常将其设置为1或2。[ NB :仅用于软MOA]--normalize :是否按照原始软MOE纸中提出的L2标准化输入矢量和PHI矩阵(请参阅第2.3节,“归一化”)。如本文中所述,如果模型的隐藏大小像我们的情况一样小(例如,768),则标准化操作几乎没有影响,因此我们没有使用归一化。 [ NB :仅用于软莫阿]例如,假设我们要在FSC数据集上测试Soft-MOA。另外,我们选择仅在MHSA层中包含软MOA层,并使用7个BOTSENECK适配器。然后,运行的命令是:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

