PETL_AST
1.0.0
يحتوي هذا المستودع على الكود الرسمي للأوراق: تعلم النقل الفعال مع المعلمة لمحولات طيفية الصوت [1] ( مقبولة للنشر في ورشة عمل IEEE MLSP 2024 ) والضوء الفعال لمحولات الطيف الصوتي عبر الخليط الناعم من المحولات [2] ( مقبولة للوقت في البشر 2024 ).
تدرس كلتا الورقتين كيفية تطبيق أساليب التعلم النقل ( PETL ) الموفرة للمعلمة على نموذج محول الطيف الصوتي (AST) لمختلف مهام الصوت/الكلام. بينما يوفر [1] نظرة عامة شاملة على أساليب PETL (الضبط الفوري ، LORA ، المحولات) في ظل سيناريوهات وقيود مختلفة ، [2] يستكشف كيفية تسخير مزيج من الخبراء بفعالية بنية PETL.
أدناه ندرج جميع التفاصيل لتكرار نتائجنا. هام : تأكد من إعداد بيئة متوافقة مع تلك التي استخدمناها في تجاربنا ، لذا يرجى تثبيت إصدارات الحزم نفسها باستخدام ملف المتطلبات .
أومبرتو كابليازو ، دانييلي فالافينيا ، أليسيو بروتي ، مركو رافانيلي
تم قبول الورقة في ورشة عمل IEEE MLSP 2024 . تستكشف هذه الورقة استخدام طرق PETL المختلفة المطبقة على نموذج محول الطيف الصوتي لمختلف مهام معالجة الصوت والكلام. علاوة على ذلك ، نقترح تصميم محول جديد يستغل الوحدة النمطية لنموذج المطابقة ، مما يؤدي إلى أداء فائق على مقاربات PETL القياسية وتجاوز أو تحقيق التكافؤ في الأداء مع صقل كامل من خلال تحديث 0.29 ٪ فقط من المعلمات.
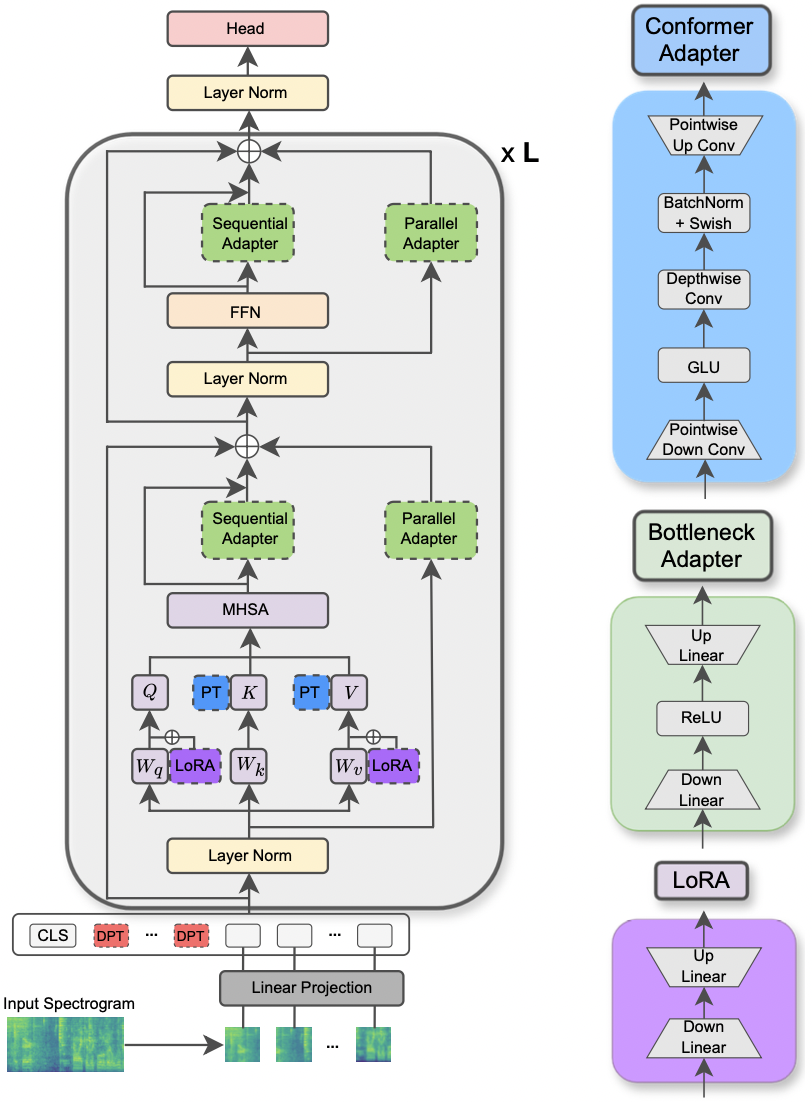 |
|---|
| توضيح نموذج AST وطرق PETL. |
يتم سرد المكتبات المطلوبة لتشغيل التجارب في ملف المتطلبات. قم بتشغيل الأمر أدناه لتثبيته.
pip install -r requirements.txt
أستخدم الأوزان والتحيزات (https://wandb.ai/site) لتتبع تجاربي (أوصي به بحرارة). ومع ذلك ، يمكنك إلغاء تنشيطه عن طريق الإعداد --use_wandb = False في سطر الأوامر.
أتوقع أن يكون المستخدم قد قام بالفعل بتنزيل مجموعات البيانات بنفسه.
لتشغيل تجربة ، كل ما تحتاجه هو استخدام Command python3 main.py متبوعًا ببعض الوسائط التي تم نقلها إلى سطر الأوامر لتحديد الإعداد. المعلمات الإلزامية هي:
--data_path : المسار إلى المجلد الذي يحتوي على مجموعة البيانات.--dataset_name : مجموعة البيانات المحددة. اعتبارًا من الآن ، تتوفر 5 مجموعات بيانات: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : طريقة PETL المحددة. تتبع قائمة أساليب PETL المدعومة: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . يرجى مراجعة الورقة الأخرى لتشغيل تجربة مع MONNANGE/SONENT MOA.--is_AST : إذا تم ضبطه على TRUE ، فإنه يستخدم النموذج AST تم تدريبه مسبقًا. إذا تم تعيينه على FALSE ، فإنه يستخدم النموذج WAV2VEC 2.0 تم تدريبه مسبقًا.main.py للحصول على وصف مفصل.hparams/train.yaml . تتوافق القيم الحالية مع تلك التي استخدمناها في تجاربنا والتي أدت إلى أفضل النتائج.كل طريقة PETL تأتي مع بعض المعلمات المحددة. نحن نقدم وصفا موجزا أدناه. لاحظ أننا هنا نتجنب تضمين المراجع للإيجاز ، يرجى الرجوع إلى الورقة.
reduction_rate_adapter -> يحكم عنق الزجاجة باهتة لوحدة المحول (على سبيل المثال ، إذا كان D هو البعد المخفي و RR هو معدل التخفيض ، فإن خافت للمحول هو D /RR) ؛ seq_or_par -> ما إذا كنت تريد إدراج المحول بالتوازي أو بالتتابع ؛ adapter_type -> إما تكوين pfeiffer أو houlsby ؛ adapter_block -> إما عنق الزجاجة أو المطابقة (تصميم المحول المقترح) ؛ apply_residual -> ما إذا كنت تريد تطبيق الاتصالات المتبقية أم لا. كما ورد في الورقة ، يجب أن يستغني المحول الموازي مع المخلفات ، في حين يستفيد المحول المتسلسل من البقايا.prompt_len_prompt > كم عدد المطالبات المراد استخدامها ؛ is_deep_prompt > ضبط على True إذا كنت تريد تمكين صقل الموجهات العميقة (DPT) ، وإلا الضبط الضحل (SPT) ؛ drop_prompt -> معدل التسرب للمطالبات. في تجاربنا قمنا بتعيينها على 0. .reduction_rate_lora -> يرجى الاطلاع على reduction_rate_adapter ؛ alpha_lora -> lora_alpha كما هو محدد في الورقة الأصلية. يستخدم هذا للتوسع (على سبيل المثال ، s = alpha_lora/rr).على سبيل المثال ، لنفترض أننا نريد اختبار المحول مع التكوين المطابق ، الموازي ، pfeiffer ، RR = 64 ، واختباره على مجموعة بيانات FSC لنموذج AST. ثم ، أمر التشغيل هو:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' إذا كنت ترغب في تشغيل تجارب تعليمية قليلة ، فأنت بحاجة فقط إلى تعيين العلامة- --is_few_shot_exp إلى True وتحديد رقم العينات لكل فئة- --few_shot_samples .
من فضلك ، تواصل معي على: umbertocappellazzo [at] gmail [dot] com لأي سؤال.
نقر بدعم تحالف البحوث الرقمية في كندا (Alliancecan.ca).
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo ، Daniele Falavigna ، Alessio Brutti
تم قبول الورقة في interspeech 2024 . وهو يبحث في استخدام مزيج من الخبراء (MOE) من أجل الضبط الفعال لـ AST. على وجه التحديد ، نحن نتكيف مع طريقة MOE الناعمة الحديثة مع إعدادنا الموفرة للمعلمة ، حيث يتم تمثيل كل خبير بوحدة محول. نسميها moa soft (مزيج ناعم من المحولات). يحقق Soft-Moa تكافؤ الأداء مع النظير الكثيف (الكثيف MOA) أثناء تقليص التكلفة الحسابية. علاوة على ذلك ، فإنه يوضح الأداء المتفوق على المحول الفردي التقليدي.
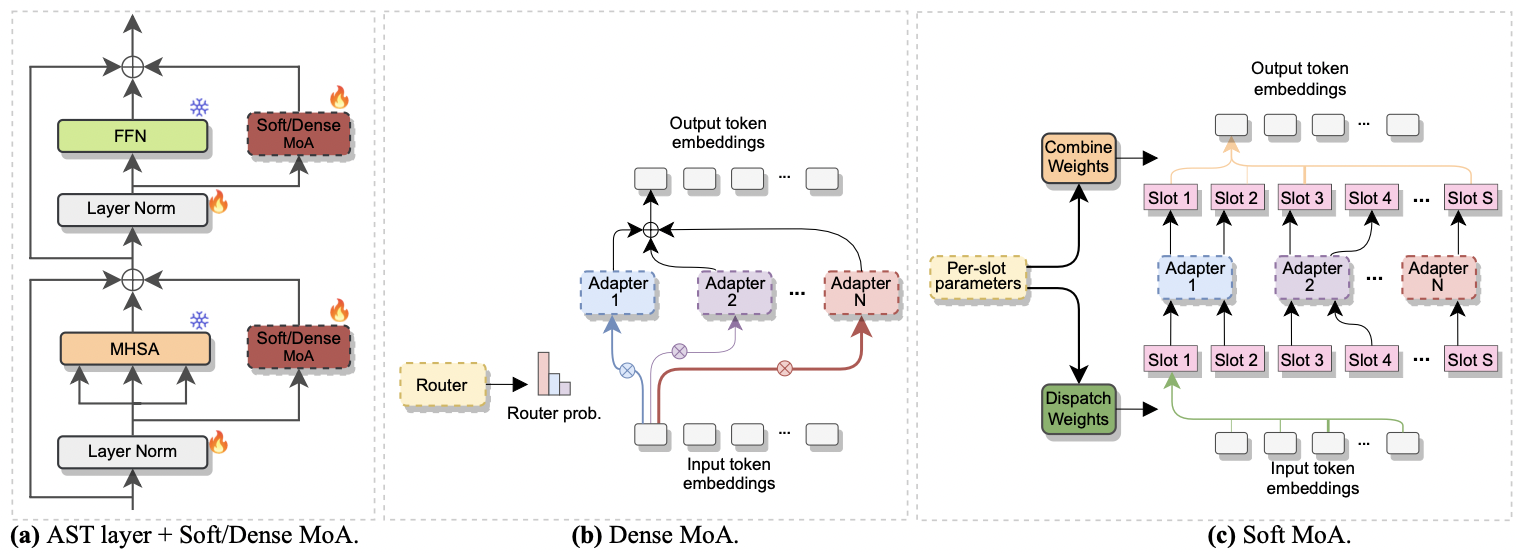 |
|---|
| أ) محول إدراج في كل طبقة AST. ب) كثيف MOA. ج) لينة MOA. |
تشغيل تجربة مع MOA كثيفة وناعمة هو نسيم. نتبع نفس الإجراء الذي استخدمناه للورق [1] . نحتاج فقط إلى تعيين المعلمة --method على Dense-MoA أو Soft-MoA ، وتحديد بعض المعلمات المخصصة:
--reduction_rate_moa : تمامًا كما هو الحال بالنسبة لطرق PETL الأخرى ، نحتاج إلى تحديد معدل التخفيض لكل خبير محول. كلما ارتفع معدل التخفيض ، كلما كان بعد عنق الزجاجة.--adapter_type_moa : تكوين Pfeiffer أو Houlsby .--location_moa : ما إذا كنت تريد تطبيق طبقات وزارة الزراعة الناعمة/الكثيفة بالتوازي مع كتل MHSA أو FFN . if -adapter_type_moa == houlsby و mhsa و ffn يتم اختيارهم بشكل عام.--adapter_module_moa : نوع المحول. نحن ندعم عنق الزجاجة والمنافسة حتى الآن.--num_adapters : كم عدد المحولات المستخدمة لكل طبقة MOA الناعمة/الكثيفة. في تجاربنا ، تتراوح هذه القيمة بين 2 و 15.--num_slots : عدد الفتحات المستخدمة في MOA Soft. عادة ما يتم تعيينه على 1 أو 2. [ NB : يستخدم فقط في MOA Soft]--normalize : ما إذا كان إلى L2 تطبيع متجه الإدخال ومصفوفة PHI كما هو مقترح في ورق Moe الناعم الأصلي (انظر القسم 2.3 ، "التطبيع"). كما هو مذكور في الورقة ، فإن عملية التطبيع لها تأثير ضئيل إذا كان الحجم المخفي للنموذج صغيرًا كما في حالتنا (على سبيل المثال ، 768) ، وبالتالي لم نستخدم التطبيع. [ NB : يستخدم فقط في moa soft]على سبيل المثال ، لنفترض أننا نريد اختبار moa soft على مجموعة بيانات FSC. بالإضافة إلى ذلك ، نختار تضمين طبقة MoA Soft فقط في طبقات MHSA ، ونستخدم 7 محولات Botteneck. ثم ، أمر التشغيل هو:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

