PETL_AST
1.0.0
Этот репозиторий содержит Официальный код документов: Параметр-эффективное обучение трансферу аудио-спектрограммы трансформаторов [1] ( принято для публикации на семинаре IEEE MLSP 2024 года ) и эффективная тонкая настройка трансформеров аудиопрограммы через мягкую смесь адаптеров [2] ( принято к публикации в Interspeech 2024 ).
Обе работы изучают, как применить методы, эффективные для параметров переноса ( PETL ), к модели трансформатора аудиопрограммы (AST) для различных задач по аудио/речи. Принимая во внимание, что [1] предоставляет всесторонний обзор методов PETL (быстро настройка, LORA, адаптеры) в различных сценариях и ограничениях, [2] исследует, как эффективно использовать смесь архитектуры экспертов для PETL.
Ниже мы включаем все детали, чтобы воспроизвести наши результаты. ВАЖНО : Убедитесь, что установите среду, которая совместима с той, которую мы использовали для наших экспериментов, поэтому, пожалуйста, установите те же версии пакетов, используя файл Telect.txt .
Умберто Каппеллаццо, Даниэле Фалавинга, Алессио Брутти, Мирко Раванелли
Бумага была принята на семинаре IEEE MLSP 2024 года . В этой статье рассматривается использование различных методов Petl , применяемых к модели трансформатора аудиопрограммы для различных задач обработки аудио и речи. Кроме того, мы предлагаем новую конструкцию адаптера, которая использует модуль свертки конформерной модели, что приводит к превосходной производительности по сравнению с стандартными подходами Petl и превзойденным или достижению паритета производительности с полной точной настройкой, обновив только 0,29% параметров.
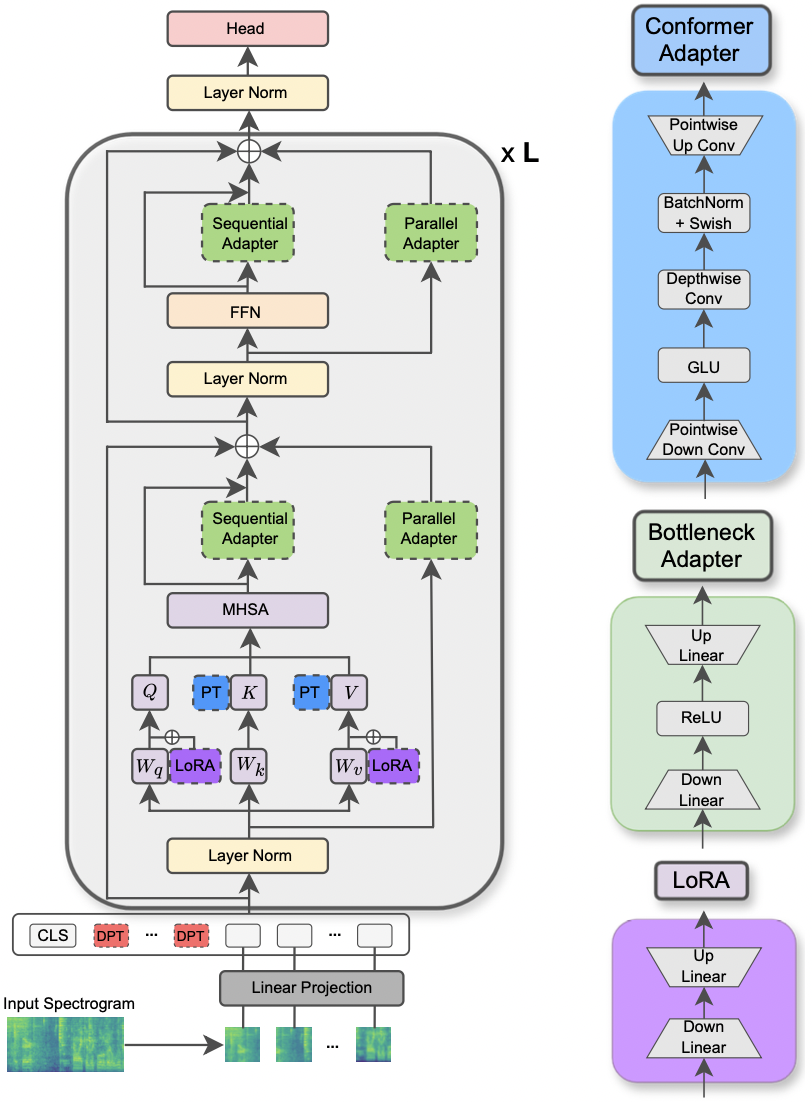 |
|---|
| Иллюстрация модели AST и методов PETL. |
Запрашиваемые библиотеки для запуска экспериментов перечислены в файле TEDS.TXT. Запустите команду ниже, чтобы установить их.
pip install -r requirements.txt
Я использую веса и смещения (https://wandb.ai/site) для отслеживания моих экспериментов (я тепло рекомендую это). Тем не менее, вы можете деактивировать его, установив --use_wandb = False в командной строке.
Я ожидаю, что пользователь уже загрузил наборы данных собой.
Чтобы запустить эксперимент, все, что вам нужно, состоит в том, чтобы использовать команду python3 main.py за которым следует некоторые аргументы, передаваемые в командную строку, чтобы указать настройку. Обязательные параметры:
--data_path : путь к папке, содержащей набор данных.--dataset_name : выбранный набор данных. На данный момент доступны 5 наборов данных: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : выбранный метод Petl. Список поддерживаемых методов PETL следует: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . Пожалуйста, ознакомьтесь с другой бумагой для проведения эксперимента с плотным/мягким моа.--is_AST : если установлено true, он использует предварительно обученную модель AST. Если установить FALSE, он использует предварительную модель WAV2VEC 2.0.main.py для подробного описания.hparams/train.yaml . Текущие значения соответствуют тем, которые мы использовали для наших экспериментов, и это привело к наилучшим результатам.Каждый метод Petl поставляется с некоторыми конкретными параметрами. Мы предоставляем краткое описание ниже. Обратите внимание, что здесь мы избегаем включения ссылок на краткость, пожалуйста, обратитесь к статье.
reduction_rate_adapter -> Он управляет узким местом тумбула модуля адаптера (например, если D -скрытое измерение, а RR -скорость сокращения, то DIM из адаптера составляет D /RR); seq_or_par -> Вставить параллель адаптера или последовательно; adapter_type -> либо Pfeiffer, либо конфигурация Houlsby; adapter_block -> либо узкое место, либо конформер (предлагаемый нами дизайн адаптера); apply_residual -> Применять остаточные соединения или нет. Как сообщается в статье, параллельный адаптер должен распространяться с остатками, тогда как последовательный адаптер выгоды от остатков.prompt_len_prompt > Сколько подсказок использовать; is_deep_prompt > установить в True , если вы хотите включить глубокую подстройку (DPT), в противном случае неглубокая подсказка (SPT); drop_prompt -> Скорость отсева для подсказок. В наших экспериментах мы установили его на 0. .reduction_rate_lora ->, пожалуйста, см. reduction_rate_adapter ; alpha_lora -> lora_alpha, как определено в исходной статье. Это используется для масштабирования (например, s = alpha_lora/rr).Например, предположим, что мы хотим проверить адаптер с конформером конфигурации, параллелью, Pfeiffer, RR = 64 и протестировать его в наборе данных FSC для модели AST. Затем команда для запуска:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' Если вы хотите провести несколько экспериментов по обучению, вам просто нужно установить флаг- --is_few_shot_exp на True и указать # образцов на класс --few_shot_samples .
Пожалуйста, обратитесь ко мне по адресу: umbertocappellazzo [at] gmail [dot] com для любого вопроса.
Мы признаем поддержку Альянсу цифровых исследований Канады (Alliancecan.ca).
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Умберто Каппеллаццо, Даниэле Фалавинга, Алессио Брутти
Бумага была принята в межспик. 2024 . Он исследует использование смеси экспертов (MOE) для эффективной тонкой настройки AST. В частности, мы адаптируем недавний метод Soft MOE к нашему параметрам-эффективному настройке, где каждый эксперт представлен модулем адаптера. Мы называем это мягким-моа (мягкая смесь адаптеров). Soft-Moa достигает паритета производительности с плотным аналогом (Dense-MoA), обрезая вычислительные затраты. Более того, он демонстрирует превосходную производительность по сравнению с традиционным единственным адаптером.
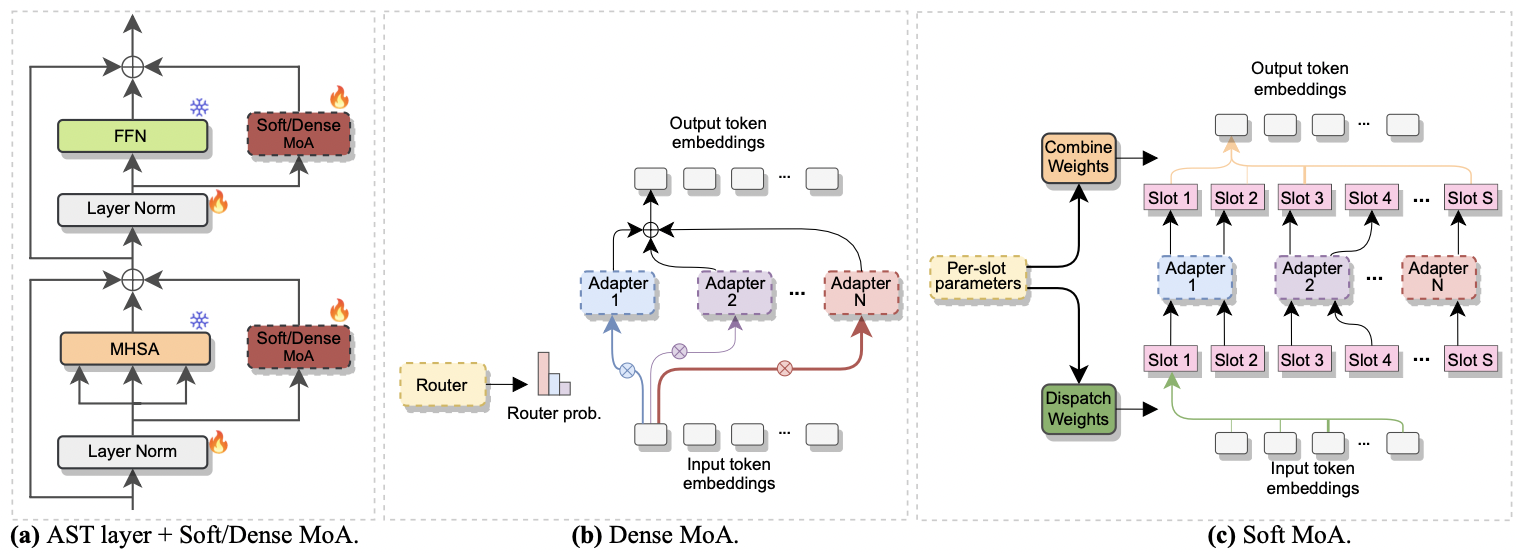 |
|---|
| а) вставка адаптера в каждый слой AST. б) Плотный моа. в) мягкий-моа. |
Пропустить эксперимент с плотным и мягким MOA - это ветерок. Мы следуем той же процедуре, которую мы использовали для бумаги [1] . Нам просто нужно установить параметр --method на Dense-MoA или Soft-MoA , и указать некоторые специальные параметры:
--reduction_rate_moa : точно так же, как и для других методов Petl, нам необходимо указать скорость сокращения для каждого эксперта по адаптеру. Чем выше скорость снижения, тем меньше размер узкого места.--adapter_type_moa : pfeiffer или конфигурация Houlsby .--location_moa : применять мягкие/плотные слои MOA, параллельные блокам MHSA или FFN . If -adapter_type_moa == Houlsby, MHSA и FFN выбираются.--adapter_module_moa : тип адаптера. На данный момент мы поддерживаем узкое место и консультации .--num_adapters : Сколько адаптеров используется для каждого мягкого/плотного слоя MOA. В наших экспериментах это значение колеблется от 2 до 15.--num_slots : количество слотов, используемых в Soft-MOA. Обычно это установлено в 1 или 2. [ NB : используется только в Soft-Moa]--normalize : но нормализовать ли L2 входной вектор и матрицу PHI, как предложено в оригинальной мягкой бумаге MOE (см. Раздел 2.3, «Нормализация»). Как указано в статье, операция нормализации оказывает небольшое влияние, если скрытый размер модели невелик, как в нашем случае (например, 768), поэтому мы не использовали нормализацию. [ NB : Используется только в Soft-Moa]Например, предположим, что мы хотим проверить Soft-MOA на наборе данных FSC. Кроме того, мы решили включить слой мягкого моа только в слои MHSA, и мы используем 7 адаптеров Botteneck. Затем команда для запуска:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

