PETL_AST
1.0.0
Este repositorio contiene el código oficial de los documentos: Aprendizaje de transferencia de parámetros-eficiente de transformadores de espectrograma de audio [1] ( aceptado para su publicación en el taller IEEE MLSP 2024 ) y el ajuste eficiente de los transformadores de espectrograma de audio a través de la mezcla suave de adaptadores [2] ( aceptado para publicar en el interponimiento 2024 ).
Ambos documentos estudian cómo aplicar los métodos de aprendizaje de transferencia de parámetros-eficiente ( PETL ) al modelo de transformador de espectrograma de audio (AST) para varias tareas de audio/discurso aguas abajo. Mientras que [1] proporciona una visión general integral de los métodos PETL (ajuste rápido, lora, adaptadores) en diferentes escenarios y limitaciones, [2] explora cómo aprovechar de manera eficiente la mezcla de la arquitectura de expertos para PETL.
A continuación incluimos todos los detalles para replicar nuestros resultados. IMPORTANTE : Asegúrese de configurar un entorno que sea compatible con el que utilizamos para nuestros experimentos, por lo que instale las mismas versiones de paquetes utilizando el archivo requisitos.txt .
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
El documento ha sido aceptado en el taller MLSP IEEE 2024 . Este documento explora el uso de diferentes métodos PETL aplicados al modelo de transformador de espectrograma de audio para varias tareas de procesamiento de audio y voz. Además, proponemos un nuevo diseño de adaptador que explota el módulo de convolución del modelo conformador, lo que lleva a un rendimiento superior sobre los enfoques de PETL estándar y superando o logrando la paridad de rendimiento con ajuste completo al actualizar solo el 0.29% de los parámetros.
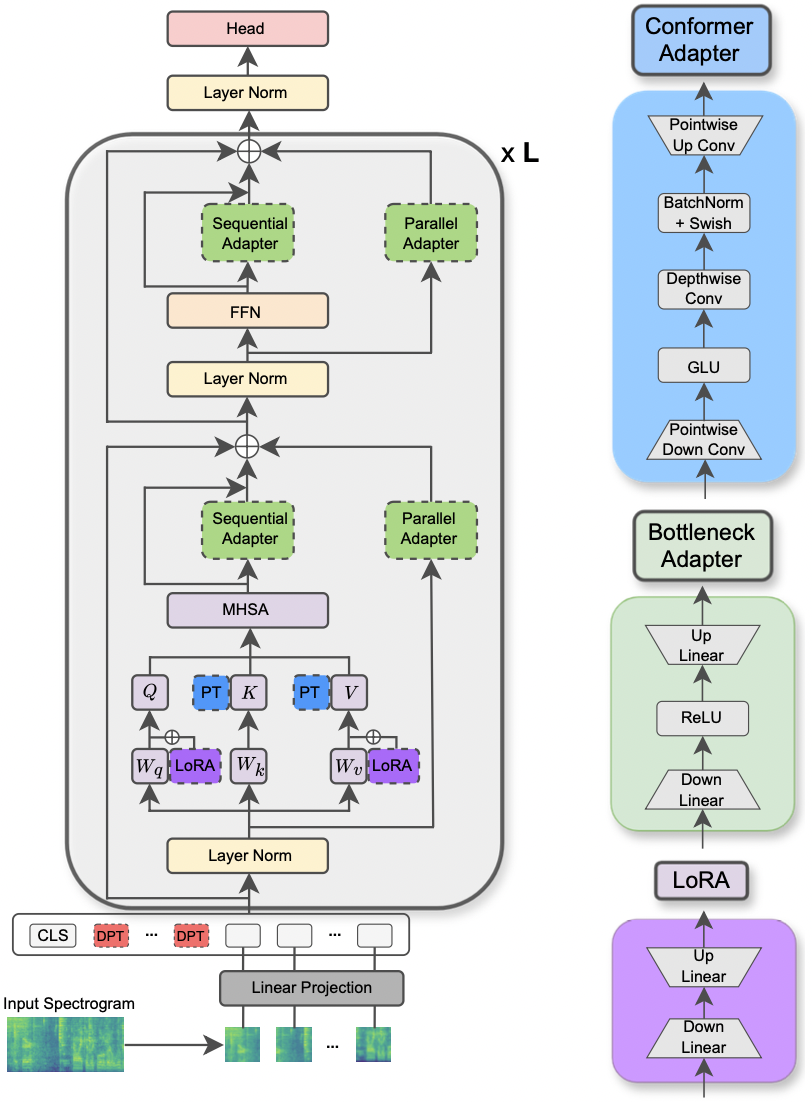 |
|---|
| Ilustración del modelo AST y los métodos PETL. |
Las bibliotecas solicitadas para ejecutar los experimentos se enumeran en el archivo requisitos.txt. Ejecute el comando a continuación para instalarlos.
pip install -r requirements.txt
Utilizo pesas y sesgos (https://wandb.ai/site) para rastrear mis experimentos (lo recomiendo calurosamente). No obstante, puede desactivarlo configurando --use_wandb = False en la línea de comando.
Espero que el usuario ya haya descargado los conjuntos de datos por sí mismo.
Para ejecutar un experimento, todo lo que necesita es usar el comando python3 main.py seguido de algunos argumentos pasados a la línea de comando para especificar la configuración. Los parámetros obligatorios son:
--data_path : la ruta a la carpeta que contiene el conjunto de datos.--dataset_name : el conjunto de datos seleccionado. A partir de ahora, se dispone de 5 conjuntos de datos: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : el método PETL seleccionado. Sigue una lista de métodos PETL compatibles: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . Echa un vistazo al otro papel para ejecutar un experimento con Dense/Soft-MOA.--is_AST : si se establece en True, usa el modelo AST priorizado. Si se establece en False, emplea el modelo previamente capacitado WAV2VEC 2.0.main.py para una descripción detallada.hparams/train.yaml . Los valores actuales corresponden a los que utilizamos para nuestros experimentos y eso condujo a los mejores resultados.Cada método PETL viene con algunos parámetros específicos. Proporcionamos una breve descripción a continuación. Tenga en cuenta que aquí evitamos incluir las referencias de brevedad, consulte el documento.
reduction_rate_adapter -> gobierna el celo de botella DIM del módulo adaptador (por ejemplo, si D es la dimensión oculta y RR es la velocidad de reducción, entonces el tenue del adaptador es D /RR); seq_or_par -> Si debe insertar el adaptador paralelo o secuencialmente; adapter_type -> Configuración de Pfeiffer o Houlsby; adapter_block -> Cuque de botella o conformador (nuestro diseño de adaptador propuesto); apply_residual -> si se debe aplicar conexiones residuales o no. Como se informó en el documento, el adaptador paralelo debe prescindir de los residuos, mientras que el adaptador secuencial se beneficia de los residuos.prompt_len_prompt > cuántas indicaciones para usar; is_deep_prompt > Establecer en True Si desea habilitar el ajuste de inmediato (DPT), de lo contrario, el ajuste de inmediato (SPT); drop_prompt -> La tasa de abandono de las indicaciones. En nuestros experimentos lo establecemos en 0. ..reduction_rate_lora -> Consulte reduction_rate_adapter ; alpha_lora -> el lora_alpha como se define en el documento original. Esto se usa para escalar (por ejemplo, s = alfa_lora/rr).Por ejemplo, supongamos que queremos probar el adaptador con conformador de configuración, paralelo, pfeiffer, rr = 64, y probarlo en el conjunto de datos FSC para el modelo AST. Entonces, el comando para ejecutar es:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' Si desea ejecutar experimentos de aprendizaje de pocos disparos, solo necesita configurar el indicador --is_few_shot_exp a True y especificar el # de muestras por clase --few_shot_samples .
Por favor, comuníquese conmigo en: Umbertocappelazzo [at] gmail [dot] com para cualquier pregunta.
Reconocemos el apoyo de la Alianza de Investigación Digital de Canadá (Alliancecan.ca).
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti
El documento ha sido aceptado en Interspeech 2024 . Investiga el uso de la mezcla de expertos (MOE) para el ajuste fino eficiente de AST. Específicamente, adaptamos el método Soft MoE reciente a nuestra configuración de eficiencia de parámetros, donde cada experto está representado por un módulo adaptador. Lo llamamos moa suave (mezcla suave de adaptadores). Soft-MOA logra la paridad de rendimiento con la contraparte densa (Dense-MoA) mientras recorta el costo computacional. Además, demuestra un rendimiento superior sobre el adaptador único tradicional.
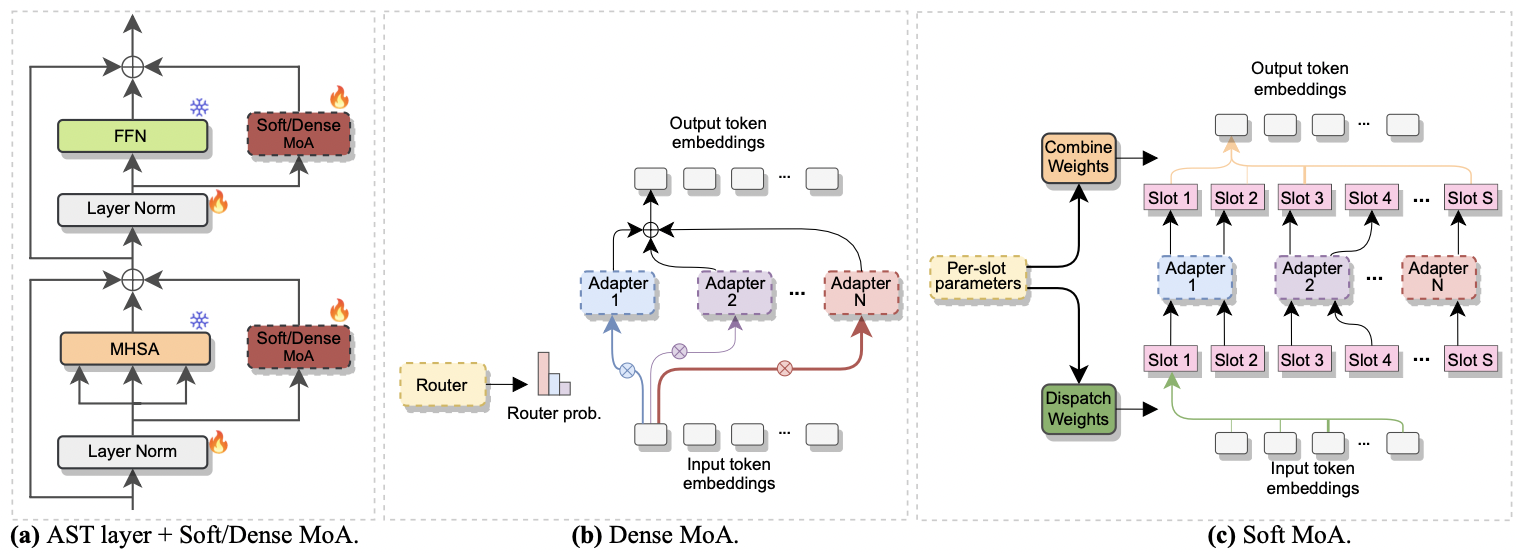 |
|---|
| a) Inserción del adaptador en cada capa AST. b) Dense-Moa. c) moa blando. |
Ejecutar un experimento con MOA denso y suave es una brisa. Seguimos el mismo procedimiento que utilizamos para el papel [1] . Solo necesitamos establecer el parámetro --method en Dense-MoA o Soft-MoA , y especificar algunos parámetros ad-hoc:
--reduction_rate_moa : exactamente como para los otros métodos PETL, necesitamos especificar la tasa de reducción para cada experto en adaptadores. Cuanto mayor sea la tasa de reducción, menor será la dimensión del cuello de botella.--adapter_type_moa : Pfeiffer o Houlsby Configuration.--location_moa : si aplicar las capas MOA suaves/densas paralelas a los bloques MHSA o FFN . If --Adapter_type_moa == Houlsby, MHSA y FFN se seleccionan de manera activa.--adapter_module_moa : el tipo de adaptador. Apoyamos el cuello de botella y Convpass a partir de ahora.--num_adapters : cuántos adaptadores se usan para cada capa MOA suave/densa. En nuestros experimentos, este valor oscila entre 2 y 15.--num_slots : el número de ranuras utilizadas en Soft-MoA. Por lo general, se establece en 1 o 2. [ NB : solo se usa en moa blando]--normalize : si L2 normaliza el vector de entrada y la matriz Phi como se propone en el papel MOE suave original (ver Sección 2.3, "Normalización"). Como se indica en el documento, la operación de normalización tiene poco impacto si el tamaño oculto del modelo es pequeño como en nuestro caso (por ejemplo, 768), por lo tanto, no usamos la normalización. [ NB : solo usado en moa blando]Por ejemplo, supongamos que queremos probar la MOA suave en el conjunto de datos FSC. Además, elegimos incluir la capa de moa suave solo en las capas MHSA, y usamos 7 adaptadores de botella. Entonces, el comando para ejecutar es:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

