PETL_AST
1.0.0
พื้นที่เก็บข้อมูลนี้มีรหัสอย่างเป็นทางการของเอกสาร: การเรียนรู้การถ่ายโอนพารามิเตอร์-ประสิทธิภาพการเรียน รู้ของหม้อแปลงเสียงสเปกโทรครัม [1] ( ยอมรับสำหรับการตีพิมพ์ในการประชุมเชิงปฏิบัติการ IEEE MLSP 2024 )
เอกสารทั้งสองศึกษาวิธีการใช้วิธีการเรียนรู้การถ่ายโอนพารามิเตอร์ ( PETL ) กับโมเดล Audio Spectrogram Transformer (AST) สำหรับงานเสียง/คำพูดที่หลากหลาย ในขณะที่ [1] ให้ภาพรวมที่ครอบคลุมของวิธีการ PETL (การปรับแต่ง, Lora, อะแดปเตอร์) ภายใต้สถานการณ์และข้อ จำกัด ที่แตกต่างกัน [2] สำรวจวิธีการควบคุมส่วนผสมของสถาปัตยกรรมผู้เชี่ยวชาญสำหรับ PETL ได้อย่างมีประสิทธิภาพ
ด้านล่างเรารวมรายละเอียดทั้งหมดเพื่อทำซ้ำผลลัพธ์ของเรา สำคัญ : ตรวจสอบให้แน่ใจว่าได้ตั้งค่าสภาพแวดล้อมที่เข้ากันได้กับสิ่งที่เราใช้สำหรับการทดลองของเราดังนั้นโปรดติดตั้งเวอร์ชันแพ็คเกจเดียวกันโดยใช้ไฟล์ ข้อกำหนด . txt
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
กระดาษได้รับการยอมรับในการประชุมเชิงปฏิบัติการ IEEE MLSP 2024 บทความนี้สำรวจการใช้วิธีการ PETL ที่แตกต่างกันที่ใช้กับโมเดลหม้อแปลงเสียงสเปกโตรแกรมสำหรับงานเสียงและการประมวลผลเสียงที่หลากหลาย นอกจากนี้เรายังนำเสนอการออกแบบอะแดปเตอร์ใหม่ที่ใช้ประโยชน์จากโมดูล convolution ของโมเดล Conformer ซึ่งนำไปสู่ประสิทธิภาพที่เหนือกว่าวิธีการ PETL มาตรฐานและเหนือกว่าหรือบรรลุความเท่าเทียมกันของประสิทธิภาพด้วยการปรับแต่งอย่างสมบูรณ์โดยการอัปเดตเพียง 0.29% ของพารามิเตอร์
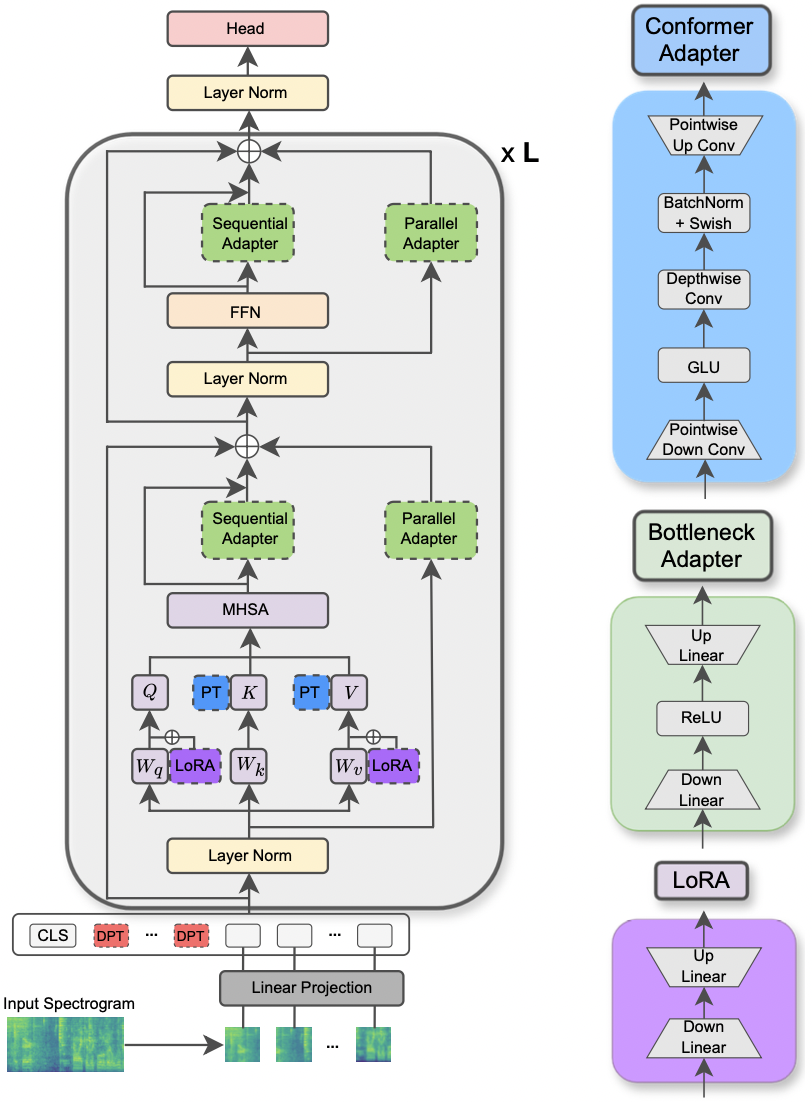 |
|---|
| ภาพประกอบของโมเดล AST และวิธี PETL |
ไลบรารีที่ร้องขอสำหรับการรันการทดลองแสดงอยู่ในไฟล์ข้อกำหนด. txt เรียกใช้คำสั่งด้านล่างเพื่อติดตั้ง
pip install -r requirements.txt
ฉันใช้น้ำหนักและอคติ (https://wandb.ai/site) เพื่อติดตามการทดลองของฉัน (ฉันขอแนะนำอย่างอบอุ่น) อย่างไรก็ตามคุณสามารถปิดใช้งานได้โดยการตั้งค่า --use_wandb = False ในบรรทัดคำสั่ง
ฉันคาดหวังว่าผู้ใช้ได้ดาวน์โหลดชุดข้อมูลโดยเขา/ตัวเธอเองแล้ว
ในการเรียกใช้การทดลองทุกสิ่งที่คุณต้องการคือการใช้คำสั่ง python3 main.py ตามด้วยอาร์กิวเมนต์บางอย่างที่ส่งไปยังบรรทัดคำสั่งเพื่อระบุการตั้งค่า พารามิเตอร์บังคับคือ:
--data_path : เส้นทางไปยังโฟลเดอร์ที่มีชุดข้อมูล--dataset_name : ชุดข้อมูลที่เลือก ณ ตอนนี้มีชุดข้อมูล 5 ชุด: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP']--method : วิธี PETL ที่เลือก รายการวิธีการ PETL ที่รองรับดังต่อไปนี้: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] โปรดตรวจสอบกระดาษอื่น ๆ เพื่อทำการทดลองด้วยความหนาแน่น/อ่อนนุ่ม--is_AST : หากตั้งค่าเป็นจริงจะใช้โมเดลที่ผ่านการฝึกอบรมล่วงหน้า AST หากตั้งค่าเป็นเท็จจะใช้โมเดล WAV2VEC 2.0 ที่ผ่านการฝึกอบรมมาก่อนmain.py สำหรับคำอธิบายโดยละเอียดhparams/train.yaml ค่าปัจจุบันสอดคล้องกับค่าที่เราใช้สำหรับการทดลองของเราและที่นำไปสู่ผลลัพธ์ที่ดีที่สุดแต่ละวิธี PETL มาพร้อมกับพารามิเตอร์เฉพาะบางอย่าง เราให้คำอธิบายสั้น ๆ ด้านล่าง โปรดทราบว่าที่นี่เราหลีกเลี่ยงการรวมการอ้างอิงเพื่อความกะทัดรัดโปรดดูเอกสาร
reduction_rate_adapter -> มันเป็นกฎของคอขวดสลัวของโมดูลอะแดปเตอร์ (เช่นถ้า D คือมิติที่ซ่อนอยู่และ RR คืออัตราการลดลงจากนั้นอะแดปเตอร์คือ D /RR); seq_or_par -> ว่าจะแทรกอะแดปเตอร์ขนานหรือตามลำดับ; adapter_type -> การกำหนดค่า pfeiffer หรือ houlsby; adapter_block -> คอขวดหรือ conformer (การออกแบบอะแดปเตอร์ที่เราเสนอ); apply_residual -> ไม่ว่าจะใช้การเชื่อมต่อที่เหลือหรือไม่ ตามที่รายงานไว้ในกระดาษอะแดปเตอร์คู่ขนานควรจ่ายด้วยสารตกค้างในขณะที่อะแดปเตอร์ตามลำดับประโยชน์จากส่วนที่เหลือprompt_len_prompt > จำนวนพรอมต์ที่จะใช้; is_deep_prompt > ตั้งค่าเป็น True หากคุณต้องการเปิดใช้งาน การปรับแต่งแบบพรอมต์ลึก (DPT) มิฉะนั้น การปรับจูนตื้น (SPT); drop_prompt -> อัตราการออกกลางคันสำหรับพรอมต์ ในการทดลองของเราเราตั้งค่าเป็น 0. .reduction_rate_lora -> โปรดดู reduction_rate_adapter ; alpha_lora -> The Lora_alpha ตามที่กำหนดไว้ในกระดาษต้นฉบับ สิ่งนี้ใช้สำหรับการปรับขนาด (เช่น s = alpha_lora/rr)ตัวอย่างเช่นสมมติว่าเราต้องการทดสอบอะแดปเตอร์ด้วย Configuration Conformer, Parallel, Pfeiffer, RR = 64 และทดสอบในชุดข้อมูล FSC สำหรับโมเดล AST จากนั้นคำสั่งที่จะเรียกใช้คือ:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' หากคุณต้องการเรียกใช้การทดลองการเรียนรู้แบบไม่กี่ครั้งคุณเพียงแค่ตั้งค่าสถานะ --is_few_shot_exp เป็น True และระบุ # ของตัวอย่างต่อคลาส --few_shot_samples
ได้โปรดติดต่อฉันที่: Umbertocappellazzo [ที่] Gmail [dot] com สำหรับคำถามใด ๆ
เรารับทราบการสนับสนุนของ Digital Research Alliance of Canada (AllianCeCan.ca)
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti
กระดาษได้รับการยอมรับที่ Interspeech 2024 มันตรวจสอบการใช้ ส่วนผสมของผู้เชี่ยวชาญ (MOE) สำหรับการปรับแต่งอย่างมีประสิทธิภาพของ AST โดยเฉพาะเราปรับวิธี Soft MOE ล่าสุดให้เข้ากับการตั้งค่าที่มีประสิทธิภาพพารามิเตอร์ของเราซึ่งผู้เชี่ยวชาญแต่ละคนจะแสดงด้วยโมดูลอะแดปเตอร์ เราเรียกมันว่า Soft-Moa (ส่วนผสมที่อ่อนนุ่มของอะแดปเตอร์) Soft-Moa บรรลุความเท่าเทียมกันของประสิทธิภาพด้วยความหนาแน่น (Dense-Moa) ในขณะที่ลดต้นทุนการคำนวณ ยิ่งไปกว่านั้นยังแสดงให้เห็นถึงประสิทธิภาพที่เหนือกว่าอะแดปเตอร์เดี่ยวแบบดั้งเดิม
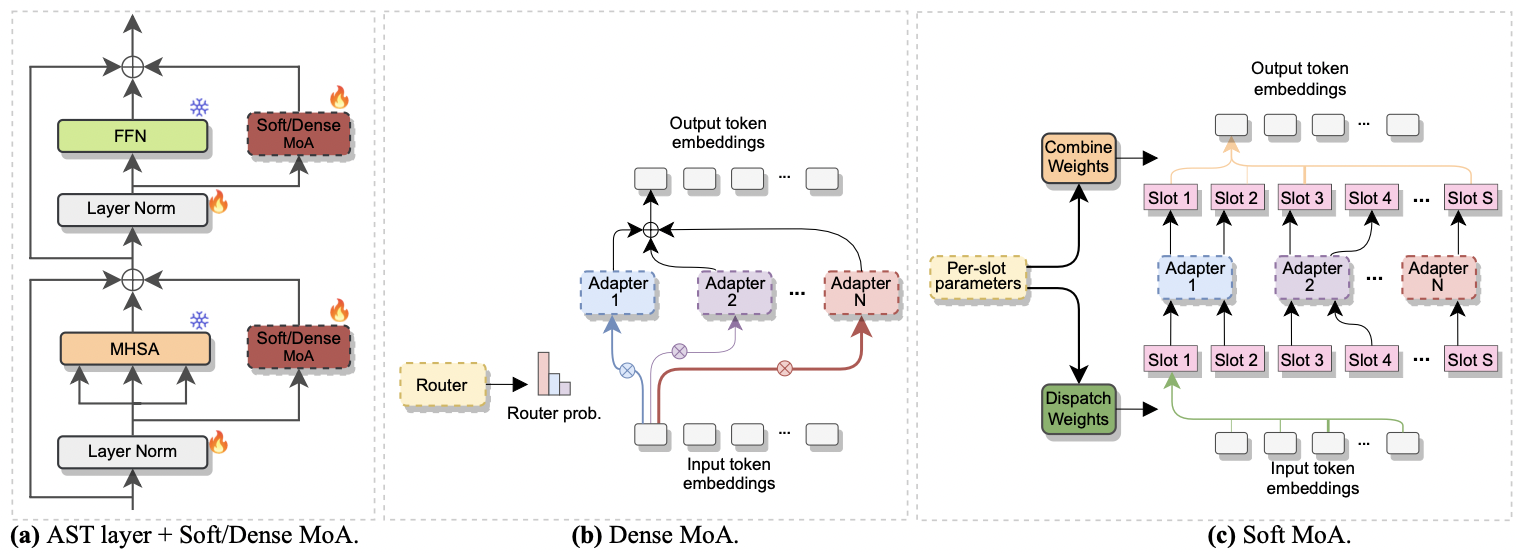 |
|---|
| a) การแทรกอะแดปเตอร์ลงในแต่ละชั้น AST b) Dense-Moa C) Soft-Moa |
การทดลองกับ MOA ที่หนาแน่นและอ่อนนุ่มเป็นเรื่องง่าย เราทำตามขั้นตอนเดียวกับที่เราใช้สำหรับกระดาษ [1] เราเพียงแค่ต้องตั้งค่าพารามิเตอร์ --method เป็น Dense-MoA หรือ Soft-MoA และระบุพารามิเตอร์ Ad-Hoc บางอย่าง:
--reduction_rate_moa : สำหรับวิธีการ PETL อื่น ๆ เราจำเป็นต้องระบุอัตราการลดลงสำหรับผู้เชี่ยวชาญอะแดปเตอร์แต่ละคน ยิ่งอัตราการลดลงก็ยิ่งมีขนาดเล็กลง--adapter_type_moa : การกำหนดค่า PFEIFFER หรือ HOULSBY--location_moa : ไม่ว่าจะใช้เลเยอร์ MOA ที่อ่อนนุ่ม/หนาแน่นขนานกับบล็อก MHSA หรือ FFN ถ้า -ADAPTER_TYPE_MOA == HOULSBY, MHSA และ FFN ได้รับการคัดเลือก Auomatically--adapter_module_moa : ประเภทของอะแดปเตอร์ เราสนับสนุน คอขวด และ convass ณ ตอนนี้--num_adapters : มีกี่อะแดปเตอร์ที่ใช้สำหรับแต่ละชั้น SOFT/หนาแน่น MOA ในการทดลองของเราค่านี้อยู่ระหว่าง 2 ถึง 15--num_slots : จำนวนช่องที่ใช้ใน Soft-MoA โดยปกติแล้วจะถูกตั้งค่าเป็น 1 หรือ 2 [ NB : ใช้ใน Soft-Moa เท่านั้น]--normalize : ไม่ว่า L2 จะทำให้เวกเตอร์อินพุตและเมทริกซ์ PHI เป็นปกติตามที่เสนอในกระดาษ Soft MOE ดั้งเดิม (ดูหัวข้อ 2.3, "Normalization") ตามที่ระบุไว้ในกระดาษการดำเนินการปกติมีผลกระทบเพียงเล็กน้อยหากขนาดที่ซ่อนอยู่ของแบบจำลองมีขนาดเล็กเหมือนในกรณีของเรา (เช่น 768) ดังนั้นเราจึงไม่ได้ใช้การทำให้เป็นมาตรฐาน [ NB : ใช้ใน Soft-Moa เท่านั้น]ตัวอย่างเช่นสมมติว่าเราต้องการทดสอบ Soft-MoA บนชุดข้อมูล FSC นอกจากนี้เรายังเลือกที่จะรวมเลเยอร์ Soft-MoA เฉพาะในชั้น MHSA และเราใช้อะแดปเตอร์ Botteneck 7 ตัว จากนั้นคำสั่งที่จะเรียกใช้คือ:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

