PETL_AST
1.0.0
Ce référentiel contient le code officiel des articles: apprentissage transfert économe en paramètres des transformateurs de spectrogrammes audio [1] ( accepté pour publication à l'atelier de MLSP IEEE 2024 ) et un réglage fin efficace du spectrogramme audio via le mélange doux des adaptateurs [2] ( accepté pour la publication à l'interstrogram 2024 ).
Les deux articles étudient comment appliquer les méthodes d'apprentissage par transfert économe en paramètres ( PETL ) au modèle de transformateur de spectrogramme audio (AST) pour diverses tâches audio / discours en aval. Alors que [1] fournit un aperçu complet des méthodes PETL (tun prompt, LORA, adaptateurs) dans différents scénarios et contraintes, [2] explore comment exploiter efficacement le mélange d'architecture d'experts pour PETL.
Ci-dessous, nous incluons tous les détails pour reproduire nos résultats. IMPORTANT : Assurez-vous de configurer un environnement compatible avec celui que nous avons utilisé pour nos expériences, veuillez donc installer les mêmes versions de packages à l'aide du fichier exigence.txt .
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
Le document a été accepté lors de l'atelier MLSP de l'IEEE 2024 . Cet article explore l'utilisation de différentes méthodes PETL appliquées au modèle de transformateur de spectrogramme audio pour diverses tâches de traitement audio et de la parole. En outre, nous proposons une nouvelle conception d'adaptateur qui exploite le module Convolution du modèle CONFORMER, conduisant à des performances supérieures sur les approches PETL standard et dépassant ou atteignant la parité des performances avec une réglage fin complet en mettant à jour seulement 0,29% des paramètres.
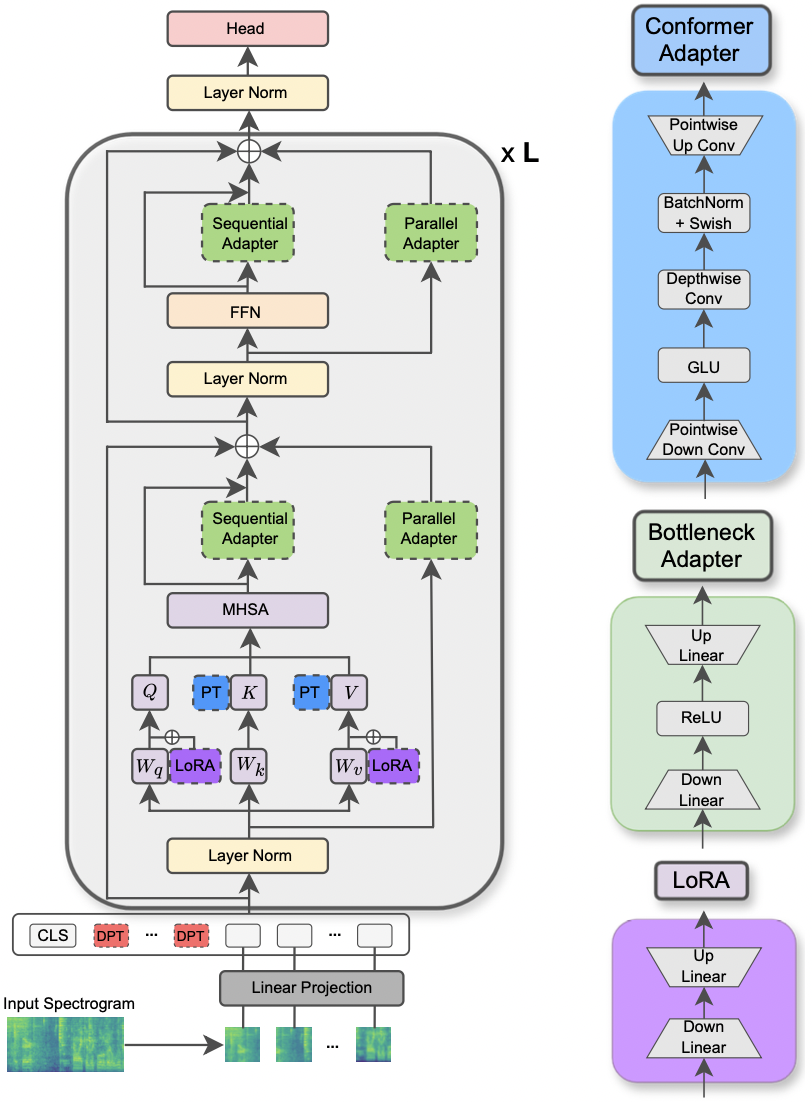 |
|---|
| Illustration du modèle AST et des méthodes PETL. |
Les bibliothèques demandées pour exécuter les expériences sont répertoriées dans le fichier exigence.txt. Exécutez la commande ci-dessous pour les installer.
pip install -r requirements.txt
J'utilise des poids et des biais (https://wandb.ai/site) pour suivre mes expériences (je le recommande chaleureusement). Néanmoins, vous pouvez le désactiver en définissant --use_wandb = False dans la ligne de commande.
Je m'attends à ce que l'utilisateur ait déjà téléchargé les ensembles de données par lui-même.
Pour exécuter une expérience, tout ce dont vous avez besoin est d'utiliser la commande python3 main.py suivie de certains arguments transmis à la ligne de commande pour spécifier le paramètre. Les paramètres obligatoires sont:
--data_path : le chemin vers le dossier contenant l'ensemble de données.--dataset_name : l'ensemble de données sélectionné. À partir de maintenant, 5 ensembles de données sont disponibles: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : la méthode PETL sélectionnée. Une liste des méthodes PETL prises en charge suit: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . Veuillez consulter l'autre article pour exécuter une expérience avec dense / soft-moa.--is_AST : Si défini sur true, il utilise le modèle pré-formé AST. S'il est défini sur False, il utilise le modèle pré-formé WAV2VEC 2.0.main.py pour une description détaillée.hparams/train.yaml . Les valeurs actuelles correspondent à celles que nous avons utilisées pour nos expériences et qui ont conduit aux meilleurs résultats.Chaque méthode PETL est livrée avec des paramètres spécifiques. Nous fournissons une brève description ci-dessous. Notez que nous évitons ici d'inclure les références pour Brevity, veuillez vous référer au document.
reduction_rate_adapter -> Il gouverne le DIM à goulot d'étranglement du module de l'adaptateur (par exemple, si d est la dimension cachée et RR est le taux de réduction, alors le dim de l'adaptateur est d / rr); seq_or_par -> Que ce soit pour insérer l'adaptateur parallèle ou séquentiellement; adapter_type -> Pfeiffer ou Houlsby Configuration; adapter_block -> goulot d'étranglement ou conformer (notre conception d'adaptateur proposée); apply_residual -> Que ce soit pour appliquer des connexions résiduelles ou non. Comme indiqué dans l'article, l'adaptateur parallèle doit se passer des résidus, tandis que l'adaptateur séquentiel bénéficie des résidus.prompt_len_prompt -> combien d'invites à utiliser; is_deep_prompt -> réglé sur True si vous souhaitez activer le réglage invite profond (DPT), sinon peu profond-tun (SPT); drop_prompt -> Le taux d'abandon pour les invites. Dans nos expériences, nous l'avons réglé sur 0. ..reduction_rate_lora -> Veuillez voir reduction_rate_adapter ; alpha_lora -> le lora_alpha tel que défini dans l'article d'origine. Ceci est utilisé pour la mise à l'échelle (par exemple, s = alpha_lora / rr).Par exemple, supposons que nous voulons tester l'adaptateur avec le conformer de configuration, parallèle, pfeiffer, rr = 64 et le tester sur l'ensemble de données FSC pour le modèle AST. Ensuite, la commande à exécuter est:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' Si vous souhaitez exécuter des expériences d'apprentissage à quelques coups, il vous suffit de définir l'indicateur --is_few_shot_exp sur True et de spécifier le # d'échantillons par classe --few_shot_samples .
S'il vous plaît, contactez-moi à: Umbertocappellazzo [at] gmail [dot] com pour toute question.
Nous reconnaissons le soutien de la Digital Research Alliance of Canada (Alliancecan.ca).
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti
Le document a été accepté à Interspeech 2024 . Il étudie l'utilisation du mélange d'experts (MOE) pour le réglage fin efficace de l'AST. Plus précisément, nous adaptons la méthode récente Soft MOE à notre paramètre économe en paramètres, où chaque expert est représenté par un module d'adaptateur. Nous l'appelons Soft-moa (mélange doux d'adaptateurs). Soft-MOA atteint la parité des performances avec le homologue dense (MOA dense) tout en réduisant le coût de calcul. De plus, il démontre des performances supérieures sur l'adaptateur unique traditionnel.
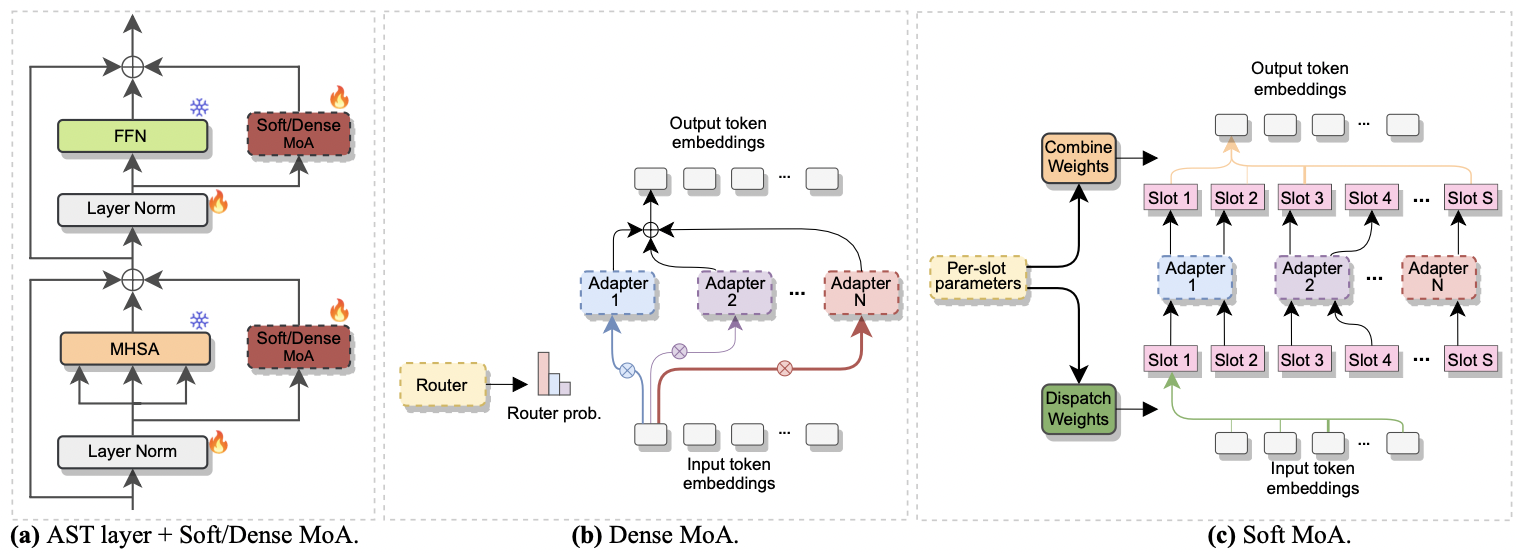 |
|---|
| a) Insertion de l'adaptateur dans chaque couche AST. b) Moa dense. c) Soft-moa. |
Exécuter une expérience avec des MOA denses et doux est un jeu d'enfant. Nous suivons la même procédure que nous avons utilisée pour le papier [1] . Nous avons juste besoin de définir le paramètre --method sur Dense-MoA ou Soft-MoA , et de spécifier certains paramètres ad hoc:
--reduction_rate_moa : exactement comme pour les autres méthodes PETL, nous devons spécifier le taux de réduction pour chaque expert adaptateur. Plus le taux de réduction est élevé, plus la dimension du goulot d'étranglement est faible.--adapter_type_moa : configuration pfeiffer ou houlsby .--location_moa : Que ce soit pour appliquer les couches MOA molles / denses parallèles aux blocs MHSA ou FFN . Si --adapter_type_moa == houlsby, mhsa et ffn sont sélectionnés auomatiquement.--adapter_module_moa : le type d'adaptateur. Nous soutenons le goulot d'étranglement et le convassage à partir de maintenant.--num_adapters : combien d'adaptateurs sont utilisés pour chaque couche moa douce / dense. Dans nos expériences, cette valeur varie entre 2 et 15.--num_slots : Le nombre de machines à sous utilisés dans Soft-MoA. Habituellement, il est réglé sur 1 ou 2. [ NB : uniquement utilisé dans Soft-MoA]--normalize : s'il faut normaliser L2 le vecteur d'entrée et la matrice PHI comme proposé dans le papier Soft MOE d'origine (voir la section 2.3, "normalisation"). Comme indiqué dans l'article, l'opération de normalisation a peu d'impact si la taille cachée du modèle est petite comme dans notre cas (par exemple, 768), nous n'avons donc pas utilisé la normalisation. [ NB : uniquement utilisé dans Soft-moa]Par exemple, supposons que nous voulons tester Soft-MoA sur l'ensemble de données FSC. De plus, nous choisissons d'inclure la couche de Soft-MOA uniquement dans les couches MHSA, et nous utilisons 7 adaptateurs Botteneck. Ensuite, la commande à exécuter est:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

