PETL_AST
1.0.0
Repositori ini berisi kode resmi makalah: Transfer Parameter-Efisien Pembelajaran Audio Spectrogram Transformers [1] ( diterima untuk publikasi pada lokakarya 2024 IEEE MLSP ) dan penyempurnaan efisien dari transformator spektrogram audio melalui campuran soft adapter [2] ( diterima untuk dipublikasikan di Interspeech 202 ).
Kedua makalah itu mempelajari cara menerapkan metode pembelajaran transfer-efisien parameter ( PETL ) ke model transformator spektrogram audio (AST) untuk berbagai tugas hilir audio/ucapan. Sedangkan [1] memberikan tinjauan komprehensif tentang metode PETL (tuning prompt, LORA, adaptor) di bawah skenario dan kendala yang berbeda, [2] mengeksplorasi cara memanfaatkan campuran arsitektur PETL.
Di bawah ini kami menyertakan semua detail untuk mereplikasi hasil kami. Penting : Pastikan untuk mengatur lingkungan yang kompatibel dengan yang kami gunakan untuk percobaan kami, jadi silakan instal versi paket yang sama menggunakan file persyaratan.txt .
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
Makalah ini telah diterima di Workshop IEEE MLSP 2024 . Makalah ini mengeksplorasi penggunaan metode PETL yang berbeda yang diterapkan pada model transformator spektrogram audio untuk berbagai tugas pemrosesan audio dan ucapan. Selain itu, kami mengusulkan desain adaptor baru yang mengeksploitasi modul konvolusi model konformer, yang mengarah ke kinerja yang unggul selama pendekatan PETL standar dan melampaui atau mencapai paritas kinerja dengan penyesuaian penuh dengan memperbarui hanya 0,29% dari parameter.
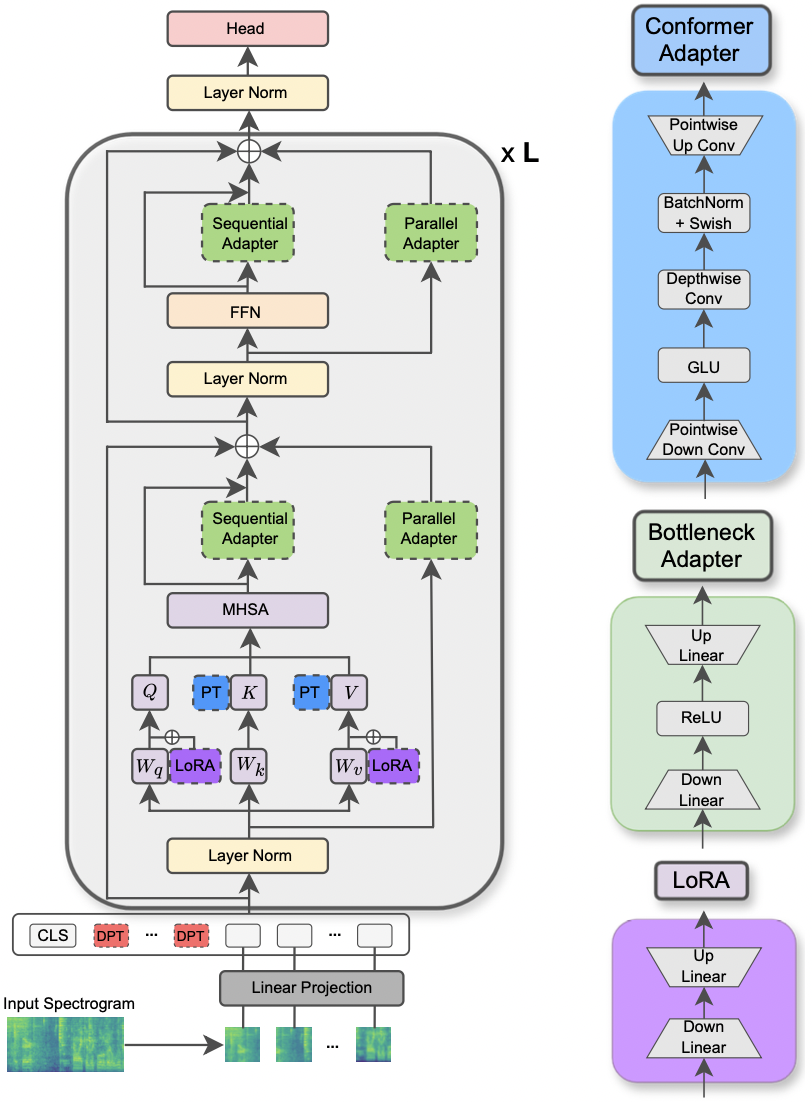 |
|---|
| Ilustrasi model AST dan metode PETL. |
Perpustakaan yang diminta untuk menjalankan percobaan tercantum dalam file persyaratan.txt. Jalankan perintah di bawah ini untuk menginstalnya.
pip install -r requirements.txt
Saya menggunakan bobot dan bias (https://wandb.ai/site) untuk melacak eksperimen saya (saya dengan hangat merekomendasikannya). Meskipun demikian, Anda dapat menonaktifkannya dengan mengatur --use_wandb = False di baris perintah.
Saya berharap pengguna telah mengunduh dataset oleh dirinya sendiri.
Untuk menjalankan percobaan, semua yang Anda butuhkan adalah menggunakan perintah python3 main.py diikuti oleh beberapa argumen yang diteruskan ke baris perintah untuk menentukan pengaturan. Parameter wajib adalah:
--data_path : Jalur ke folder yang berisi dataset.--dataset_name : Dataset yang dipilih. Sampai sekarang, 5 set data tersedia: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : Metode PETL yang dipilih. Daftar metode PETL yang didukung mengikuti: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . Silakan periksa kertas lain untuk menjalankan percobaan dengan padat/soft-moA.--is_AST : Jika diatur ke true, ia menggunakan model pra-terlatih AST. Jika diatur ke false, ia menggunakan model pra-terlatih WAV2VEC 2.0.main.py untuk deskripsi terperinci.hparams/train.yaml . Nilai saat ini sesuai dengan yang kami gunakan untuk percobaan kami dan itu menghasilkan hasil terbaik.Setiap metode PETL dilengkapi dengan beberapa parameter spesifik. Kami memberikan deskripsi singkat di bawah ini. Perhatikan bahwa di sini kita menghindari memasukkan referensi untuk singkatnya, silakan merujuk ke kertas.
reduction_rate_adapter -> Ini mengatur kemunduran bottleneck dari modul adaptor (misalnya, jika d adalah dimensi tersembunyi dan RR adalah laju reduksi, maka redupsi adaptor adalah D /RR); seq_or_par -> apakah akan memasukkan adaptor paralel atau berurutan; adapter_type -> baik konfigurasi pfeiffer atau houlsby; adapter_block -> Bottleneck atau konformer (desain adaptor yang kami usulkan); apply_residual -> apakah akan menerapkan koneksi residual atau tidak. Seperti yang dilaporkan dalam makalah, adaptor paralel harus membuang residu, sedangkan manfaat adaptor berurutan dari residu.prompt_len_prompt > berapa banyak petunjuk untuk digunakan; is_deep_prompt > diatur ke True jika Anda ingin mengaktifkan deep prompt tuning (DPT), jika tidak tuning prompt dangkal (SPT); drop_prompt -> Tingkat putus sekolah untuk petunjuk. Dalam percobaan kami, kami mengaturnya ke 0. .reduction_rate_lora -> silakan lihat reduction_rate_adapter ; alpha_lora -> lora_alpha sebagaimana didefinisikan dalam kertas asli. Ini digunakan untuk penskalaan (misalnya, s = alpha_lora/rr).Sebagai contoh, misalkan kita ingin menguji adaptor dengan konfigurasi konfigurasi, paralel, pfeiffer, rr = 64, dan mengujinya pada dataset FSC untuk model AST. Kemudian, perintah yang akan dijalankan adalah:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' Jika Anda ingin menjalankan beberapa eksperimen pembelajaran shot, Anda hanya perlu mengatur bendera --is_few_shot_exp ke True dan menentukan # sampel per kelas --few_shot_samples .
Tolong, hubungi saya di: Umbertocappellazzo [at] gmail [dot] com untuk pertanyaan apa pun.
Kami mengakui dukungan dari Aliansi Penelitian Digital Kanada (Alliancecan.ca).
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti
Makalah ini telah diterima di Interspeech 2024 . Ini menyelidiki penggunaan campuran ahli (MOE) untuk penyempurnaan yang efisien dari AST. Secara khusus, kami mengadaptasi metode MOE lunak baru-baru ini dengan pengaturan parameter-efisien kami, di mana setiap ahli diwakili oleh modul adaptor. Kami menyebutnya soft-moA (campuran lembut adaptor). Soft-MoA mencapai paritas kinerja dengan rekan padat (padat-MOA) sambil memotong biaya komputasi. Selain itu, ini menunjukkan kinerja yang unggul pada adaptor tunggal tradisional.
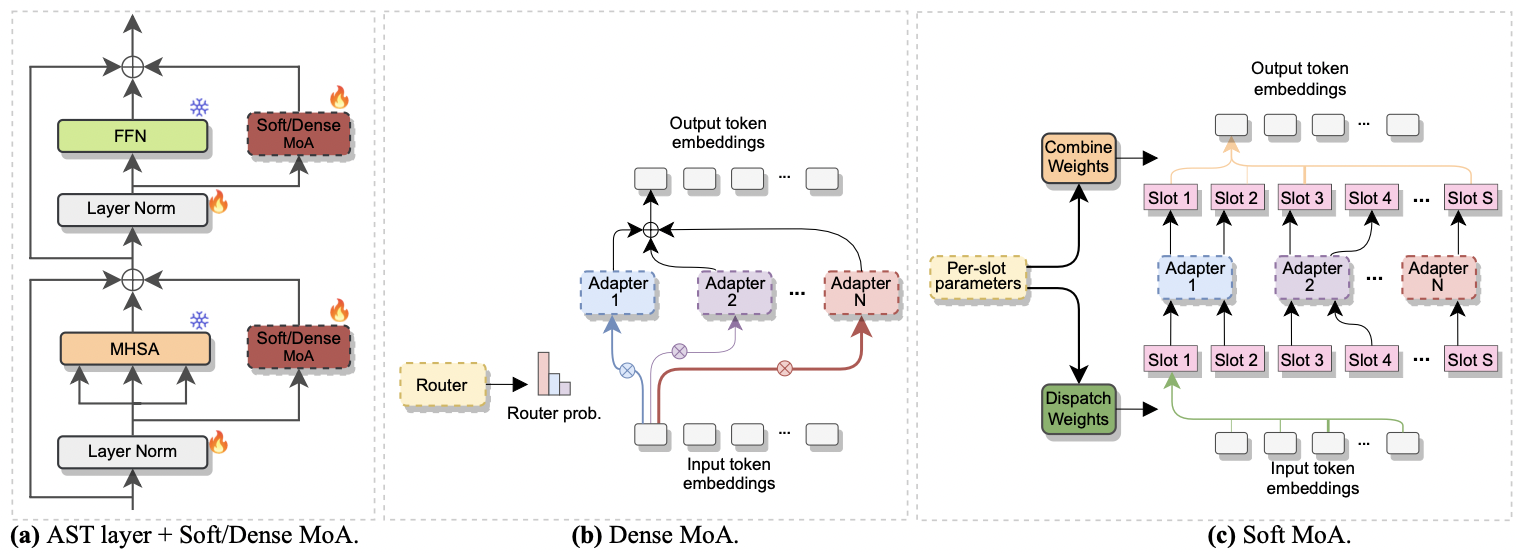 |
|---|
| a) Penyisipan adaptor ke setiap lapisan AST. b) padat-moa. c) Soft-moA. |
Menjalankan eksperimen dengan moa yang padat dan lembut sangat mudah. Kami mengikuti prosedur yang sama yang kami gunakan untuk kertas [1] . Kita hanya perlu mengatur parameter --method menjadi Dense-MoA atau Soft-MoA , dan menentukan beberapa parameter ad-hoc:
--reduction_rate_moa : Tepat untuk metode PETL lainnya, kita perlu menentukan tingkat reduksi untuk setiap ahli adaptor. Semakin tinggi laju reduksi, semakin kecil dimensi bottleneck.--adapter_type_moa : konfigurasi pfeiffer atau houlsby .--location_moa : Apakah akan menerapkan lapisan MOA lunak/padat sejajar dengan blok MHSA atau FFN . If --Adapter_type_moa == Houlsby, MHSA dan FFN dipilih secara auomatik.--adapter_module_moa : Jenis adaptor. Kami mendukung bottleneck dan convpass sampai sekarang.--num_adapters : Berapa banyak adaptor yang digunakan untuk setiap lapisan MOA lunak/padat. Dalam percobaan kami, nilai ini berkisar antara 2 dan 15.--num_slots : Jumlah slot yang digunakan dalam soft-moA. Biasanya diatur ke 1 atau 2. [ NB : hanya digunakan dalam soft-moA]--normalize : Apakah L2 menormalkan vektor input dan matriks PHI seperti yang diusulkan dalam kertas MOE lunak asli (lihat Bagian 2.3, "Normalisasi"). Seperti yang dinyatakan dalam makalah, operasi normalisasi memiliki sedikit dampak jika ukuran tersembunyi model kecil seperti dalam kasus kami (misalnya, 768), sehingga kami tidak menggunakan normalisasi. [ NB : Hanya digunakan dalam soft-moA]Misalnya, misalkan kita ingin menguji soft-moA pada dataset FSC. Plus, kami memilih untuk memasukkan lapisan soft-moA hanya di lapisan MHSA, dan kami menggunakan 7 adaptor botteneck. Kemudian, perintah yang akan dijalankan adalah:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

